在Redis的主从复制架构中,虽然实现了读写分离和数据备份,但仍然存在一个致命的弱点:当Master节点宕机时,系统会失去写能力,且无法自动恢复,需要人工介入进行故障转移。为了解决这个问题,Redis引入了Sentinel(哨兵)模式。
是什么:无人值守的运维专家
Sentinel(哨兵),顾名思义,就是一位时刻巡查、监控Redis主从集群的“吹哨人”。它的核心职责是:监控后台Master主机是否故障,如果故障了,就根据投票数自动将某一个从库提升为新的主库,并通知其他从库和客户端,从而实现无人值守的自动故障转移。
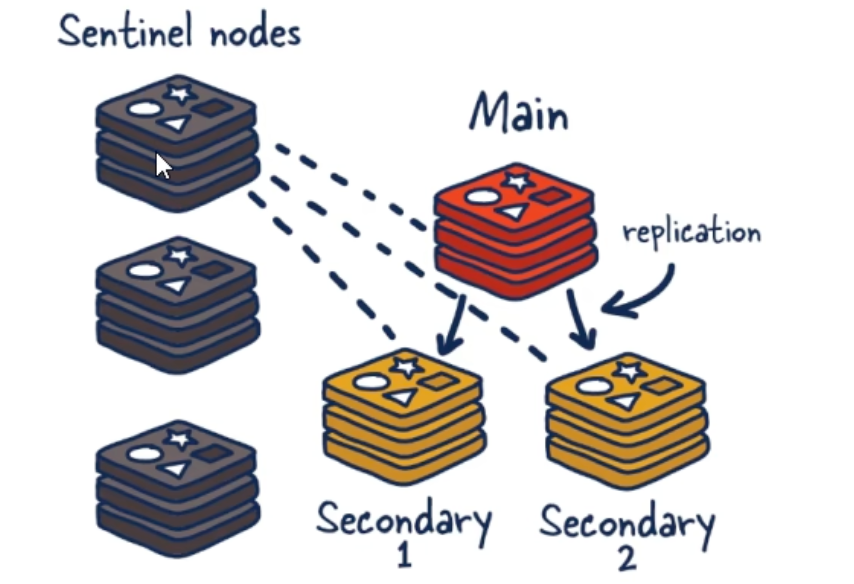
能干嘛:哨兵的四大核心职能
- 主从监控 (Monitoring) :Sentinel会持续不断地监控主库、从库以及其他哨兵节点的运行状态。
- 故障转移 (Failover) :当Master节点被判定为宕机时,Sentinel能自动在从库中选举出一个新的Master,保证集群服务的连续性。
- 消息通知 (Notification) :Sentinel可以将故障转移的结果和最新的主库地址,通知给客户端应用程序。
- 配置中心 (Configuration Provider) :客户端在初始化时,不再需要直连Redis主库,而是连接Sentinel集群。Sentinel会告诉客户端当前哪个节点是Master,从而让客户端能够动态地找到服务地址。
怎么玩:搭建一个健壮的哨兵集群
一个生产环境的哨兵部署,通常是 “一个主从集群 + 一个哨兵集群” 的模式。
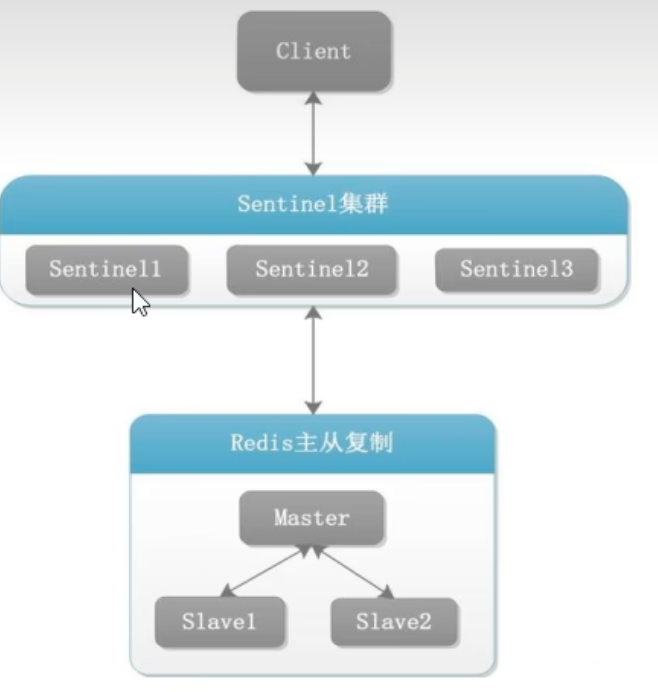
- 哨兵集群:至少部署3个哨兵节点,以形成一个健壮的、能够进行投票决策的集群。哨兵节点本身不存储任何业务数据,它们只存储监控和配置信息。
- 主从集群:典型的一主二从或更多从的结构,负责数据的读写和存储。
核心配置 (sentinel.conf )
哨兵的配置非常简洁,最核心的一行是:
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2-
<master-name>: 给被监控的主库起一个别名,如mymaster。 -
<ip> <redis-port>: 主库的地址和端口。 -
<quorum>: 法定票数。这是哨兵模式的灵魂所在。它表示,至少需要有 2 个哨兵节点都认为主库宕机了,才会将其判定为“客观下线”,并触发后续的故障转移流程。这个机制避免了因单个哨兵网络抖动而导致的误判。
其他重要配置:
-
sentinel down-after-milliseconds <master-name> <milliseconds>: 判定“主观下线”的超时时间。如果一个哨兵在指定毫秒数内没有收到主库的有效回复,它会主观上认为主库宕机了。 -
sentinel parallel-syncs <master-name> <nums>: 在故障转移后,允许多少个从库同时向新的主库同步数据。 -
sentinel failover-timeout <master-name> <milliseconds>: 故障转移操作的超时时间。
核心原理:故障转移的完整流程
当Master节点出现问题时,哨兵集群会经历一个严谨的、多阶段的流程来完成故障转移。
第一阶段:主观下线 (Subjectively Down - SDown)
- 每个哨兵节点都会独立地、周期性地向Master发送
PING命令。 - 如果在
down-after-milliseconds配置的时间内,某个哨兵没有收到Master的有效回复,它就会在自己的认知里,将Master标记为主观下线 (SDown) 。 - 此时,仅仅是这个哨兵单方面认为Master出问题了,还不会触发任何操作。
第二阶段:客观下线 (Objectively Down - ODown)
- 当一个哨兵将Master标记为SDown后,它会向其他哨兵节点发送询问命令,确认它们是否也认为Master宕机了。
- 当认为Master是SDown的哨兵数量,达到了配置文件中设置的
quorum法定票数时,Master就会被正式标记为客观下线 (ODown) 。 - ODown是一个集体共识,表明Master确实是出故障了,此时故障转移流程正式启动。
第三阶段:选举领导者哨兵 (Leader Election)
- 为了避免多个哨兵同时进行故障转移导致混乱,所有哨兵节点需要先选举出一个“领导者”(我们称之为“兵王”)。
- 选举采用的是Raft算法,其核心思想是“先到先得”。一个哨兵会向其他哨兵发送成为领导者的请求,收到的第一个请求的哨兵会投票同意。获得超过半数选票的哨兵,将成为本轮故障转移的领导者。
第四阶段:故障转移 (Failover)
现在,由选举出的“兵王”哨兵来全权负责执行故障转移,流程如下:
选出新Master:
“兵王”会从所有从库中,按照一套严格的规则选出一个最合适的节点作为新的Master。选举规则依次是:
- 优先级最高:
redis.conf中replica-priority配置值最小的从库。 - 复制偏移量最大:数据最接近原Master的从库。
- Run ID最小:如果前两者都相同,则选择运行ID最小的。
- 优先级最高:
“黄袍加身” :
- “兵王”对选出的新Master执行
SLAVEOF no one命令,使其“反客为主”,正式成为新的主库。
- “兵王”对选出的新Master执行
“改换门庭” :
- “兵王”向所有其余的从库发送
SLAVEOF <new-master-ip> <new-master-port>命令,让它们转而复制新的主库。
- “兵王”向所有其余的从库发送
“降级为奴” :
- “兵王”会继续监控那个已经宕机的旧Master。当它某天恢复上线后,“兵王”会向它发送
SLAVEOF命令,让它成为新Master的从库。
- “兵王”会继续监控那个已经宕机的旧Master。当它某天恢复上线后,“兵王”会向它发送

哨兵使用建议
- 哨兵应成集群:至少部署3个哨兵节点,以保证高可用和正确的决策能力。
- 哨兵数量应为奇数:这有助于Raft算法在选举中更容易地获得超过半数的选票。
- 哨兵配置应一致:所有哨兵节点的配置(尤其是
quorum和down-after-milliseconds)应保持一致。 - 数据丢失风险:由于主从复制是异步的,哨兵+主从复制的架构并不能保证数据零丢失。在Master宕机到故障转移完成的瞬间,可能有一小部分已写入Master但尚未同步到Slave的数据会丢失。对于需要强一致性的场景,可能需要考虑Redis Cluster。