前言
其实从本科开始,计网相关的课上了也有三次:第一次是大二在CQU上的,当时用的自顶向下那本书,一上来方老师就无敌催眠,不过是开卷考试,最后面向考试临时复习也拿了90+;第二次是考研的时候看的湖科大的网课,说实话这个老师动画做的很好,每个知识点好像都听懂了,但是还是没有形成成套的系统;第三次是在USTC上的高级计算机网络,上学期选这门课的时候,还是抱着一种想学东西的心态去听的,毕竟选的时候就听过这门课很硬核。遗憾的是,尝试听了一两节课后还是放弃了。机缘巧合之下,看到了cs144的lab,想给自己立一个新坑,这个学期搓出来cs144。计网的概念实在是玄乎又不好理解,或许换种方式,试试自己动手写写,顺便尝试读读英文文档(当然还是会借助一下翻译器),话不多说,cs144,启动!
前面都是一些配置相关废话,正式写代码请看[[#3.4 Writing webget]]
1 Set up GNU/Linux on your computer
文档中给出了几种环境的安装方式
- Recommended: Install the CS144 VirtualBox virtual-machine image (instructions at https://stanford.edu/class/cs144/vm howto/vm-howto-image.html).
- Use a Google Cloud virtual machine using our class’s coupon code (instructions at https://stanford.edu/class/cs144/vm howto).
- Run Ubuntu version 23.10, then install the required packages: sudo apt update && sudo apt install git cmake gdb build-essential clang \clang-tidy clang-format gcc-doc pkg-config glibc-doc tcpdump tshark
- Use another GNU/Linux distribution, but be aware that you may hit roadblocks along the way and will need to be comfortable debugging them. Your code will be tested on Ubuntu 23.10 LTS with g++ 13.2 and must compile and run properly under those conditions.
- If you have a 2020–24 MacBook (with the ARM64 M1/M2/M3 chips), VirtualBox will not successfully run. Instead, please install the UTM virtual machine software and our ARM64 virtual machine image from https://stanford.edu/class/cs144/vm howto/.
我是MAC系统所以就按第五种进行虚拟机的安装(上学期已经被折磨过一次)
- 下载UTM并进行安装(这一步没啥好介绍的)
- 下载Setting up your CS144 VM提供的ARM64 GNU/Linux virtual machine image,并导入UTM
- 启动虚拟机,初始用户和密码都是
cs144到这里,虚拟机就安装完成了,开始实验!
2 Networking by hand
这一节主要是体验一下,用图形化浏览器访问网页和在终端操作的区别。
2.1 Fetch a Web page
- 在图形化浏览器访问cs144.keithw.org/hello,可以看到下图内容

- 在虚拟机的终端输入
telnet cs144.keithw.org http,结果如下- 这个命令是用来通过Telnet协议手动模拟一个简单的HTTP请求,以连接到域名
cs144.keithw.org上提供的HTTP服务。 - telnet 是一个基于TCP/IP协议的远端登录工具,它允许用户通过网络与远程主机上的指定端口建立直接交互式连接。
- cs144.keithw.org 是要连接的目标服务器的域名。
- http 指定要连接的TCP端口号,默认情况下HTTP服务运行在80端口,但在这种情况下省略了端口号,因为
http作为参数实际上暗示telnet应连接到HTTP服务的标准端口80。 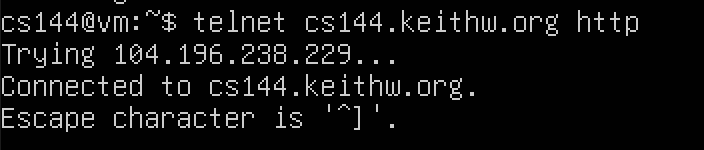
- 这个命令是用来通过Telnet协议手动模拟一个简单的HTTP请求,以连接到域名
- 当你执行这个命令后,telnet会尝试与该服务器的80端口建立连接。一旦连接成功,你可以在telnet会话中手工输入HTTP请求头和请求体来模拟浏览器与Web服务器之间的通信。
- 输入
GET /hello HTTP/1.1,回车。这是一个HTTP头部信息,告知服务器请求的目标主机名,确保服务器知道你请求的是哪个站点的资源,即使多个站点可能共享同一IP地址和端口。 - 输入
Host: cs144.keithw.org,回车。这是一个HTTP头部信息,告知服务器请求的目标主机名,确保服务器知道你请求的是哪个站点的资源。 - 输入
Connection: close,回车。这也是一个HTTP头部信息,指示服务器在完成响应后关闭TCP连接,因为在HTTP/1.1中默认采用持久连接,而这里明确要求一次请求结束后就关闭连接。 - 在输入完上述信息后,再按一次回车键,发送一个空行。在HTTP协议中,空行标志着请求头部的结束,接下来服务器将读取并处理你的请求。
- 如果一切正常,你将在telnet窗口中看到服务器发回的响应。
- 输入
2.2
略
2.3
略
3. Writing a network program using an OS stream socket
前面只是一些直观的体验,现在要真正开始编程了,在这个实验中,你将使用操作系统内置的传输控制协议支持。你需要编写一个名为“webget”的程序,创建一个TCP流套接字,连接到Web服务器,并获取一个页面。在后续的实验中,你将实现传输控制协议的另一部分,即自己实现TCP协议,将不可靠的数据报转换为可靠的字节流。
3.1 Let’s get started—fetching and building the starter code
在虚拟机的终端窗口运行
git clone https://github.com/cs144/minnow获得源代码Optional: Feel free to backup your repository to a private GitHub/GitLab/Bitbucket repository (e.g., using the instructions at https://stackoverflow.com/questions/10065526/ github-how-to-make-a-fork-of-public-repository-private), but please make absolutely sure that your work remains private.(可选项,其实就是让你备份)
进入文件夹:
cd minnow创建一个目录来编译实验软件:
cmake -S . -B build编译源文件:
cmake --build build返回上层文件夹,打开
writeups/check0.md文件,这是实验检查点报告的模板。- .
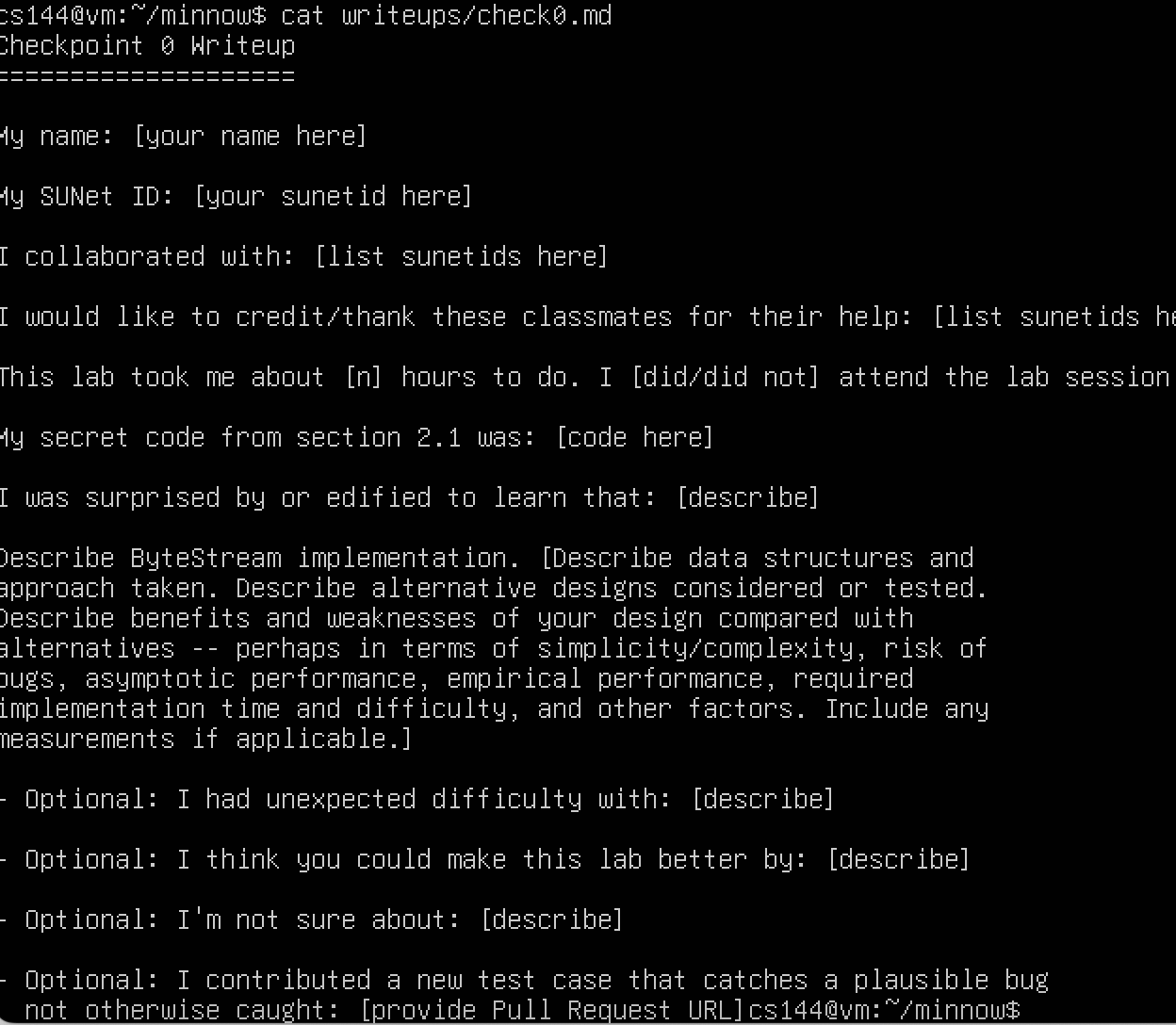
- .
3.2 Modern C++: mostly safe but still fast and low-level
实验作业将使用现代C++风格编写,这种风格使用最近(2011年)的语言特性以尽可能安全地进行编程。这可能与过去编写C++的方式不同。关于这种风格的参考,请参见C++ Core Guidelines。
具体来说:
- 使用 https://en.cppreference.com 作为编程资源。(我们建议您避免使用cplusplus.com,因为它可能已经过时。)
- 不要使用malloc()或free()。
- 不要使用new或delete。
- 尽量不使用原始指针(*),只在必要时使用“智能”指针(unique_ptr或shared_ptr)(在CS144中不需要使用这些)。
- 避免使用模板、线程、锁和虚函数(您在CS144中不需要使用这些)。
- 避免使用C风格字符串(char *str)或字符串函数(如strlen(),strcpy())。这些容易出错。请改用std::string。
- 不要使用C风格强制转换(例如,(FILE *)x)。如果需要,请使用C++静态强制转换(通常在CS144中不需要这样做)。
- 优先通过常量引用传递函数参数(例如:const Address & address)。
- 除非需要修改,否则使每个变量都为const。
- 除非需要修改对象,否则使每个方法都为const。
- 避免使用全局变量,并尽可能使每个变量的作用域最小。
- 在提交作业之前,运行
cmake --build build --target tidy以获取有关如何根据C++编程实践改进代码的建议,并运行cmake --build build --target format以一致地格式化代码。
3.3 阅读Minnow支持代码
为了支持这种编程风格,Minnow使用类将操作系统的函数封装成现代C++的形式。这些类主要是对您在CS 110/111课程中已经接触过的概念,如套接字和文件描述符,进行封装。
您需要阅读这些类的公共接口,这些接口定义在util/socket.hh和util/file descriptor.hh文件中的public:之后的部分。特别要注意的是,Socket是FileDescriptor的一种类型,而TCPSocket又是Socket的一种类型。
这段话乍一看我头都大了,查阅了一下得到的解释如下:
- Socket是网络编程中的一个概念,它允许程序通过计算机网络进行通信。
- FileDescriptor是一个更通用的概念,它通常指的是操作系统中的一个整数,用于标识打开的文件、套接字等资源。
- 在Minnow中,Socket是FileDescriptor的一个子类,这意味着Socket拥有FileDescriptor的所有功能,并且还有一些额外的网络通信相关的功能。同样,TCPSocket是Socket的子类,它提供了对TCP(传输控制协议)套接字的专门支持。
如果听起来还是很抽象,那我们还是看看代码吧
class Socket : public FileDescriptor
{
public:
//! Bind a socket to a specified address with [bind(2)](\ref man2::bind), usually for listen/accept
void bind( const Address& address );
//! Bind a socket to a specified device
void bind_to_device( std::string_view device_name );
//! Connect a socket to a specified peer address with [connect(2)](\ref man2::connect)
void connect( const Address& address );
//! Shut down a socket via [shutdown(2)](\ref man2::shutdown)
void shutdown( int how );
//! Get local address of socket with [getsockname(2)](\ref man2::getsockname)
Address local_address() const;
//! Get peer address of socket with [getpeername(2)](\ref man2::getpeername)
Address peer_address() const;
//! Allow local address to be reused sooner via [SO_REUSEADDR](\ref man7::socket)
void set_reuseaddr();
//! Check for errors (will be seen on non-blocking sockets)
void throw_if_error() const;
};可以看到Socket类是FileDescriptor的子类,它定义了一些与套接字相关的操作,如绑定地址、连接、关闭、获取本地和对等地址等。
class TCPSocket : public Socket
{
private:
//! \brief Construct from FileDescriptor (used by accept())
//! \param[in] fd is the FileDescriptor from which to construct
explicit TCPSocket( FileDescriptor&& fd ) : Socket( std::move( fd ), AF_INET, SOCK_STREAM, IPPROTO_TCP ) {}
public:
//! Default: construct an unbound, unconnected TCP socket
TCPSocket() : Socket( AF_INET, SOCK_STREAM ) {}
//! Mark a socket as listening for incoming connections
void listen( int backlog = 16 );
//! Accept a new incoming connection
TCPSocket accept();
};TCPSocket类是Socket的子类,它专门用于处理TCP套接字。TCPSocket类有两个构造函数,一个是默认构造函数,用于创建一个未绑定、未连接的TCP套接字;另一个是从FileDescriptor构造的,这通常是accept方法接受新连接时使用的。- 重点讲一下
explicit TCPSocket( FileDescriptor&& fd ) : Socket( std::move( fd ), AF_INET, SOCK_STREAM, IPPROTO_TCP ) {}这个部分,这是之前没有遇到过的(C++学的比较浅)。总的来说,
explicit TCPSocket( FileDescriptor&& fd ) : Socket( std::move(fd), AF_INET, SOCK_STREAM, IPPROTO_TCP ) {}表示TCPSocket构造函数接受一个右值引用的FileDescriptor类型的参数fd,并使用这个参数来初始化Socket对象。explicit关键字表示这个构造函数只能显式地被调用,不能隐式地转换类型。FileDescriptor&& fd表示这个构造函数接收一个FileDescriptor类型的参数,&&表示这个参数是右值引用,也就是说,这个参数可能是一个临时的对象。: Socket( std::move( fd ), AF_INET, SOCK_STREAM, IPPROTO_TCP )这部分是构造函数的初始化列表。它的作用是初始化这个TCPSocket对象的父类Socket。实际上是在调用基类Socket的构造函数,并传递了构造函数的参数。这样做的好处是,它可以确保基类构造函数在派生类构造函数体执行之前被调用,从而正确初始化基类的部分。std::move( fd )表示将fd的所有权移动给Socket,这样可以避免不必要的复制。AF_INET, SOCK_STREAM, IPPROTO_TCP是创建Socket时需要的参数,它们分别表示使用的网络协议族(IPv4),套接字类型(流式套接字)和协议(TCP)。
如果你觉得上面解释的如果还不够清晰,那说明你的c++和我一样学的半桶水,接下来是一些举例的知识补充:
explicit关键字
用一个更简单的例子来解释explicit关键字的作用。
想象一下你有一个装钱的钱包,这个钱包只能装纸币,不能装硬币。现在,你想要设计一个往钱包里放钱的功能。
- 没有
explicit的情况: 你设计了一个钱包的构造函数,这个构造函数可以接受一个纸币面额的参数,比如100,然后钱包里就会自动有100块钱。这个构造函数没有使用explicit关键字。这时,你可以这样使用这个钱包:class Wallet { public: Wallet(int money) : money(money) {} int getMoney() const { return money; } private: int money; };在第二种情况中,你只是写了一个数字Wallet wallet(100); // 明确地创建一个有100块钱的钱包 Wallet anotherWallet = 200; // 这里隐式地将200这个整数转换成了一个钱包200,并没有明确地调用构造函数,但是编译器却自动帮你创建了一个钱包,并且里面有200块钱。这就是没有explicit关键字的构造函数允许的隐式转换。 - 使用
explicit的情况: 现在,你决定在设计钱包的时候,不允许这种隐式转换,你希望每次往钱包里放钱都必须明确地调用构造函数。这时,你可以在构造函数前加上explicit关键字。这时,如果你尝试之前的那种隐式转换:class Wallet { public: explicit Wallet(int money) : money(money) {} int getMoney() const { return money; } private: int money; };第二行代码会导致编译错误,因为编译器不再允许你只是写一个数字就自动创建钱包。你必须明确地调用构造函数,像第一行那样。 所以,Wallet wallet(100); // 这仍然是正确的,因为这是明确地调用构造函数 Wallet anotherWallet = 200; // 这将是一个错误,因为构造函数是explicit的,不允许隐式转换explicit关键字的作用就是防止构造函数的隐式调用,让类型转换更加明确,避免程序中出现意想不到的行为。
在cs144这段代码中,如果我们尝试这样做:
FileDescriptor fd(1234); // 创建一个文件描述符
TCPSocket socket = fd; // 这将失败,因为TCPSocket的构造函数是explicit的
这段代码会失败,因为TCPSocket的构造函数是explicit的,这意味着我们不能使用隐式类型转换将FileDescriptor类型的值转换为TCPSocket对象。我们必须明确地调用构造函数,如下所示:
FileDescriptor fd(1234); // 创建一个文件描述符
TCPSocket socket(std::move(fd)); // 正确,明确地调用构造函数
右值引用
在C++中,我们有两种类型的引用:左值引用和右值引用。
左值引用是我们通常所说的引用,它引用的是一个具有明确存储位置的对象。例如:
int a = 5;
int& ref = a; // 左值引用
右值引用是C++11引入的新特性,它引用的是一个临时对象,或者说是一个将要销毁的对象。这种引用通常用于移动语义和完美转发。例如:
int&& rref = 5; // 右值引用
在这个例子中,数字5是一个临时对象,我们可以用右值引用来引用它。
FileDescriptor&& fd就是一个右值引用,它指向的是一个FileDescriptor类型的临时对象。这个构造函数的作用就是,直接取走这个临时对象的值,用来初始化一个新的TCPSocket对象,而不需要复制这个临时对象。
假设有个FileDescriptor对象:
FileDescriptor fd1(1);如果我们尝试这样做:
TCPSocket socket1(fd1); // 这会创建一个副本
这里,fd1是一个左值引用,因为它是一个有名字的对象。当我们传递fd1给TCPSocket的构造函数时,我们需要创建fd1的一个副本。
// 以下是创建TCPSocket对象的正确方式,使用右值引用
TCPSocket socket1(FileDescriptor(1)); // 创建了一个临时的FileDescriptor对象
std::move()
在C++中,std::move是一个函数模板,它将一个左值引用转换为右值引用。当你在代码中看到std::move(fd)时,它的作用是将fd这个左值引用转换为右值引用。这样,你就可以传递一个临时的对象,而不需要创建它的一个副本。
#include <utility> // for std::move
class MyObject {
public:
MyObject(int value) : value(value) {}
MyObject(MyObject&& other) : value(other.value) {
other.value = 0; // "窃取" other 的资源
}
int value;
};
int main() {
MyObject obj1(5);
MyObject obj2(std::move(obj1)); // 使用 std::move 将 obj1 转换为右值引用
// 现在,obj1 的值已经被 "窃取",obj2 的值是 5
return 0;
}在这个例子中,我们有一个MyObject类,它有一个接受右值引用的构造函数。在main函数中,我们创建了一个MyObject对象obj1,然后我们使用std::move(obj1)将obj1转换为右值引用,然后将其传递给obj2的构造函数。这样,obj2的构造函数就可以直接接收obj1的所有权,而不需要复制obj1。
回到原始问题,explicit TCPSocket( FileDescriptor&& fd ) : Socket( std::move(fd), AF_INET, SOCK_STREAM, IPPROTO_TCP ) {}中的std::move(fd)也是类似的作用。它将fd这个左值引用转换为右值引用,这样就可以传递一个临时的FileDescriptor对象,而不需要创建它的一个副本。这可以提高性能,因为我们避免了不必要的对象复制。
FileDescriptor fd1(1);
TCPSocket socket(std::move(fd1));在这段代码中,std::move(fd1)将fd1转换为右值引用,然后将其传递给TCPSocket的构造函数。这样,TCPSocket的构造函数就可以直接接收fd1的所有权,而不需要复制fd1。注意,一旦你这样做了,你就不应再使用fd1了,因为它的值可能已经被"窃取"了。
3.4 Writing webget
误会了现在才到写的时候。。。
- 在构建目录中,使用文本编辑器或集成开发环境打开…/apps/webget.cc文件。
- 在get URL函数中,实现如文件中所述的简单Web客户端,使用之前使用的HTTP(Web)请求格式。使用TCPSocket和Address类。
- 提示:
- 请注意,在HTTP中,每行必须以“\r\n”结束(仅使用“\n”或endl是不够的)。
- 不要忘记在你的客户端请求中包含“Connection: close”行。这告诉服务器在发送完这个请求后,不需要等待你的客户端发送更多的请求。相反,服务器将发送一个回复,然后会立即结束其发送的字节流(从服务器套接字到你的套接字)。你会发现你的传入字节流已经结束,因为当你的套接字读取完从服务器传来的整个字节流时,会达到“EOF”(文件结束)。这就是你的客户端知道服务器已经完成回复的方式。
- 确保读取并打印服务器所有输出直到套接字达到“EOF”(文件结束)——一次读取调用是不够的。
- 我们预计你将需要编写大约十行代码
我之前还尝试分析了一下源码,后来发现是我想多了。
在写代码之前,首先来回顾一下TCP协议的Socket套接字编程。更基础的,让我们回顾一下一些基础概念:
套接字
其实这个概念我至今都觉得很抽象,不过他确实非常重要
首先先问个问题,请问Socket和socket有什么区别? 你可能和我一样有些云里雾里,在不同教材或者csdn上叫法都不太统一,这玩意难道不是同一个东西?
以下是结合我个人的理解和gpt老师的答案:
在大多数情况下,“Socket”和“socket”指的是同一件事:计算机网络编程中用于通信的一种抽象概念,即套接字。套接字是网络通信的端点,允许不同进程在网络上进行通信。无论是大写还是小写,它们都是指同一个概念,只是书写时的大小写不同。在不同的编程语言或文档中可能会有不同的约定,但在通用的网络编程术语中,它们是等价的。
- Socket(首字母大写):
- 这通常是指操作系统提供的一个抽象层,它允许网络中的不同主机间进行通信。
- 在编程语境中,一个Socket代表一个网络连接的端点,可以看作是不同计算机进程间或同一计算机上不同进程间通信的一个门户。
- 在Unix和Linux系统中,Socket是实现进程间通信(IPC)和网络通信的一种机制。
- socket(首字母小写):
- socket 是一组用于网络通信的 API,提供了一种统一的接口,使得应用程序可以通过网络进行通信。在不同的操作系统中,socket 的实现方式可能不同,但它们都遵循相同的规范和协议,可以实现跨平台的网络通信。
- 在使用C语言编写网络程序时,
socket()函数是用来创建一个Socket连接的一个系统调用。 - 在Python等编程语言中,
socket模块提供了一个用于网络通信的接口,通过这个模块可以创建Socket连接,进行数据的发送和接收。
套接字与服务端进行通信流程
其实我觉得以上都是废话,简单来说,套接字就像是一个通信的桥梁,它允许不同设备上的应用程序进行数据交换。在编程中,我们通过套接字可以实现客户端和服务器之间的通信。
举例来说,当你使用浏览器访问一个网站时,你的电脑(作为客户端)和网站服务器之间就需要通过套接字来传输数据。这个过程大致如下:
- 服务器程序首先在自己的计算机上创建一个套接字,并且告诉网络操作系统它需要监听哪个端口(Port),这个过程可以看作是服务器在告诉外界:“我现在在这个地址(端口)上等待连接。”
- 你的电脑(客户端)在浏览器中输入网址后,浏览器会向服务器发起一个连接请求,这个请求会通过你的电脑创建一个套接字,并且通过网络找到服务器的套接字。
- 服务器接收到连接请求后,会创建一个新的套接字与你的电脑的套接字进行连接,从而建立起一个数据传输的通道。
- 一旦连接建立,数据就可以在你的电脑和服务器之间双向传输。比如,服务器会通过这个连接发送网页的数据给你的电脑,你的电脑接收到数据后,浏览器将其渲染成你看到的网页。
在这个例子中,套接字的作用就是使得客户端和服务器能够建立一个可靠的通信通道,从而实现数据的传输。无论是Web浏览、文件传输、即时通讯等网络应用,都离不开套接字技术的支持。
放一张陈年经典老图便于理解具体过程:
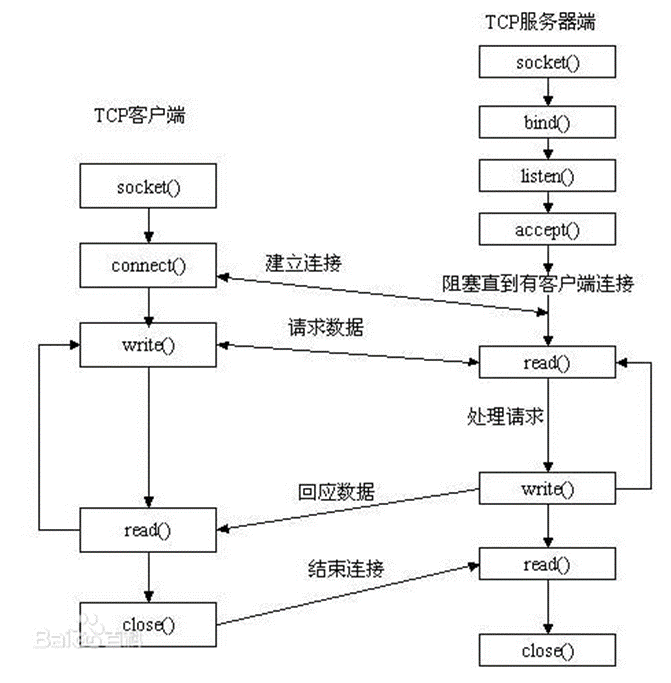
c++套接字编程相关函数
cs144的lab是用c++写的,那就让我们来看看相关的类和成员函数
//! A wrapper around [TCP sockets](\ref man7::tcp)
class TCPSocket : public Socket
{
private:
//! \brief Construct from FileDescriptor (used by accept())
//! \param[in] fd is the FileDescriptor from which to construct
explicit TCPSocket( FileDescriptor&& fd ) : Socket( std::move( fd ), AF_INET, SOCK_STREAM, IPPROTO_TCP ) {}
public:
//! Default: construct an unbound, unconnected TCP socket
TCPSocket() : Socket( AF_INET, SOCK_STREAM ) {}
//! Mark a socket as listening for incoming connections
void listen( int backlog = 16 );
//! Accept a new incoming connection
TCPSocket accept();
};TCPSocket()是一个公有构造函数,用于创建一个未绑定,未连接的 TCP 套接字。listen( int backlog = 16 )函数用于将套接字标记为监听状态,准备接收进来的连接请求。backlog参数指定了等待连接队列的大小。accept()函数用于接受一个新的连接请求。当有新的连接请求到来时,它会创建一个新的文件描述符来处理这个连接,然后使用这个文件描述符构造一个TCPSocket对象并返回。
创建套接字,监听函数,接受函数都有了,其他函数呢?你可能会奇怪诶为什么TCPSocket类里没有定义?是不是在父类Socket里,在socket.hh头文件一找,嗯找到了连接函数:
//! Connect a socket to a specified peer address with [connect(2)](\ref man2::connect)
void connect( const Address& address );void connect( const Address& address ):这个函数用于将套接字连接到一个指定的地址。 还是没看到读写函数和关闭函数,这时候你发现Socket也有父类FileDescriptor,继续套娃,你发现原来在file_descriptor.hh里声明了,好家伙真是连环套。
// Read into `buffer`
void read( std::string& buffer );
void read( std::vector<std::string>& buffers );
// Attempt to write a buffer
// returns number of bytes written
size_t write( std::string_view buffer );
size_t write( const std::vector<std::string_view>& buffers );
size_t write( const std::vector<std::string>& buffers );
// Close the underlying file descriptor
void close() { internal_fd_->close(); }void read( std::string& buffer )和void read( std::vector<std::string>& buffers ):这两个函数用于从文件描述符读取数据。第一个函数将读取的数据存入一个字符串,第二个函数将读取的数据存入一个字符串向量。size_t write( std::string_view buffer )、size_t write( const std::vector<std::string_view>& buffers )和size_t write( const std::vector<std::string>& buffers ):这三个函数用于向文件描述符写入数据。第一个函数写入一个字符串,第二个函数写入一个字符串向量,第三个函数也写入一个字符串向量。这三个函数都返回写入的字节数。void close():这个函数用于关闭文件描述符。
http报文格式
这部分不是代码的重点,不过还是简单介绍一下我们这次需要填写的GET请求报文,详情请参考相关专业书籍以及这个博客。
GET path HTTP/1.1
Host: host
Connection: close注意最后还有一个空行。 用cpp实现代码如下:
const string request { "GET " + path + " HTTP/1.1\r\n" + "Host: " + host + "\r\n" + "Connection: close\r\n"
+ "\r\n" };实现代码
这下,你终于找齐了图上所有函数,填写好简单请求报文。可以开始编程了!结合上面的流程图和函数,你可以填补get_URL函数模拟网页访问了。实际上代码确实很短,你只需要实现TCP套接字编程的客户端部分。
- 创建socket
TCPSocket socket;- 建立连接
const string service { "http" };
socket.connect( Address( host, service ) );
- 发送请求
const string request { "GET " + path + " HTTP/1.1\r\n" + "Host: " + host + "\r\n" + "Connection: close\r\n"
+ "\r\n" };
socket.write( request );- 读取响应并输出
string response, buffer;
while ( socket.read( buffer ), !buffer.empty() ) {
response.append( buffer );
}
cout << response;- 关闭连接
socket.close();好的以上就是所有代码,这次小实验主要是让我们初步上手套接字编程。接下来让我们来测试一下:
代码测试
在终端执行以下代码进行测试
cmake --build build --target check_webget如果你的代码还没完成/出现错误,那么将会出现类似以下结果:
Test project /home/cs144/minnow/build
Start 1: compile with bug-checkers
1/2 Test #1: compile with bug-checkers ........
Passed
1.02 sec
Start 2: t_webget
2/2 Test #2: t_webget .........................***Failed
Function called: get_URL(cs144.keithw.org, /nph-hasher/xyzzy)
Warning: get_URL() has not been implemented yet.
ERROR: webget returned output that did not match the test's expectations如果成功,就会出现如下类似结果:
cs144@vm:~/minnow$ cmake --build build --target check_webget
Test project /home/cs144/minnow/build
Start 1: compile with bug-checkers
1/2 Test #1: compile with bug-checkers ........ Passed 0.15 sec
Start 2: t_webget
2/2 Test #2: t_webget ......................... Passed 3.26 sec
100% tests passed, 0 tests failed out of 2
Total Test time (real) = 3.41 sec
Built target check_webget这时候你发现他好像有点慢,官方文档里t_webget才0.72s。诶是怎么一回事呢? 在这里挖一个坑待填~~(因为我的c++学的真是太差了)~~
4.An in-memory reliable byte stream
正当我以为lab0就大功告成,真是易如反掌,易如反掌啊的时候,我惊喜地发现那只是前菜,接下来的字节流编程更是折磨。
先读题目:
实验目的:
- 实现一个抽象的可靠字节流对象,即使底层网络只提供“尽力而为”(不可靠)的数据报服务。
- 字节流是有界的:写入端可以结束输入,之后不能再写入更多字节;读取端读到流的末尾时,会到达“EOF”(文件结束),之后不能再读取更多字节。
实验要求:
- 字节流需要有流量控制以限制任何给定时间的内存消耗。
- 字节流对象初始化时会指定一个“容量”参数,即它愿意在任何给定时刻存储在自身内存中的最大字节数。
- 写入端在任何给定时刻能写入的量受到限制,以确保流不会超过其存储容量。
- 读取端读取字节并从流中清除它们时,写入端被允许写入更多数据。
- 字节流用于单线程环境,不需要担心并发写入/读取、锁定或竞态条件。
实验细节:
- 字节流是有界的,但在写入端结束输入并完成流之前,它可以几乎任意长。
- 实现必须能够处理比容量长得多的流。
- 容量限制了在任何给定时刻保留在内存中的字节数(已写入但尚未读取),但不限制流的长度。
- 即使是容量仅为一个字节的对象,只要写入端一次写入一个字节,并且读取端在写入下一个字节之前读取每个字节,它仍然可以携带长达数TB的流。
需要实现的接口定义:
对于写入端:
void push(std::string data):将数据推送到流中,但只能推送可用容量允许的数据量。void close():信号表示流已到达结尾。不会再写入任何内容。bool is_closed() const:流是否已被关闭?uint64_t available_capacity() const:当前可以推送到流中的字节数。uint64_t bytes_pushed() const:累计推送到流中的总字节数。
对于读取端:
std::string_view peek() const:查看缓冲区中的下一些字节。void pop(uint64_t len):从缓冲区中移除len个字节。bool is_finished() const:流是否已完成(已关闭并完全弹出)?bool has_error() const:流是否出现错误?uint64_t bytes_buffered() const:当前缓冲的字节数(已推送且尚未弹出)。uint64_t bytes_popped() const:从流中累计弹出的总字节数。
非常无聊的代码解读
让我们来看看byte_stream.hh头文件的源码
#pragma once // 确保这个头文件只被包含一次
#include <cstdint> // 引入标准库,包含基本的整数类型定义
#include <string> // 引入标准库,包含字符串类的定义
#include <string_view> // 引入标准库,包含对字符串的非拥有(non-owning)视图的定义
// ByteStream类是Writer和Reader的基类
class ByteStream
{
public:
// 构造函数,初始化时传入流的容量
explicit ByteStream(uint64_t capacity) : capacity_(capacity) {}
// 提供对Reader和Writer接口的访问的辅助函数
Reader& reader(); // 返回Reader对象的引用
const Reader& reader() const; // 返回const Reader对象的引用
Writer& writer(); // 返回Writer对象的引用
const Writer& writer() const; // 返回const Writer对象的引用
// 设置流错误状态,并提供一个方法来检查流是否发生过错误
void set_error() { error_ = true; }
bool has_error() const { return error_; }
protected:
// 这里添加ByteStream的任何额外状态,不要添加到Writer和Reader接口中
uint64_t capacity_; // 流的容量
bool error_ {}; // 流是否发生过错误的标志
};
// Writer类继承自ByteStream,用于写入数据
class Writer : public ByteStream
{
public:
// 向流中推送数据,但只能推送当前可用容量允许的数据量
void push(std::string data);
// 标记流已经结束,之后不再写入数据
void close();
// 检查流是否已经被关闭
bool is_closed() const;
// 返回当前可以推送到流中的字节数
uint64_t available_capacity() const;
// 返回累计推送到流中的总字节数
uint64_t bytes_pushed() const;
};
// Reader类继承自ByteStream,用于读取数据
class Reader : public ByteStream
{
public:
// 查看缓冲区中的下一些字节,但不移除它们
std::string_view peek() const;
// 从缓冲区移除len个字节
void pop(uint64_t len);
// 检查流是否已经结束(已关闭并且所有数据都已弹出)
bool is_finished() const;
// 返回当前缓冲的字节数(已推送且尚未弹出)
uint64_t bytes_buffered() const;
// 返回从流中累计弹出的总字节数
uint64_t bytes_popped() const;
};
// read函数是一个辅助函数,用于从ByteStream的Reader中peek并pop最多len个字节到一个字符串中
void read(Reader& reader, uint64_t len, std::string& out);为了实现内存中的字节流,需要一些成员变量来维护流的状态。以下是在ByteStream类里补充的成员变量:
std::deque<char> buffer_;buffer_是一个双端队列,用于存储字节流中的数据。使用std::deque(双端队列)是因为它支持高效的两端插入和删除操作,这对于模拟字节流的写入(push)和读取(pop)操作非常合适。
bool closed_ {};closed_是一个布尔值,用来标记字节流是否已经被关闭。一旦流被关闭,就不应该再有数据写入。这个状态对于Writer类特别重要,因为它需要知道何时停止接受新的数据。
uint64_t bytes_pushed_ {};bytes_pushed_这是一个无符号整数,用于记录已经推送到字节流中的字节数。每次调用push方法时,都会更新这个值。
uint64_t bytes_popped_ {};- 这是一个无符号整数,用于记录已经从字节流中弹出的字节数。每次调用
pop方法时,都会更新这个值。
- 这是一个无符号整数,用于记录已经从字节流中弹出的字节数。每次调用
实现接口
接下来让我们开始一步一步实现接口吧! 首先是最简单的方法:
bool Writer::is_closed() const
{
return closed_;
} 这个函数非常简单,它只是返回 closed_ 成员变量的值。closed_ 是一个布尔值,用于标记字节流是否已经关闭。如果 closed_ 为 true,则表示字节流已经关闭,不再允许向其中写入数据。
接下来是很重要的push函数:
void Writer::push(string data)
{
// 如果流已经关闭,直接返回,不再进行后续操作
if (closed_) {
return;
}
// 计算要推送的字节数,这个数是输入数据的大小和流的可用容量之间的较小值
uint64_t to_push = std::min(data.size(), available_capacity());
// 如果要推送的字节数为0,表示没有可用的容量,因此不推送任何数据,直接返回
if (to_push == 0) {
return;
}
// 使用循环将要推送的数据添加到流中
for (uint64_t i = 0; i < to_push; ++i) {
buffer_.push_back(data[i]); // 将数据添加到流的末尾
}
// 更新已推送的字节数
bytes_pushed_ += to_push;
}首先,检查
closed_是否为true。如果为true,则表示字节流已经关闭,不再允许写入数据,因此直接返回。然后,计算要推送的字节数
to_push。这个数是data.size()(即输入数据的大小)和available_capacity()(即字节流的可用容量)之间的较小值。如果to_push为0,则表示没有可用的容量,因此不推送任何数据,直接返回。最后,使用循环将要推送的数据添加到
buffer_中。buffer_是一个std::deque<char>,用于存储字节流中的数据。循环的次数是要推送的字节数,每次循环都将一个字节的数据添加到buffer_的末尾。
又是几个很简单的函数:
void Writer::close()
{
closed_ = true;
}这个方法的思路非常简单:就是将 closed_ 设置为 true,以标记字节流已经关闭。
bool Reader::is_finished() const
{
return buffer_.empty()&&closed_;
}buffer_.empty() 是一个布尔值,表示 buffer_(字节流的缓冲区)是否为空。如果 buffer_ 为空,表示没有更多的数据可以从字节流中读取。
closed_ 是一个布尔值,用于标记字节流是否已经关闭。如果 closed_ 为 true,表示字节流已经关闭,不再允许向其中写入数据。
因此,如果 buffer_ 为空并且 closed_ 为 true,则表示字节流已完成。
uint64_t Writer::available_capacity() const
{
if (buffer_.size() > capacity_) {
throw std::runtime_error("Buffer size exceeds capacity.");
}
return capacity_ - buffer_.size();
}这个方法是检查buffer_的可用容量的代码。首先检查 buffer_ 的大小是否超过了 capacity_,如果超过了就抛出错误;没超过就返回字节流的可用容量。
uint64_t Writer::bytes_pushed() const
{
return bytes_pushed_;
}
uint64_t Reader::bytes_popped() const
{
return bytes_popped_;
}这俩方法的思路非常简单:就是返回 bytes_popped_ 和bytes_pushed_ 的值,即已经从字节流中弹出的字节数和已经推送到字节流中的字节数。
那到底在哪里更新这俩值呢?bytes_pushed_在前面的push函数中被更新;而bytes_popped_顾名思义则在下面的pop函数中更新。
void Reader::pop( uint64_t len )
{
if (len > buffer_.size()) {
throw std::runtime_error("Cannot pop more data than available in the buffer.");
}
len = std::min(len, buffer_.size()); // 确保不会删除超过 buffer_ 大小的元素
for (uint64_t i = 0; i < len; ++i) {
buffer_.pop_front();
}
bytes_popped_ += len;
}- 在这个方法中,首先检查要弹出的数据量
len是否超过了buffer_(字节流的缓冲区)的大小。如果超过了,就抛出一个运行时错误。 - 然后,将
len设置为len和buffer_.size()之间的较小值,以确保不会删除超过buffer_大小的元素。 - ==你可能会奇怪,前面已经判断过了,
len已经被确认不会大于buffer_.size(),为什么还要再取值一遍?在这段代码中,因为在多线程环境中,如果在检查len > buffer_.size()之后和执行len = std::min(len, buffer_.size());之前,另一个线程修改了buffer_,那么len可能会大于buffer_.size()。在这种情况下,std::min调用可以防止尝试弹出超过buffer_大小的元素。== - 接着,使用循环从
buffer_中弹出len个元素。每次循环都调用buffer_.pop_front(),这个方法会删除buffer_的第一个元素。 - 最后,更新
bytes_popped_的值,将其增加len。bytes_popped_是一个无符号整数,用于记录已经从字节流中弹出的字节数。
然后就是最后一个peek 方法的实现。这个方法的作用是预览字节流中的数据,但不从字节流中删除这些数据。
这个方法真的让我错了很多遍,测试麻了都。一开始的代码是这样的:
string_view Reader::peek() const {
if (buffer_.empty()) {
// 返回一个非空但内容为空的视图
return string_view(nullptr, 0);
} else {
// 只返回缓冲区中实际存在的数据,而不是整个缓冲区的大小
return std::string_view(&buffer_.front(), bytes_buffered());
}
}后来怎么测试都测试不过,才发现哦,peek 方法的目的是只查看 buffer_ 的第一个元素,而不是所有元素,改了之后终于通过了耶!
string_view Reader::peek() const {
if (buffer_.empty()) {
return string_view(nullptr, 0); // 返回一个空视图
} else {
// 只返回缓冲区中实际存在的数据,而不是整个缓冲区的大小
return std::string_view(&buffer_.front(), 1);
}
}先来解释一下
std::string_view,它是 C++17 引入的一个新特性,它是一个轻量级的、非拥有的只读字符序列视图。它可以看作是指向字符数组的指针和长度的组合,但并不拥有它所指向的字符数组。std::string_view的主要用途是作为函数的参数类型,特别是当函数需要接受一个字符串,但不需要拥有它时。使用std::string_view可以避免不必要的字符串复制,提高性能。在这个方法中,首先,检查
buffer_是否为空。这是通过调用buffer_.empty()来完成的。如果buffer_为空(即没有数据可以读取),那么方法返回一个空的std::string_view。这是通过string_view(nullptr, 0)实现的,它创建了一个没有数据的std::string_view。如果
buffer_不为空,那么方法返回一个std::string_view,它表示buffer_的第一个元素。这是通过std::string_view(&buffer_.front(), 1)实现的。这里,&buffer_.front()获取buffer_第一个元素的地址,1表示我们只关心一个元素。
最后执行cmake --build build --target check0测试
测试结果如下,终于成功了,第一个实验完结撒花🎉!
cs144@vm:~/minnow$ cmake --build build --target check0
Test project /home/cs144/minnow/build
Start 1: compile with bug-checkers
1/10 Test #1: compile with bug-checkers ........ Passed 0.20 sec
Start 2: t_webget
2/10 Test #2: t_webget ......................... Passed 1.37 sec
Start 3: byte_stream_basics
3/10 Test #3: byte_stream_basics ............... Passed 0.04 sec
Start 4: byte_stream_capacity
4/10 Test #4: byte_stream_capacity ............. Passed 0.02 sec
Start 5: byte_stream_one_write
5/10 Test #5: byte_stream_one_write ............ Passed 0.02 sec
Start 6: byte_stream_two_writes
6/10 Test #6: byte_stream_two_writes ........... Passed 0.01 sec
Start 7: byte_stream_many_writes
7/10 Test #7: byte_stream_many_writes .......... Passed 0.07 sec
Start 8: byte_stream_stress_test
8/10 Test #8: byte_stream_stress_test .......... Passed 0.25 sec
Start 37: compile with optimization
9/10 Test #37: compile with optimization ........ Passed 0.07 sec
Start 38: byte_stream_speed_test
ByteStream throughput: 0.85 Gbit/s
10/10 Test #38: byte_stream_speed_test ........... Passed 0.16 sec
100% tests passed, 0 tests failed out of 10
Total Test time (real) = 2.21 sec
Built target check0