缓冲区结构
frame的参数
- Dirty
- Frame中的块是否已经被修改
- Pin-count
- Frame的块的已经被请求并且还未释放的计数,即当前的用户数
- *Others
- Latch: 是否加锁
当请求块时
- 当一个程序请求一个不在内存中的数据块时,操作系统需要从磁盘中读取该数据块。
- 首先,它需要在内存中找到一个帧来存放这个数据块。
- 如果选中的帧是脏的(即,帧中的数据已被修改但尚未写回磁盘),那么操作系统需要先将这个帧的内容写回磁盘。
- 然后,操作系统从磁盘中读取请求的数据块,并将其放入选中的帧中。
- 最后,操作系统会增加该帧的固定计数Pin-count(即,标记该帧正在被使用),并返回该数据块在内存中的地址。这样,程序就可以直接访问内存中的数据,而不需要再次从磁盘中读取。这个过程是操作系统管理内存的重要部分,也是实现虚拟内存的关键。
当释放块时
- 当程序完成对一个数据块的访问后,它需要取消固定(unpin)包含该数据块的帧,以便操作系统可以在需要时重新使用该帧。
- 同时,如果程序修改了数据块的内容,它需要设置该帧的脏位(dirty bit)。脏位是用来标记帧中的数据是否已被修改,但尚未写回磁盘。如果脏位被设置,那么在帧被替换之前,操作系统需要先将帧的内容写回磁盘。这样可以确保磁盘中的数据始终是最新的,即使发生了系统崩溃或电源故障。
缓冲区替换策略
- 当内存中没有空闲的帧来存放新的数据块时,操作系统需要选择一个已经被使用的帧进行替换。选择哪个帧进行替换是由替换策略决定的,常见的替换策略包括最近最少使用(LRU),时钟,先进先出(FIFO),最近最常使用(MRU)等。
- 只有当帧的固定计数为0时,也就是说,当没有程序正在使用该帧时,该帧才会被考虑作为替换的候选者。
- 替换策略的选择可以对系统的I/O性能产生重大影响,因为每次替换都可能需要从磁盘中读取数据或将数据写回磁盘。不同的访问模式可能会导致某些替换策略比其他策略表现得更好。
理论最优算法:OPT算法
也称为Belady’s算法
理论上最佳的页面置换算法。它每次都置换以后永远也用不到的页面,如果没有则淘汰最久以后再用到的页面。
OPT算法必须预先知道全部的页面访问序列,而这在实际DBMS/OS中是无法实现的,因此仅有理论意义。
但OPT算法可以在实验中作为算法性能上界加以对比
LRU
- LRU (Oracle, Sybase, Informix)
- 所有frame按照最近一次访问时间排列成一个链表
- 基于时间局部性(Temporal Locality) 假设:越是最近访问的在未来被访问的概率越高. 总是替换LRU端的frame
- Pros
- 适用于满足时间局部性的场景(多次重复请求同一页)
- 选取frame的时间复杂度是O(1)
- Cons:
- 缓存污染(Sequentialflooding):容易出现被频次少的一次连续大量的请求污染,将之前维护的良好的LRU结构都清洗掉了(最大的问题—by老师)
- “清洗掉"是指低频请求的数据占据了缓存空间,导致原本频繁访问的数据(即LRU结构中的数据)被挤出缓存。
- 维护LRU链表代价昂贵:修改链表耗时
- 如果访问不满足时间局部性,则性能较差
- 只考虑最近一次访问,不考虑访问频率
- 缓存污染(Sequentialflooding):容易出现被频次少的一次连续大量的请求污染,将之前维护的良好的LRU结构都清洗掉了(最大的问题—by老师)
LRU-K
LRU不考虑frame的访问频率,不合理
LRU-K:如果某个frame的访问次数达到了K次以上,则应当尽量不置换 - 维护2个LRU链表 - 1个是访问次数小于K次的 - 1个是访问次数K次以上的
- 优先按照LRU策略置换小于K次的链表
- 保证高频访问的页能够尽量在buffer中
- 实验表明
- K并非越大越好,LRU-2 性能较好
- 缺点:需要额外记录访问次数
2Q
- 与LRU-2类似,不同之处在于访问1次的队列采用FIFO,而不是LRU
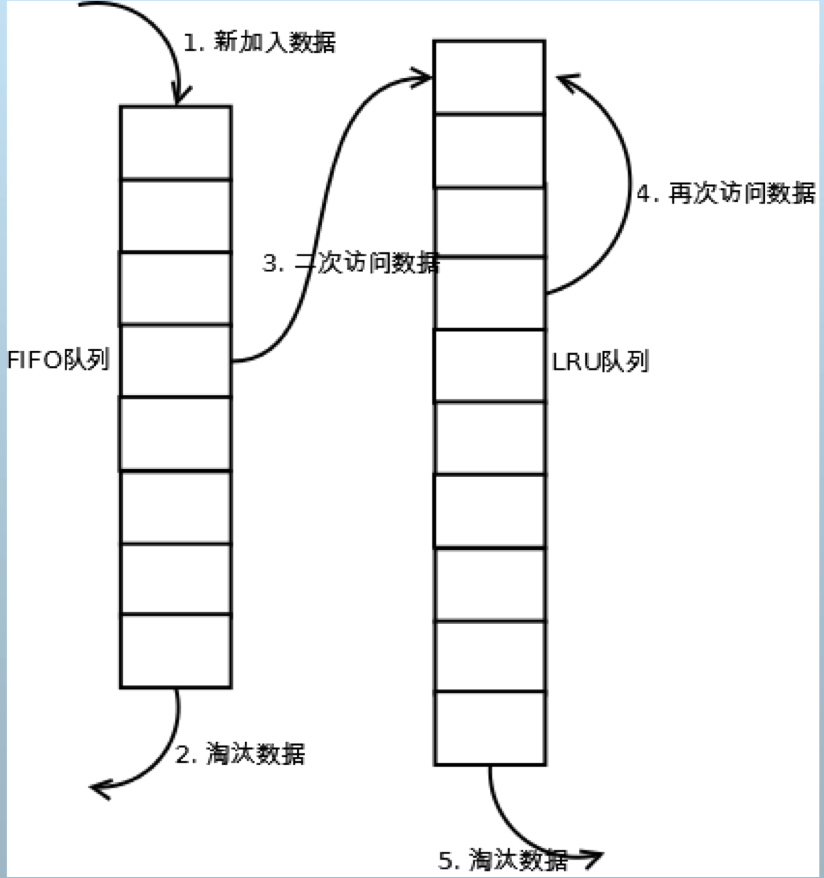

- 这题按照题意,其实说的是2Q的变体,并不是LRU-K,将2Q左边FIFO换成LRU,中间控制阈值改为K
- 根本原因就是:K值只增不减
- 策略1:根据负载,动态调整K
- 策略2; 引入老化机制,减少右侧队列累计的访问次数
- 实际上LRU-K,按上述情况并不会退化成LRU,而是会退化成一个优先队列
- LRU-K算法会淘汰那个在所有帧中具有最大向后k距离的帧。向后k距离是指当前时间戳与第k次之前访问的时间戳之间的差值。这意味着,如果一个帧在最近k次访问中没有被访问过,那么它的向后k距离就会很大,因此它有可能被LRU-K算法淘汰。
- 如果一个帧的历史访问次数少于k次,那么它的向后k距离被赋予+∞。这意味着,这个帧在最近k次访问中从未被访问过,因此它的向后k距离被视为无穷大。
- 当有多个帧的向后k距离都是+∞时,淘汰器会淘汰那个具有最早时间戳的帧。这实际上是FIFO(先进先出)策略的应用。也就是说,当有多个帧都没有在最近k次访问中被访问过时,LRU-K算法会淘汰最早被加载到内存中的帧。
- 这题按照题意,其实说的是2Q的变体,并不是LRU-K,将2Q左边FIFO换成LRU,中间控制阈值改为K
Second-Chance FIFO
所有frame组成FIFO链表,每个frame附加一个bit位,初始为0。当FO页第一次被选中置换时置为1,并移到FI端。只有bit位为1的FO端的页才被选中置换。
相当于每个frame给了两次置换机会,避免高频访问但最近一轮没有被访问的frame被置换出buffer
每个frame只需要1个额外bit,空间代价很低
缺点:置换时需要移动多个元素,理论性能比LRU差

Clock(时钟置换算法)
- 把Second-Chance FIFO组织成环形
- N个frame组成环形,current指针指向当前frame;每个frame有一个referenced位,初始为1;
- 当需要置换页时按顺序执行下面操作:
SSD上的置换算法
- 闪存:读快写慢,写次数有限
- 减少缓存置换中对闪存的写是一个重要指标
- SSD-aware缓存算法
- CFLRU (CASES’06,CASES’21 Testof Time Award)
- Clean-first
- LRU-WSR (IEEE Trans CE’08)
- Clean-first + cold flag
- 置换:clean>cold dirty>hot dirty
- AD-LRU (DKE’10)
- cold LRU list + hot LRU list
- Dynamically adjust two LRUs
- CFLRU (CASES’06,CASES’21 Testof Time Award)
Q: 为什么不适用OS缓冲区管理,而需要DBMS?
- DBMS经常能预测访问模式(AccessPattern)
- 可以使用更专门的缓冲区替换策略
- 有利于pre-fetch策略的有效使用
- DBMS需要强制写回磁盘能力(如WAL),OS的缓冲写回一般通过记录写请求来实现(来自不同应用),实际的磁盘修改推迟,因此不能保证写顺序
缓冲区管理的实现
实验 略
习题
假 设 我 们 采 ⽤ L R U 作 缓 冲 区 置 换 策 略 , 当 我 们 向 B u f f e r M a n a g e r 发 出 ⼀ 个 读 页 请 求时 , 请 讨 论 ⼀ 下 :
- ( 1 ) 如 果 页 不 在 缓 冲 区 中 , 我 们 需 要 从 磁 盘 中 读 ⼊ 该 页 。 请 问 如 何 才 能 在 缓 冲 区 不 满 的时 候 快 速 地 返 回 ⼀ 个 f r e e 的 f r a m e ? 请 给 出 ⾄ 少 两 种 策 略 , 并 分 析 ⼀ 下 各 ⾃ 的 时 间 复 杂 度 。
- a.将所有的空闲的frame id插入到一个链表中,每次从链表头部返回一个空闲frame id,时间复杂度为O(1)
- b. 使用位图,位图的每一位表示一个frame的空闲/占用情况(例如1表示被占用,0表示空闲),需要寻找一个free的frame时,直接扫描位图,找到位图中为0的位置,进而得出其frame id。时间复杂度为O(n)
- (2)如何才能快速地判断所请求的页是否在缓冲区中?如果请求的页在缓冲区中,如何快速返回该页对应的frame地址?请给出至少两种策略,并分析一下各自的时间复杂度。
- a.将在缓冲区的的页的page id以及所在的frame的id以键值对的形式(page id內key, frame id为value)存储在一个哈希表中。可以在**O(1)**的时间复杂度下判断所请求的页是否在缓冲区中,若在缓冲区中可以找到键值对,进而返回该页对应的frame地址。
- b.将在缓冲区的的页的page id以及所在的frame的id以键值对的形式(page idkey,frame id为value)存储在一棵B+-tree中,可以在**O(logn)**的时间复杂度下判断所请求的页是否在缓冲区中,若在缓冲区中可以找到键值对,进而返回该页对应的frame地址
- ( 1 ) 如 果 页 不 在 缓 冲 区 中 , 我 们 需 要 从 磁 盘 中 读 ⼊ 该 页 。 请 问 如 何 才 能 在 缓 冲 区 不 满 的时 候 快 速 地 返 回 ⼀ 个 f r e e 的 f r a m e ? 请 给 出 ⾄ 少 两 种 策 略 , 并 分 析 ⼀ 下 各 ⾃ 的 时 间 复 杂 度 。
3、我们在讲义上介绍了 SSD感知的 CF-LRU 算法,即 Clean-First LRU 算法。该算法虽然看起来可以减少对SSD 的写操作,但依然存在一些问题。请分析一下该算法的主要缺点有哪些?给出三点,并简要解释你的理由。
- CF-LRU算法的基本思想是:把LRU链表分为工作区和替换区,工作区负责维护最近访问的数据页,替换区则负责维护替换候选队列,替换时总是优先替换替换区中的干净页,若替换区没有干净页,则选择LRU链表尾部的第一个脏页作为置换页。在CF-LRU算法中替换区的大小是由窗口大小决定的。CF-LRU通过优先替换出替换区的干净页,在一定程度上可以有效地减少对闪存的写和擦除操作,提升了性能,但还存在一些不足
- (1)很难确定一个合适窗口大小的值来适应不同类型的负载。
- (2)当链表较长时,查找干净页作为置换页的代价会较高。由于算法在选择置换页时需要沿着链表反向查找干净页,当链表较长时查找代价会增加。
- (3)没有考虑缓冲区页的访问频率,在进行替换操作时,容易保留较老的脏页,而替换热的干净页,这会导致缓冲区命中率的降低。
- CF-LRU算法的基本思想是:把LRU链表分为工作区和替换区,工作区负责维护最近访问的数据页,替换区则负责维护替换候选队列,替换时总是优先替换替换区中的干净页,若替换区没有干净页,则选择LRU链表尾部的第一个脏页作为置换页。在CF-LRU算法中替换区的大小是由窗口大小决定的。CF-LRU通过优先替换出替换区的干净页,在一定程度上可以有效地减少对闪存的写和擦除操作,提升了性能,但还存在一些不足
假设一个磁盘块可以存储8条记录或64个“键-指针”对,记录数为n,且记录定长。
密集索引:在密集索引中,数据库中的每个搜索键值都有一个索引记录1。因此,索引的大小将与记录的数量成正比。如果我们有n条记录,那么我们需要n/8个磁盘块来存储索引(因为每个磁盘块可以存储8个索引项)。加上存储数据本身需要的n/8个磁盘块,总共需要n/4个磁盘块。
稀疏索引:在稀疏索引中,不会为每个搜索键创建索引记录1。通常,稀疏索引为每个磁盘块的第一个记录建立索引1。因此,如果我们有n条记录,那么我们需要n/64个磁盘块来存储索引(因为每个磁盘块可以存储64个索引项)。加上存储数据本身需要的n/8个磁盘块,总共需要n/64 + n/8个磁盘块。