读完本文,你将能轻松解答三个常见的 Redis 面试题:
- Redis 究竟是单线程还是多线程?
- 你了解 I/O 多路复用吗?
- Redis 为什么如此快?
在探讨这些问题之前,我们先得出一个核心结论:Redis 在 4.0 版本之前,其核心网络模型是单线程的,但引入了部分多线程功能,如异步删除。从 Redis 6.0 开始,则正式引入了多线程 I/O,以进一步提升性能。
Redis 早期为什么选择单线程模型?
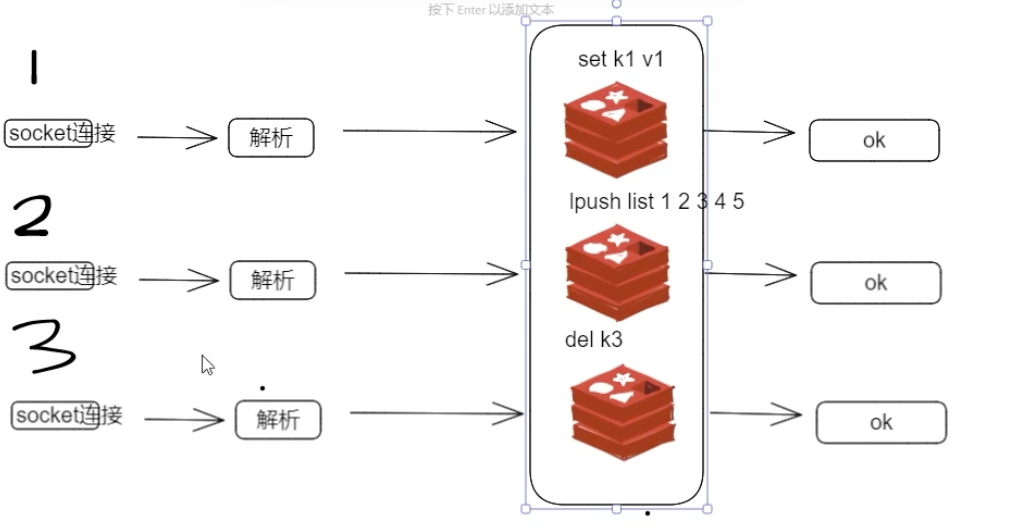
通常我们说 Redis 是“单线程”,指的是其处理网络 I/O 和键值对读写的主流程由一个线程顺序执行。当 Redis 处理客户端请求时,从接收(socket 读)、解析、执行到返回(socket 写)的整个过程,都由这个主线程负责。这便是其“单线程”模型的本质。
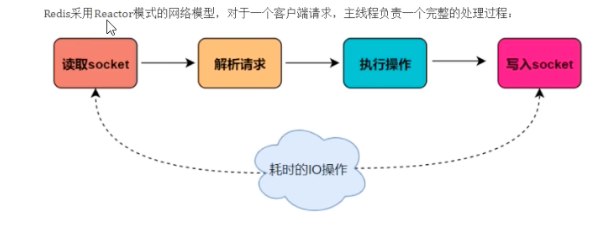
然而,这并不意味着 Redis 内部完全没有其他线程。持久化(RDB 和 AOF)、异步删除、集群数据同步等功能,实际上是由独立的后台线程执行的。因此,一个更准确的描述是:Redis 的命令处理工作线程是单线程的,但整个 Redis 应用是多线程的。
Redis 3.0 时代单线程模型为何依然高效?
- 纯内存操作:Redis 将所有数据存储在内存中,操作基本上是内存级别,速度极快。
- 精简的数据结构:Redis 内部的数据结构经过专门设计,大部分操作的时间复杂度仅为 O(1),保证了高效的存取。
- I/O 多路复用和非阻塞 I/O:这是 Redis 单线程模型能处理高并发的关键。它使用 I/O 多路复用机制监听多个客户端连接(socket),由一个线程处理所有请求,避免了频繁的线程切换开销和 I/O 阻塞。
- 避免上下文切换:单线程模型天然避免了多线程间的上下文切换和竞态条件,减少了性能损耗,也规避了死锁等复杂问题。
Redis 官方文档中曾有如下解释:
CPU is not usually the bottleneck for Redis, as usually Redis is either memory or network bound.

这段话的核心意思是,Redis 的性能瓶颈通常在于内存大小或网络带宽,而非 CPU。既然 CPU 资源不是主要矛盾,采用单线程模型既能满足需求,又能简化系统设计。
总结来说,Redis 早期坚持单线程主要基于三点:
- 单线程模型使开发和维护更简单、易于调试。
- 通过 I/O 多路复用和非阻塞 I/O,单线程足以应对高并发场景。
- 系统的主要瓶颈是内存和网络,而非 CPU。
既然单线程如此优秀,为何又要引入多线程?
时代在发展,硬件在进步。在多核 CPU 普及的今天,单线程模型无法充分利用硬件资源。更重要的是,随着业务场景的变化,单线程模型暴露出了一些问题。
其中最典型的问题就是 “大 Key 删除” 。Redis 的命令是原子性的,当使用 DEL 命令删除一个包含数百万元素的巨大哈希表或集合时,主线程需要花费很长时间来释放内存,导致整个服务被阻塞,无法响应其他请求。在高并发场景下,这种卡顿是致命的。
为了解决这个问题,Redis 4.0 引入了惰性删除(Lazy Free) 。
当你需要删除一个大 Key 时,可以使用 UNLINK 命令(以及 FLUSHDB ASYNC、FLUSHALL ASYNC)。这些命令不会立即在主线程上执行删除操作,而是将任务交给一个后台线程(bio, Background I/O)去异步处理。这种“懒删除”的本质,是将高成本的删除操作从主线程剥离,极大地减少了主线程的阻塞时间,提升了系统的稳定性和性能。
Redis 6.0/7.0 的多线程特性与 I/O 多路复用
如前所述,Redis 的主要性能瓶颈在于网络 I/O。随着硬件性能的提升,单个主线程处理网络请求的速度有时会跟不上底层网络硬件的速度。
为了解决这一新瓶颈,Redis 6.0 引入了多线程 I/O。这一特性旨在通过多个 I/O 线程来并行处理网络请求,从而提高吞吐量。
需要强调的是,Redis 的多线程仅用于处理网络 I/O(读取、解析、写回) ,而真正的命令执行阶段,依旧由主线程以单线程方式串行执行。这样做的好处是显而易见的:
- 利用多线程提升了 I/O 处理能力,解决了网络瓶颈。
- 保持了命令执行的单线程,无需引入复杂的锁机制来保证事务和 Lua 脚本的原子性,使得核心逻辑依然简洁高效。
主线程与 I/O 线程的协作流程
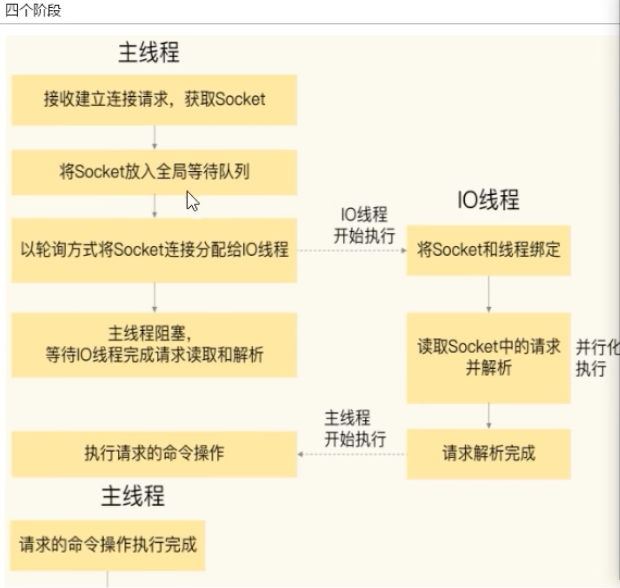
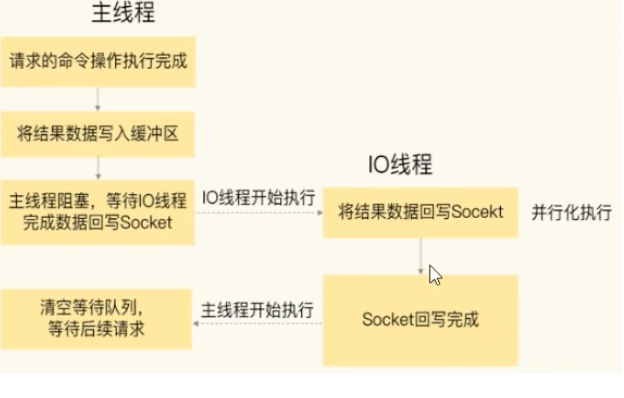
- 阶段一:连接建立与分配
主线程负责接收客户端的连接请求,创建 socket 后,将其放入一个全局等待队列。随后,主线程通过轮询策略将这些 socket 分配给各个 I/O 线程。 - 阶段二:I/O 线程读取与解析
I/O 线程并行地从各自负责的 socket 中读取客户端请求,并进行解析。这个过程是多线程的,速度很快。完成后,主线程被唤醒。 - 阶段三:主线程执行命令
主线程以单线程的方式,依次执行所有已解析的命令。 - 阶段四:I/O 线程回写响应
主线程执行完毕后,将返回结果写入缓冲区。接着,多个 I/O 线程再次并行地将这些结果写回各自的客户端 socket。操作完成后,主线程清空队列,准备处理下一批请求。
深入理解 I/O 多路复用
文件描述符(File Descriptor, FD)
在 Linux 系统中,“一切皆文件”。文件描述符是一个非负整数,用于唯一标识一个打开的文件(或 socket 连接)。内核为每个进程维护一个文件描述符表,当进程打开文件或建立网络连接时,内核会返回一个 FD。
什么是 I/O 多路复用?
I/O 多路复用是一种同步 I/O 模型,它允许单个线程同时监视多个文件描述符(FD) 。一旦某个或某些 FD 就绪(例如,有数据可读),该机制就会通知应用程序进行相应的读写操作。当没有 FD 就绪时,监视线程会阻塞,从而释放 CPU 资源。
- I/O:指内核态与用户态之间的数据交换。
- 多路:指多个客户端连接(即多个 socket)。
- 复用:指复用同一个线程来处理这些连接。
简而言之,I/O 多路复用让一个线程或进程能够同时处理成百上千个网络连接,而无需为每个连接都创建一个独立的线程。常见的实现有 select、poll 和 epoll(Linux 下性能最高)。
一个形象的比喻
想象你是一位监考老师,需要检查 30 名学生的答卷。
- 阻塞 I/O:你挨个问学生“做完了吗?”,问到A时,如果A没做完,你就一直等他,不能去问B,全班都被A卡住了。
- 为每个连接创建线程:你变出 30 个分身,每个分身盯一个学生,效率高但消耗巨大。
- I/O 多路复用(epoll 模型) :你站在讲台上,告诉学生们:“谁做完了就举手。” 你只需要等待有人举手,然后去处理举手的学生即可。这种“事件驱动”的方式就是 I/O 多路复用的精髓。
Nginx 和 Redis 都采用了类似的模型。它们将所有连接的 FD 注册到 epoll 中进行监听。epoll 就像一个高效的事件通知系统,一旦某个连接有数据到达,它会立即通知主线程去处理,主线程则像一个灵活的开关,哪个连接有事件就“拨”向哪个。
主从 Reactor 模式
在 Redis 6.0+ 的多线程 IO 模式下,IO 多路复用本身仍然是“单个线程监听多个 fd”的模式,但 Redis 通过让多个线程各自进行 IO 多路复用,实现了“多个线程各自监听多个 fd”的整体效果。这通常被称为 “多 Reactor” 模式 或 “主从 Reactor” 模式。
主线程(Main Thread / Master Reactor) :
- 负责监听新的客户端连接(
accept事件)。 - 当有新连接到来时,主线程接受连接(
accept),得到一个新的 socket fd。 - 然后,主线程会将这个新的连接 socket fd 分配给某个 IO 线程(通常是轮询分配)。
- 负责监听新的客户端连接(
IO 线程(I/O Threads / Slave Reactors) :
- 每个 IO 线程在启动后,自己运行一个独立的 IO 多路复用循环(如
epoll_wait)。 - 它们只监听被分配给自己的那一组客户端连接 socket。
- 当它负责的某个 socket 就绪(可读或可写)时,该 IO 线程就负责执行
read()或write()操作。 - 读取阶段:IO 线程读取客户端请求数据,放入一个全局队列。
- 写回阶段:IO 线程从队列中取出待发送的响应数据,写回给客户端。
- 每个 IO 线程在启动后,自己运行一个独立的 IO 多路复用循环(如
总结:Redis 为何如此快?
现在我们可以给出更全面的答案:
Redis 的高性能并非仅仅因为它是单线程或基于内存。其根本原因是一个综合体系:
- 纯内存操作:为高性能奠定了基础。
- 高效的数据结构:保证了核心操作的低时间复杂度。
- I/O 多路复用:这是其单线程模型能够处理高并发的核心技术。它让单个线程能高效地处理大量网络连接,极大地减少了网络 I/O 的时间消耗。
而在 Redis 6.0 之后,引入了多线程 I/O 来进一步优化性能。其思路是将耗时的网络数据读写和解析操作,外包给一组独立的 I/O 线程去并行处理,而命令执行这一核心部分,仍然由主线程串行执行,以保证原子性和简洁性。
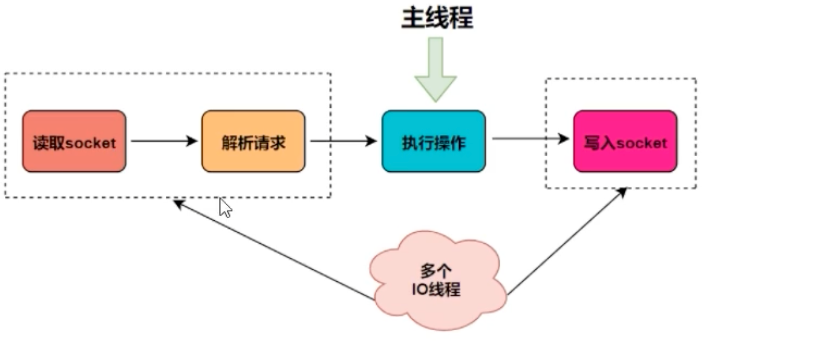
这种设计,既利用了多核 CPU 的优势解决了网络瓶颈,又保留了单线程模型简单、无锁的优点,可谓一举两得。
Redis 的高性能还受益于以下设计:
高效的数据结构(Efficient Data Structures)
Redis 不是简单地用哈希表存所有东西。它为不同场景精心选择了最合适的底层数据结构,并在运行时根据数据大小和类型进行编码优化。
例如:
-
String:小字符串用embstr编码,避免多次内存分配。 -
List:小列表用ziplist(压缩列表),大列表用quicklist(由多个 ziplist 组成的双向链表),平衡内存和性能。 -
Hash/Set/ZSet:同样有ziplist、intset、skiplist等多种编码,小对象用紧凑结构节省内存,大对象用高效结构保证操作速度。
-
这些数据结构的设计,使得
O(1)、O(log N)等操作非常高效。
非阻塞式 I/O(Non-blocking I/O)
- Redis 将所有 socket 都设置为非阻塞模式(non-blocking)。
- 结合 IO 多路复用,使得即使某个
read()或write()不能立即完成(比如网络慢),也不会阻塞整个事件循环,主线程可以继续处理其他就绪的连接。
合理的持久化策略(Controlled Persistence)
虽然持久化本身是“慢操作”,但 Redis 的设计让它对主线程的影响最小化:
- RDB:通过
fork()创建子进程来完成,父进程(主线程)继续服务。 - AOF:
append only模式写入,fsync策略可配置(如每秒一次),平衡了性能和安全性。
- RDB:通过
纯 C 语言实现
- C 语言直接操作内存,没有虚拟机或垃圾回收的额外开销,性能接近硬件极限。
何时启用多线程?
对于绝大多数公司而言,单线程的 Redis 性能已绰绰有余(通常可达 8-10 万 QPS)。但如果你在实践中发现 Redis 的 CPU 开销不高,吞吐量却上不去,那么多半是遇到了网络 I/O 瓶颈。此时,可以考虑开启 Redis 6.0/7.0 的多线程功能来提升实例的吞吐量。
在 redis.conf 中进行如下配置即可开启:
# 开启多线程 I/O
io-threads-do-reads yes
# 设置 I/O 线程数量(建议为 CPU 核心数)
io-threads 4