A scalable, commodity data center network architecture
💡 Meta Data
Title | A scalable, commodity data center network architecture |
|---|---|
Journal | ACM SIGCOMM Computer Communication Review |
Authors | Mohammad Al-Fares; Alexander Loukissas; Amin Vahdat |
Pub. date | 八月 17, 2008 |
期刊标签 | |
DOI | |
附件 | Al-Fares et al_2008_A scalable, commodity data center network architecture.pdf |
📜 研究背景 & 基础 & 目的
“Clusters consisting of tens of thousands of PCs are not unheard of in the largest “institutions and thousand-node clusters are increasingly common in universities, research labs, and companies.” (Al-Fares 等, 2008, p. 63) 大型机构中由数万台PC组成的集群并不少见,在大学,研究实验室和公司中,千节点集群越来越普遍。这些集群用于各种目的,包括科学计算,数据分析和机器学习。它们提供了大量的计算能力,可用于解决复杂问题。
DC Communications
M2M communications:M2M communications,即机器对机器通信,是指机器与机器之间进行的数据通信。M2M通信的目的通常是实现机器之间的自动化控制和数据交换。
“Today, the principle bottleneck in large-scale clusters is often inter-node communication bandwidth.” (Al-Fares 等, 2008, p. 63) 如今,大规模集群的主要瓶颈往往是节点间的通信带宽。
“For example, MapReduce [12] must perform significant data shuffling to transport the output of its map phase before proceeding with its reduce phase. Applications running on clusterbased file systems [18, 28, 13, 26] often require remote-node access before proceeding with their I/O operations.” (Al-Fares 等, 2008, p. 63) 例如,MapReduce必须先进行大量的数据重组,以传输其映射阶段的输出,然后再进入还原阶段。在基于集群的文件系统上运行的应用程序在进行 I/O 操作前,通常需要远程节点访问。
“A query to a web search engine often requires parallel communication with every node in the cluster hosting the inverted index to return the most relevant results [7].” (Al-Fares 等, 2008, p. 63) 🔤对网络搜索引擎的查询往往需要与承载倒排索引的集群中的每个节点进行并行通信,以返回最相关的结果[7]。🔤
“Internet services increasingly employ service oriented architectures [13], where the retrieval of a single web page can require coordination and communication with literally hundreds of individual sub-services running on remote nodes.” (Al-Fares 等, 2008, p. 63) 🔤互联网服务越来越多地采用面向服务的架构[13],在这种架构下,检索一个网页可能需要与远程节点上运行的数百个单独的子服务进行协调和通信。🔤
Two approaches for DC network
“There are two high-level choices for building the communication fabric for large-scale clusters.”
approach1
“One option leverages specialized hardware and communication protocols, such as InfiniBand [2] or Myrinet [6].” (Al-Fares 等, 2008, p. 63) 🔤一种方法是利用专用硬件和通信协议,如 InfiniBand [2] 或 Myrinet [6]。🔤
缺点:
“they do not leverage commodity parts (and are hence more expensive)” (Al-Fares 等, 2008, p. 63)它们不使用通用零件(因此更昂贵)
“not natively compatible with TCP/IP applications.” (Al-Fares 等, 2008, p. 63) 🔤与 TCP/IP 应用程序不兼容。🔤
approach2
“The second choice leverages commodity Ethernet switches and routers to interconnect cluster machines.” (Al-Fares 等, 2008, p. 63) 🔤第二种选择是利用商品以太网交换机和路由器实现集群机器之间的互联。🔤
优点:
“This approach supports a familiar management infrastructure along with unmodified applications, operating systems, and hardware.” (Al-Fares 等, 2008, p. 63) 🔤这种方法支持熟悉的管理基础设施以及未经修改的应用程序、操作系统和硬件。🔤
Desired Properties for a DC Network Architecture直流网络架构的理想特性
“Scalable interconnection bandwidth: it should be possible for an arbitrary host in the data center to communicate with any other host in the network at the full bandwidth of its local network interface.” (Al-Fares 等, 2008, p. 64) 🔤可扩展的互联带宽:数据中心的任意一台主机都应能以其本地网络接口的全部带宽与网络中的任何其他主机进行通信。🔤
- Scalable interconnection bandwidth: an arbitrary host can communicate with any other host at the full bandwidth of its local network interface (non-blocking).数据中心网络应该能够支持任意两个主机之间的全带宽通信,并且不会发生通信阻塞。这句话是数据中心网络设计的一个重要目标。
“Economies of scale: just as commodity personal computers became the basis for large-scale computing environments, we hope to leverage the same economies of scale to make cheap off-the-shelf Ethernet switches the basis for largescale data center networks.” (Al-Fares 等, 2008, p. 64) 🔤规模经济:正如商品化个人电脑成为大规模计算环境的基础一样,我们希望利用同样的规模经济,使廉价的现成以太网交换机成为大规模数据中心网络的基础。🔤
Economies of scale: make cheap off-the-shelf Ethernet switches the basis for large scale data center networks
规模经济使廉价的现成以太网交换机成为大型数据中心网络的基础
这句话的意思是,由于规模经济效应,廉价的现成以太网交换机在大型数据中心网络中得到了广泛应用。
规模经济效应是指企业随着生产规模的扩大,单位产品的成本会降低的现象。在数据中心网络中,由于大型数据中心需要大量的以太网交换机,因此规模经济效应可以显著降低以太网交换机的成本。
“Backward compatibility: the entire system should be backward compatible with hosts running Ethernet and IP. That is, existing data centers, which almost universally leverage commodity Ethernet and run IP, should be able to take advantage of the new interconnect architecture with no modifications.” (Al-Fares 等, 2008, p. 64) 🔤向后兼容性:整个系统应向后兼容运行以太网和 IP 的主机。也就是说,几乎普遍利用商品以太网和运行 IP 的现有数据中心应能利用新的互连架构,而无需进行任何修改。🔤
Backward compatibility: the entire system should be backward compatible with hosts running Ethernet and IP.
向后兼容:整个系统应与运行以太网和 IP 的主机向后兼容
这句话强调了系统需要与现有以太网和 IP 网络无缝集成的重要性。这确保了新主机和设备可以与遗留设备无缝通信,防止中断并确保平稳过渡到新系统。
Conventional Data Center Network Topologies 传统数据中心网络拓扑结构
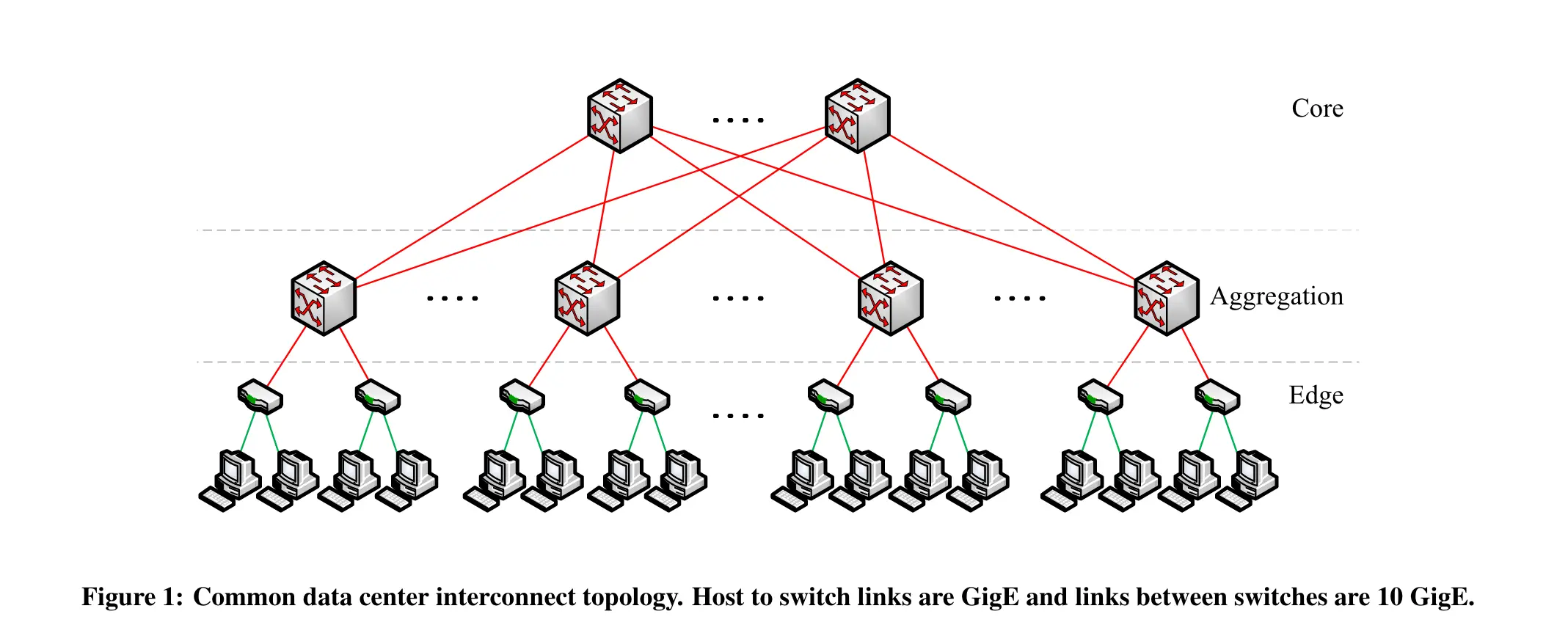
(Al-Fares 等, 2008, p. 65)
“Typical architectures today consist of either two- or three-level trees of switches or routers. A three-tiered design (see Figure 1) has a core tier in the root of the tree, an aggregation tier in the middle and an edge tier at the leaves of the tree.” (Al-Fares 等, 2008, p. 64) 🔤目前,典型的架构由两层或三层交换机或路由器树组成。三层设计(见图 1)的核心层位于树的根部,汇聚层位于树的中部,边缘层位于树的叶部。🔤
- 核心层(Core Tier): 核心层是网络的顶层,负责处理整个数据中心内的高级路由和转发。它通常拥有大量的高速连接,以支持大规模的数据传输。
- 聚合层(Aggregation Tier): 聚合层位于核心层和边缘层之间,负责将来自边缘层的流量进行汇总和转发。这一层的存在有助于提高网络的可扩展性和性能。
- 边缘层(Edge Tier): 边缘层是网络结构的底层,位于树的末端,通常与终端设备直接相连。它处理与数据中心内部设备的直接通信,如服务器、存储设备等。
“We assume the use of two types of switches, which represent the current high-end in both port density and bandwidth. The first, used at the edge of the tree, is a 48-port GigE switch, with four 10 GigE uplinks. For higher levels of a communication hierarchy, we consider 128-port 10 GigE switches. Both types of switches allow all directly connected hosts to communicate with one another at the full speed of their network interface.” (Al-Fares 等, 2008, p. 64) 🔤我们假设使用两种类型的交换机,它们在端口密度和带宽方面都代表了当前的高端水平。第一种是用于树边缘的 48 端口千兆以太网交换机,带有四个万兆以太网上行链路。对于通信层次结构的较高层次,我们考虑使用 128 端口万兆以太网交换机。这两种类型的交换机都允许所有直接连接的主机以其网络接口的全速相互通信。🔤
Two types of switches:
48-port GigE switch, with four 10 GigE uplinks, used at the edge of the tree
- 这是一种用于数据中心网络结构边缘的交换机类型。
- 具有48个千兆以太网端口,这些端口用于连接直接的终端设备(主机)。
- 同时,它还有四个10千兆以太网的上行链路,连接到更高层次的网络结构,用于传输数据到聚合层。
128-port 10 GigE switch for higher levels of a communication hierarchy
- 这是另一种用于通信层次的较高级别的交换机类型。
- 具有128个10千兆以太网端口,用于连接到。更多的底层交换机或直接连接到边缘层的终端设备
- 这种交换机具有更大的端口密度和更高的带宽,适用于需要处理更多数据流量的网络层次。
无论是48端口的千兆以太网交换机还是128端口的10千兆以太网交换机,它们都能够让直接连接的设备之间以最大速度进行通信。
“Oversubscription”
过度订阅是一种设计数据中心网络的策略,目的是降低总体设计成本。
“We define the term oversubscription to be the ratio of the worst-case achievable aggregate bandwidth among the end hosts to the total bisection bandwidth of a particular communication topology.” (Al-Fares 等, 2008, p. 64) 🔤我们将 “超量订购 “定义为终端主机之间最坏情况下可实现的总带宽与特定通信拓扑的总带宽之比。🔤
文中定义过度订阅为终端主机之间最坏情况下可实现的总带宽与特定通信拓扑的总带宽之比
“An oversubscription of 1:1 indicates that all hosts may potentially communicate with arbitrary other hosts at the full bandwidth of their network interface (e.g., 1 Gb/s for commodity Ethernet designs).” (Al-Fares 等, 2008, p. 64)
1:1的过度订阅表示所有主机可以潜在地以它们网络接口的完整带宽进行通信,例如,对于通用以太网设计,即1 Gb/s。
“An oversubscription value of 5:1 means that only 20% of available host bandwidth is available for some communication patterns. Typical designs are oversubscribed by a factor of 2.5:1 (400 Mbps) to 8:1 (125 Mbps) [1].” (Al-Fares 等, 2008, p. 64) 🔤5:1 的超额订购值意味着只有 20% 的可用主机带宽可用于某些通信模式。典型设计的超额订购系数为 2.5:1 (400 Mbps)至 8:1(125 Mbps)[1]。🔤
虽然 1 Gb/s 以太网的数据中心可以实现 1:1 的超量订阅,但这种设计的成本通常过高。
Multi-path Routing
“Delivering full bandwidth between arbitrary hosts in larger clusters requires a “multi-rooted” tree with multiple core switches (see Figure 1).” (Al-Fares 等, 2008, p. 64) 🔤要在大型集群中的任意主机之间提供全带宽,就需要一个具有多个核心交换机的 “多根 “树(见图 1)。🔤
Multi-Rooted Tree (多根树):
这表示网络拓扑中存在多个核心交换机,这些交换机在树的根部,以支持更多的路径选择。
“To take advantage of multiple paths, ECMP performs static load splitting among flows.” (Al-Fares 等, 2008, p. 64) 🔤为了利用多条路径,ECMP 在流量之间执行静态负载分流。🔤
ECMP (Equal-Cost Multi-Path):
ECMP 是一种多路径路由技术,旨在平均分担等代价路径上的流量。
它允许在多个等代价路径上进行流量的分发,以提高网络的利用率。
ECMP 的实现对于路径的多样性有一定的限制,通常限制在 8-16 条路径之间。
这可能不足以满足较大数据中心所需的高二分带宽,因为这限制了网络在不同路径上进行流量分发的灵活性。
使用 ECMP 时,考虑的路径数量成倍增加,导致路由表的条目数量也成倍增加。
这会增加系统的成本,并可能导致查找延迟的增加。
Cost
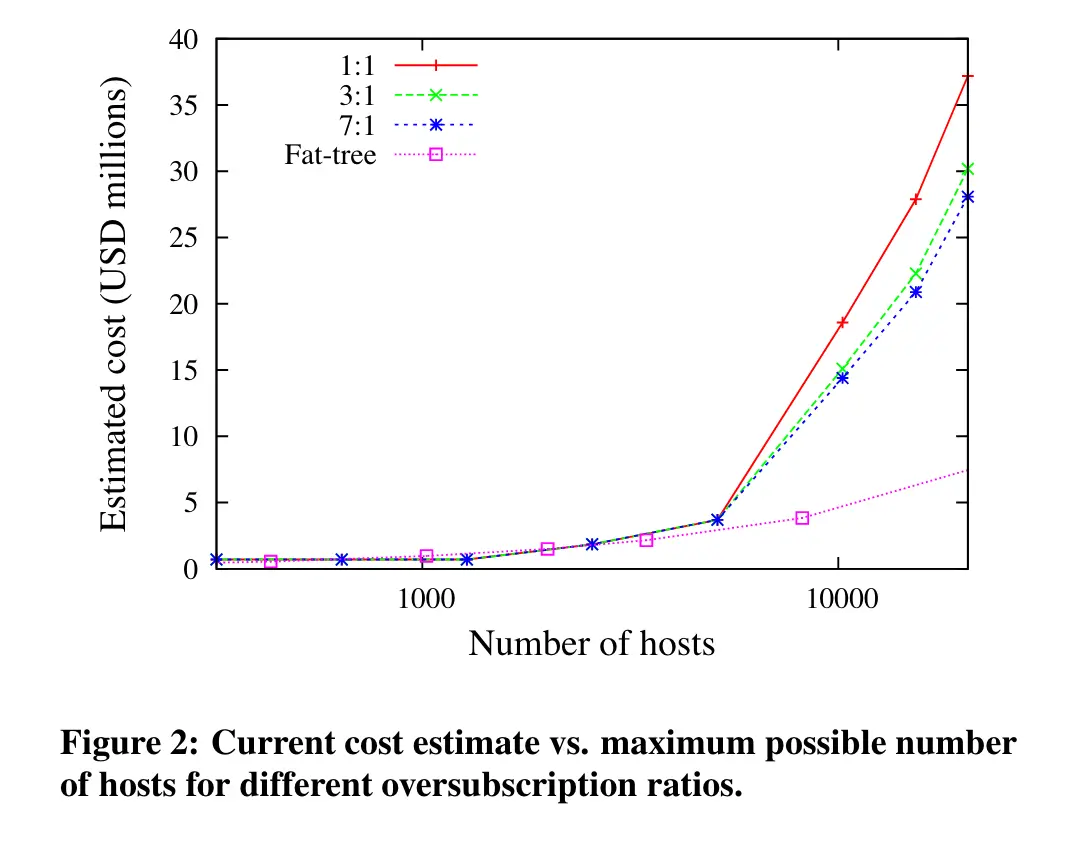
(Al-Fares 等, 2008, p. 65)
维持一个固定的oversubscription,cost会随规模急剧增加。
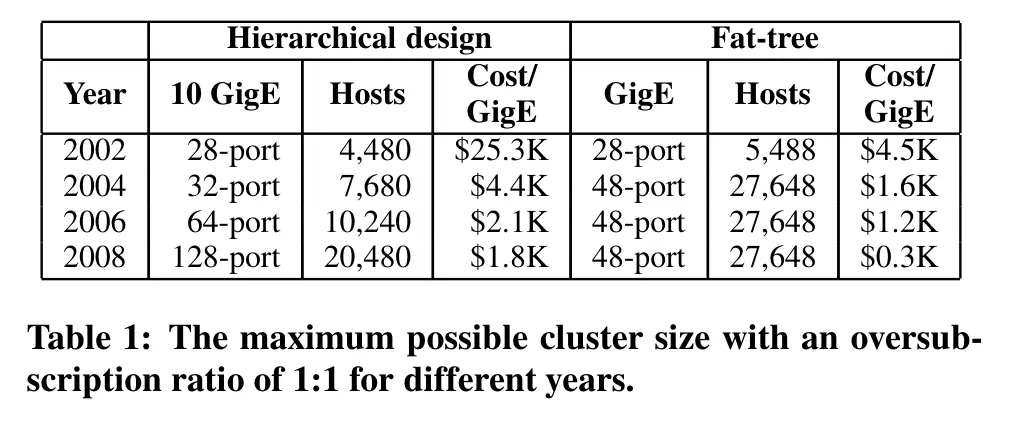 (Al-Fares 等, 2008, p. 65)
(Al-Fares 等, 2008, p. 65)
大型集群中实现高带宽水平的现有技术会产生显著的成本,而基于 fat-tree 架构的集群互连在适度的成本下具有显著的潜力。
使用最大的10千兆以太网(10 GigE)和通用千兆以太网(GigE)交换机构建具有1:1过度订阅的数据中心,以及该集群最多可支持27,648个主机
📊 研究内容
Fat tree based solution
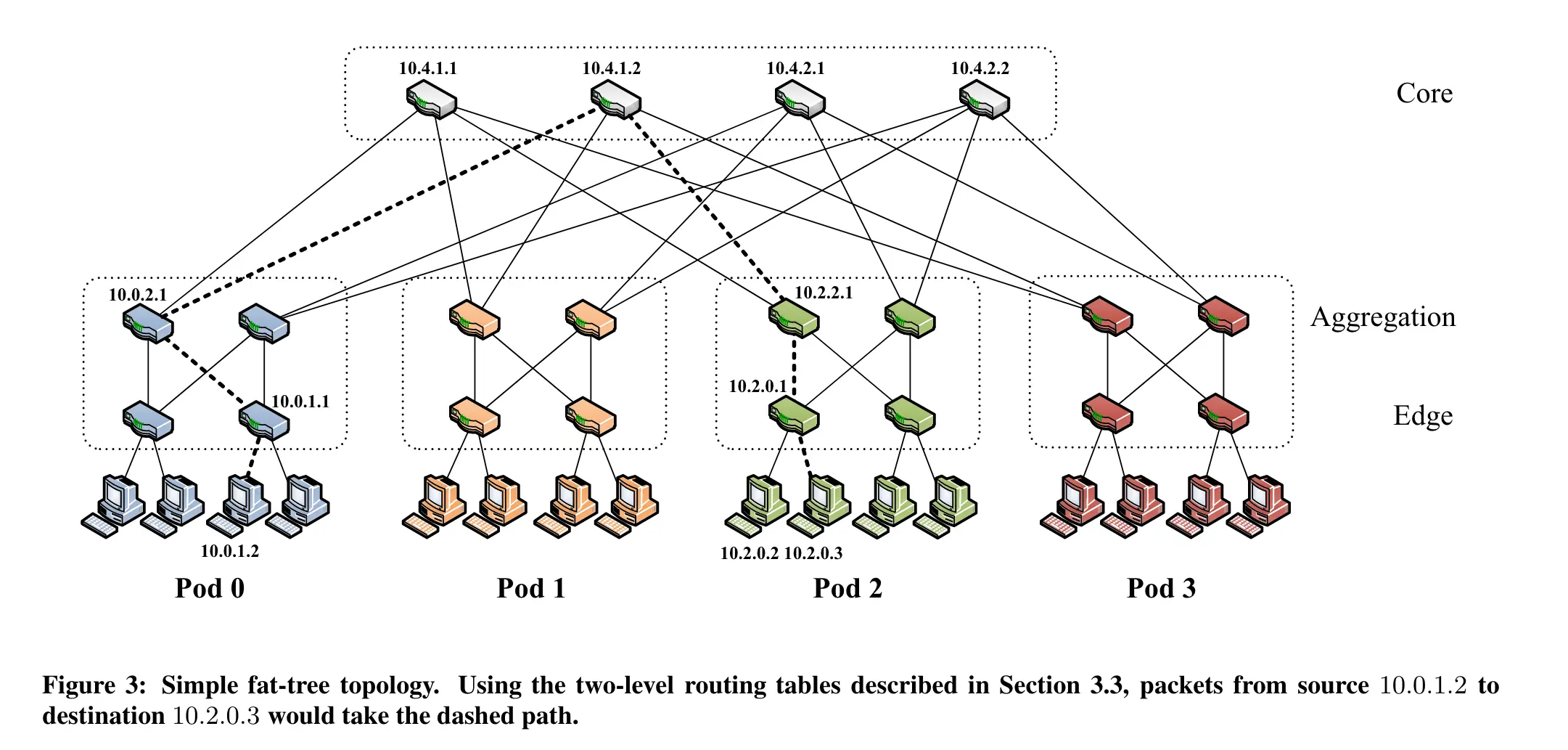
有k个pod,每个pod包含两层k/2个交换机。这样的结构使得网络具有层次化的特点。
在底层,每个k端口的交换机直接连接到k/2个主机。这确保了较低层次的直接主机连接。
剩余的k/2个端口连接到层次结构中聚合层的k/2个端口。
在fattree拓扑中,存在**(k/2)^2**个k端口的核心交换机。每个核心交换机有k个端口,其中每个端口连接到k个pod之一。
考虑一个fattree拓扑,其中有k个pod,每个pod有k/2个交换机,每个交换机有k个端口。
任意两个主机可能位于不同的pod,因此可以通过连接这两个pod的多条路径进行通信。对于每个pod,存在(k/2)个交换机,因此在每个pod内也有(k/2)条不同的路径。因此,总的最短路径数为(k/2)²。
每个核心交换机的第i个端口与第i个pod连接。这样的连接模式确保了每个pod都与所有核心交换机直接相连。
在每个pod的聚合层交换机上,与核心交换机的连接是以(k/2)的步幅进行的,即相邻的聚合层端口与核心交换机的连接是在(k/2)步幅上的。
在这篇论文中,重点关注k值最多为48的设计。
地址
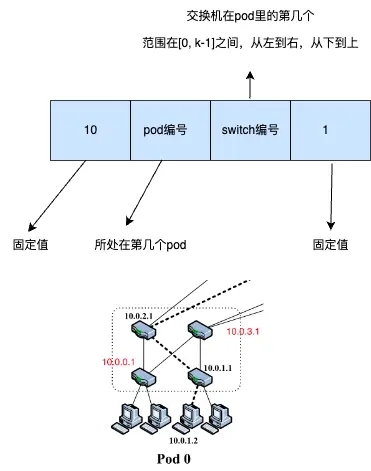
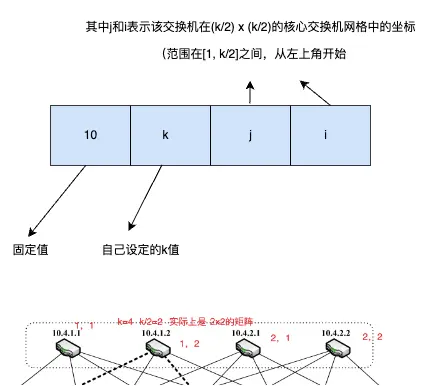
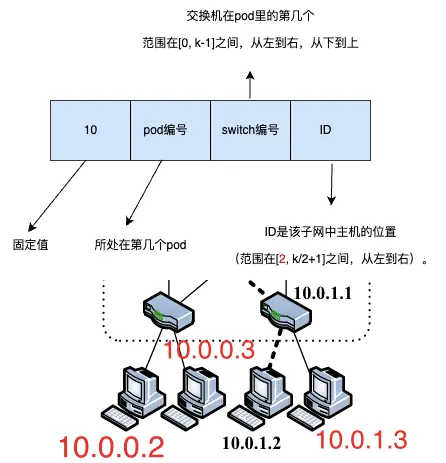
“We allocate all the IP addresses in the network within the private 10.0.0.0/8 block. We follow the familiar quad-dotted form with the following conditions: The pod switches are given addresses of the form 10.pod.switch.1,wherepod denotes the pod number (in [0,k − 1]), and switch denotes the position of that switch in the pod (in [0,k−1], starting from left to right, bottom to top). We give core switches addresses of the form 10.k.j.i,wherej and i denote that switch’s coordinates in the (k/2)2 core switch grid (each in [1, (k/2)], starting from top-left). The address of a host follows from the pod switch it is connected to; hosts have addresses of the form: 10.pod.switch.ID,where ID is the host’s position in that subnet (in [2,k/2+1], starting from left to right). Therefore, each lower-level switch is responsible for a /24 subnet of k/2 hosts (for k<256). Figure 3 shows examples of this addressing scheme for a fat-tree corresponding to k =4.Even though this is relatively wasteful use of the available address space, it simplifies building the routing tables, as seen below. Nonetheless, this scheme scales up to 4.2M hosts.” (Al-Fares 等, 2008, p. 66)
在网络中,我们将所有的IP地址分配在私有的10.0.0.0/8地址块中。我们按熟悉的四点形式进行分配,具体如下:pod交换机的地址形式为10.pod.switch.1,其中pod表示pod的编号(范围在[0, k-1]之间),switch表示该pod中交换机的位置(范围在[0, k-1]之间,从左到右,从下到上)。核心交换机的地址形式为10.k.j.i,其中j和i表示该交换机在(k/2) x (k/2)的核心交换机网格中的坐标(范围在[1, k/2]之间,从左上角开始)。主机的地址由其所连接的pod交换机产生;主机的地址形式为10.pod.switch.ID,其中ID是该子网中主机的位置(范围在[2, k/2+1]之间,从左到右)。
- 交换机地址的分配
- 核心交换机的地址
- 主机的地址
算法

z 在[k/2,k-1]的原因:pod里面的上层交换机
最里面的第一个循环的意思是:给pod里面的上层交换机按顺序添加前缀
第二个addprefix的意思是增加一个0.0.0.0/0的默认前缀
第二个循环的意思是给主机添加特定前缀
“The reason for the modulo shift in the outgoing port is to avoid traffic from different lower-layer switches addressed to a host with the same host ID going to the same upper-layer switch.” (Al-Fares 等, 2008, p. 68) 🔤出站端口之所以要进行模数转换,是为了避免从不同下层交换机发送到具有相同主机 ID 的主机的流量进入同一上层交换机。🔤
生产核心交换机路由

(Al-Fares 等, 2008, p. 68)
就是为每个核心交换机按顺序分配一个10.x.0.0/16的路由
例子
从10.0.1.2到10.2.0.3
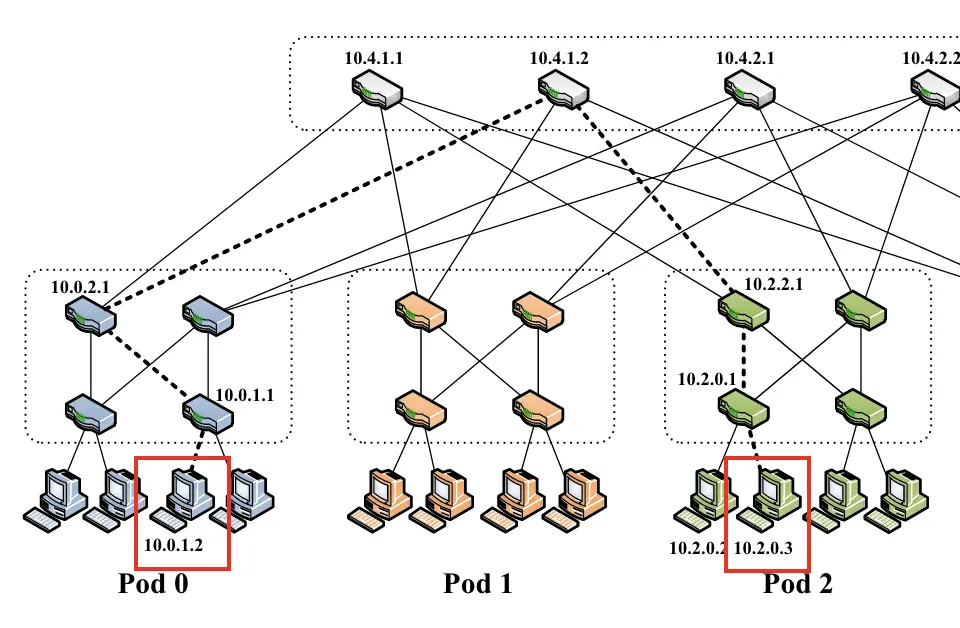
源主机(10.0.1.1)的网关交换机只会匹配带有 /0 一级前缀的数据包,因此会根据该前缀的二级表中的主机 ID 字节转发数据包。在该表中,数据包匹配 0.0.0.3/8 后缀,指向端口 2 和交换机 10.0.2.1(i=3,z=1)
- 端口2:(3-2+1)mod(4/2+4/2)=2
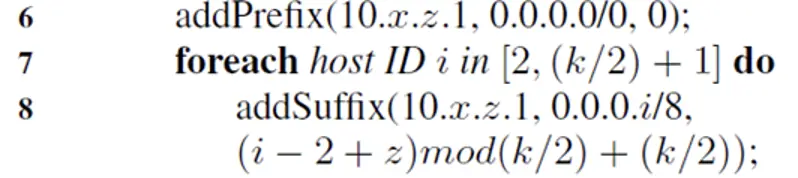
- 为什么指向10.0.2.1?因为10.0.1.1到端口0和端口1指向向下的俩host,端口2指向10.0.2.1(从下到上,从左到右)
- 端口2:(3-2+1)mod(4/2+4/2)=2
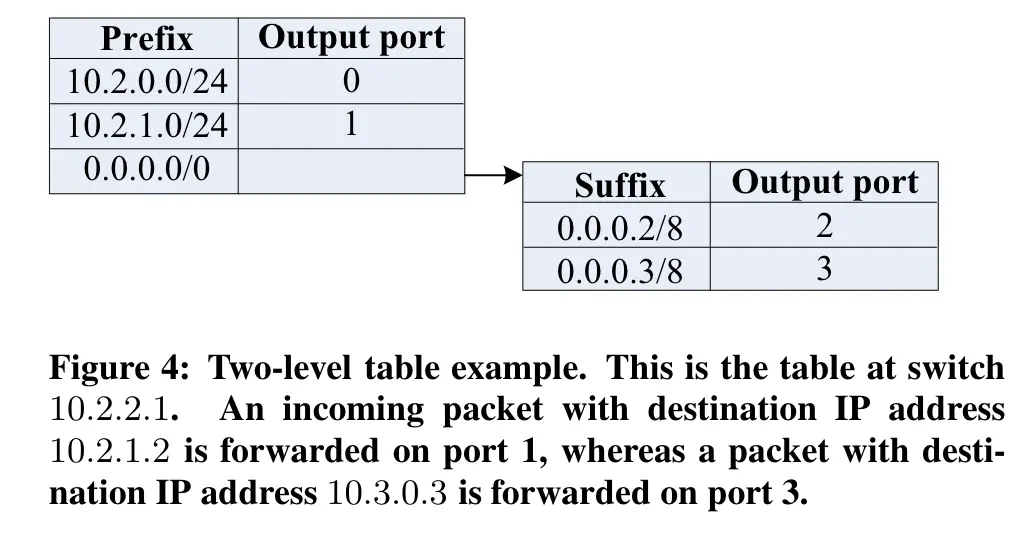
“Switch 10.0.2.1 also follows the same steps and forwards on port 3, connected to core switch 10.4.1.1” (Al-Fares 等, 2008, p. 68) 🔤交换机 10.0.2.1 也遵循相同步骤,在连接到核心交换机 10.4.1.2 的端口 3 上进行转发🔤
- i=3,z=2,(3-2+2)mod(2+2)=3
因为目的地址在pod2,核心交换机10.4.1.2匹配10.2.0.0/16,端口2,指向10.2.2.1
10.2.2.1匹配到10.2.0.0/24,指向10.2.0.1
🚩 研究结论
📌 感想 & 疑问
What is the datacenter network? What is the desired property of the datacenter network?
根据提供的信息,对于数据中心网络,论文[1]提出了一种基于可扩展性和通用性的架构。数据中心网络旨在支持大规模集群之间的通信,并具有以下期望特性:
1. 可扩展性:数据中心网络需要能够支持数以千计甚至数以百万计的节点,并提供良好的吞吐量和性能。这是因为数据中心通常由大量服务器和计算资源组成。
2. 低延迟:数据中心网络需要具备低延迟的特性,以确保快速和高效的数据传输。这对于网络中的实时应用和大数据处理等任务至关重要。
3. 高带宽:数据中心网络需要具有高带宽,以处理大量数据的传输需求。这是因为数据中心中经常需要在节点之间进行大规模的数据传输和通信。
What is the traditional three-tier topology for the datacenter, its limitations?
传统的数据中心网络采用三层架构,包括核心层、聚合层和接入层。核心层处理数据中心内部的高级路由功能,聚合层用于连接核心层和接入层,并提供流量聚合和负载均衡。接入层则负责连接终端设备和聚合层。然而,传统的三层架构在规模扩大时会面临一些限制,如带宽瓶颈和复杂的缆线布局,导致整体性能和可扩展性受限。
How Fat-tree differs from the traditional design? In
Topology
Fat-tree 是一种分层的树形结构,它通过增加接近根部的节点的带宽来解决网络瓶颈问题。在这种结构中,越靠近根部的节点(比如交换机)拥有更高的处理能力和更大的带宽。这种设计使得网络能够更好地扩展,并支持更多的终端节点。
Addressing
IP 地址范围:
- 所有的 IP 地址都分配在私有的
10.0.0.0/8地址块内。
- 所有的 IP 地址都分配在私有的
Pod 交换机地址:
- 每个 Pod 交换机的 IP 地址格式为
10.pod.switch.1。 - 其中
pod是 Pod 编号,范围是[0, k-1]。 switch是该交换机在 Pod 内的位置,范围也是[0, k-1],按照从左到右、从下到上的顺序。
- 每个 Pod 交换机的 IP 地址格式为
核心交换机地址:
- 核心交换机的 IP 地址格式为
10.k.j.i。 j和i是交换机在核心交换机网格中的坐标,范围是[1, k/2],从左上角开始。
- 核心交换机的 IP 地址格式为
主机地址:
- 连接到 Pod 交换机的主机的 IP 地址格式为
10.pod.switch.ID。 ID是主机在子网中的位置,范围是[2, k/2+1],按照从左到右的顺序。
- 连接到 Pod 交换机的主机的 IP 地址格式为
子网管理:
- 每个下级交换机管理一个包含
k/2台主机的/24子网(当k小于 256 时)。
- 每个下级交换机管理一个包含
Routing algorithm
源 $ℎ1h1$ 到目的地 $ℎ2h2$ 的路由路径的例子。这个例子中,源地址是 10.0.1.2,目的地地址是 10.2.0.3。以下是每一跳的详细描述以及如何确定输出端口:
第一跳 - 网关交换机:
- 源主机的网关交换机(10.0.1.1)首先匹配到 /0 第一级前缀,然后根据该前缀的二级表中的主机 ID 字节来转发数据包。在这个表中,数据包匹配到 0.0.0.3/8 后缀,指向端口 2 和交换机 10.0.2.1 (页面 6)。
第二跳 - Pod 交换机:
- 交换机 10.0.2.1 也执行相同的步骤,并通过连接到核心交换机 10.4.1.1 的端口 3 转发数据包。
第三跳 - 核心交换机:
- 核心交换机匹配数据包到一个终止的 10.2.0.0/16 前缀,这个前缀指向目的地 Pod 2。
如果目的地地址变成 10.2.0.2,路由路径将会有所不同。以下是基于文档中的两级路由表和网络拓扑的详细解释:
第一跳 - 网关交换机:
- 源主机的网关交换机(假设为 10.0.1.1)首先匹配到 /0 第一级前缀。然后,它会根据该前缀的二级表中的主机 ID 字节来转发数据包。在这个表中,数据包匹配到的后缀将会是 0.0.0.2/8,这将决定数据包应该转发到的端口和下一个交换机。
第二跳 - Pod 交换机:
- 第二个交换机(例如 10.0.2.1)也会执行类似的步骤,根据其路由表中的匹配项来决定将数据包转发到哪个端口,以及下一个目标核心交换机。
第三跳 - 核心交换机:
- 到达核心交换机(例如 10.4.1.1)后,它会匹配数据包到一个终止的 10.2.0.0/16 前缀。这个前缀指向目的地 Pod 2。核心交换机将根据其路由表决定将数据包转发到哪个 Pod 交换机。
最后一跳 - 到达目的地:
- 在 Pod 2 内,相应的交换机将根据其路由表来决定如何将数据包最终转发到目的地地址 10.2.0.2 的主机。
问题
假设 Fattree 用10.0.0.0/8的地址空间进行编址,且不考虑单个交换机大小的物理限制。
1. 该地址空间所能支持的最大 Fattree 有多少个pod,即K=
首先,10.0.0.0/8的地址空间有
个IP地址,其中一个地址用于网络标识,一个地址用于广播,剩下的地址用于主机。
k=406
2.以下哪个数字是一个完整的Fattree 可能支持的主机数()
A. 4194304
B. 2097152
C.3906250
D. 2916000
- 对于A选项(4194304),我们需要解方程 $\frac{k^3}{4}=4194304$。
- 对于B选项(2097152),方程为 $\frac{k^3}{4}=2097152$。
- 对于C选项(3906250),方程为 $\frac{k^3}{4}=3906250$。
- 对于D选项(2916000),方程为 $\frac{k^3}{4}=2916000$。
我们可以计算每个方程来找出正确的答案。
根据计算结果:
- 对于选项A(4194304),计算得到的k值约为256,是一个合理的偶数。
- 对于选项B(2097152),计算得到的k值约为203.19,不是偶数。
- 对于选项C(3906250),计算得到的k值约为250,是一个合理的偶数。
- 对于选项D(2916000),计算得到的k值约为226.79,不是偶数。
由于k必须是偶数,因此只有选项A和C的k值符合条件。但在Fat-tree拓扑中,k通常是2的幂次方,所以最符合条件的答案是选项A(4194304),其对应的k值为256。
3. Fattree 用的是交换机连接,给每个交换机分配 IP地址的目的是
“we introduce the concept of two-level route lookups to assist with multi-path routing across the fat-tree.” (Al-Fares 等, 2008, p. 66) 🔤我们引入了两级路由查找的概念,以帮助在胖树上进行多路径路由选择。🔤
“Even though this is relatively wasteful use of the available address space, it simplifies building the routing tables, as seen below.” (Al-Fares 等, 2008, p. 66) 🔤尽管这相对浪费了可用地址空间,但却简化了路由表的构建,如下所示。🔤
Fattree使用交换机连接,并给每个交换机分配IP地址的目的是为了实现数据中心的通信和路由功能。通过给交换机分配IP地址,可以在网络中对不同的主机进行定位和识别,实现数据包的转发和数据中心网络的路由控制。这样可以保证在数据中心网络中的每个交换机都能够准确地识别和转发数据包。此外,通过对不同交换机分配不同的IP地址,还可以构建网络拓扑和路由表,实现数据中心网络的高效通信和负载均衡。
🔬 理论推导
参考
https://blog.csdn.net/baidu_20163013/article/details/110004560
https://blog.csdn.net/u012925450/article/details/108493968
https://blog.csdn.net/weixin_44639164/article/details/126950178?