从根源出发,为何需要 I/O 多路复用?
引言:并发连接的挑战
在构建网络服务时,我们面临的第一个,也是最核心的挑战之一,就是如何同时处理大量的客户端连接。试想一下,一个热门的社交应用、一个繁忙的电商网站,或者像 Redis 这样的高性能缓存,它们在每一秒都需要应对成千上万的并发请求。
要解决这个问题,最直观、最简单的方案是什么?—— 同步阻塞 I/O 模型。
这种模式的特点是“一个连接一个进程(或线程)”。它的工作流程非常符合人类的直线型思维,代码写起来也自然易懂。例如,当我们想从一个网络连接(socket)上接收数据时,只需调用一个 recv 函数:
int main() {
// ... socket 初始化 ...
recv(sock, ...); // 调用 recv,数据就到手了,非常简单
}优点与“致命”缺点
- 优点: 从开发者的角度来看,逻辑清晰,代码简单。调用一个函数,等待它返回,然后处理结果,一切都顺理成章。
- 缺点: 性能极其低下。想象一下,每当一个用户请求到来,服务器就必须分配一个独立的进程来专门为它服务。这就像是为每个学生都配备一位专属老师,或为每位患者都安排一名私人医生——在现实世界中这显然是不可能的。
进程是操作系统中的“重量级”资源。创建一个进程本身就有不小的开销,更不用说当成百上千的进程在运行时,操作系统需要频繁地进行上下文切换,每次切换都要耗费宝贵的微秒。一台服务器能够创建的进程数量是有限的,这种模式很快就会达到瓶颈。
结论:进程复用的必要性
为了构建能够服务海量用户的高性能系统,我们必须打破“一个连接一个进程”的桎梏,让一个进程能够同时处理成百上千甚至上万个 TCP 连接。
这时,新的问题出现了:假设一个进程真的维持了 10000 个连接,它如何知道哪个连接上有数据需要读取,哪个连接可以发送数据了呢?
最笨的办法是写一个循环,挨个去问这 10000 个连接:“你有数据吗?”、“你有数据吗?”… 这种轮询的方式不仅效率低下,而且绝大多数的询问都是无用功,极大地浪费了 CPU 资源。
我们迫切需要一种更高效的机制:当众多连接中的某一个或某几个有 I/O 事件发生时,系统能立刻、高效地通知我们。
幸运的是,Linux 操作系统早已为我们准备好了解决方案,这就是我们今天的主角——I/O 多路复用 (I/O Multiplexing) 。
拆解“I/O 多路复用”
让我们来拆解这个术语,理解其核心含义:
- I/O: 主要指网络 I/O。
- 多路 (Multi-plex): 指的是多个客户端连接,即多个 TCP 连接(在技术上表现为多个套接字描述符,socket file descriptor)。
- 复用 (Re-use): 核心在于对进程(或线程)的复用。我们不再为每个连接都创建一个新进程,而是用一个进程来管理所有的连接。
一言以蔽之,I/O 多路复用实现了用一个进程来处理海量的用户连接。它本身更像一个规范或接口,在 Linux 系统中,其具体的实现经历了 select -> poll -> epoll 三个主要阶段的演进。
这正是像 Redis、Nginx 这样的高性能软件能够以单线程(主工作线程)处理惊人并发量的核心秘密。
故事、概念与 I/O 模型的演进
在深入 select、poll 和 epoll 的技术细节之前,我们必须先厘清几个核心概念:同步与异步、阻塞与非阻塞。这些概念是理解所有 I/O 模型的基础。为了让它们不再枯燥,我们不妨从一个“吃米线”的故事开始。
一碗米线里的架构哲学
错过了饭点,我和公司的首席架构师决定去楼下的米线店解决午餐。店里人头攒动,排起了长队。
架构师开口了:“你看,这就是请求排队。这位收银员像不像一个 Nginx 反向代理?她只负责接收点单(请求),然后把做米线的任务(处理)都转发给后厨。”
我们付了钱,拿到一个号牌,找了个空位坐下。
架构师继续说:“这就是异步处理。我们下了单就可以离开柜台去干别的事(刷手机),等米线做好了,后厨会通过小喇叭‘回调’我们去取餐。如果是同步处理,那我们就得死死地守在出餐口,直到米线到手才能离开,这会把通道堵死,后面的顾客肯定都走光了。”
“还有,你看我们手里的号牌,后厨的订单上也有这个号码,这不就是用来区分不同顾客的会话 ID (Session ID) 吗?有了它,我的排骨米线才不会错送给点了番茄米线的人。”
过了一会儿,排队的人越来越多,收银员已经忙得满头大汗。
“你看,”架构师指了指,“这个点单系统缺乏弹性扩容能力。现在是高峰期,本应增加收银台,但设备和人手都不足,老板再着急也没用。”
老板见状,赶紧冲进后厨,亲自上阵做米线。
架构师又发话了:“幸好,这个系统的‘后台’具备并行处理能力,可以通过增加资源(厨师)来加快请求处理速度。不过看样子,除了老板自己,也没别的‘CPU 核心’能用了。”
不知不觉,20 分钟过去了,我们的米线还没上来。
“嗯,系统的处理能力达到上限,开始出现超时了。”架构师淡定地分析。
这时,老板做了一个决定:让负责打扫卫生的阿姨去帮忙收银,原来的收银小妹也进后厨帮忙。阿姨的收银工作磕磕绊绊,远不如小妹熟练。
“这就是服务降级,”架构师低声说,“为了保证核心业务(做米线)的产出,把次要服务(收银、保洁)的质量降低,甚至直接关闭了。”
又过了 20 分钟,后厨传来一声喊:“237号!您点的排骨米线没有排骨了,能换成番茄的吗?”
架构师对我摇摇头:“瞧,并发量太大,系统出异常了。”他站起身来,对后厨喊道:“不行!系统需要执行补偿操作:退费!”
说完,他拉着饥肠辘轆的我,头也不回地走了。
彻底厘清同步/异步与阻塞/非阻塞
问题A (关于“结果”):I/O 操作的“完整结果”由谁最终提供?
- 同步 (Synchronous) :由你的应用程序(调用者)亲自去拿。即使内核准备好了数据,也需要你的线程主动发起
read 调用才能将数据从内核拷贝到用户空间。你必须参与到“取结果”这个最终环节。 - 异步 (Asynchronous) :由内核(被调用者)直接送到你手上。你发起一个
aio_read调用后就可以彻底不管了。内核会完成所有工作(等待数据、将数据从内核拷贝到用户空间),当所有事情都搞定后,内核会通过信号或回调函数通知你:“你要的数据,已经放在你指定的内存地址了” 。你连“取结果”的动作都不需要做。
- 同步 (Synchronous) :由你的应用程序(调用者)亲自去拿。即使内核准备好了数据,也需要你的线程主动发起
问题B (关于“等待”):在等待 I/O“就绪”期间,你的线程是什么状态?
- 阻塞 (Blocking) :你的线程被挂起,进入睡眠状态,不占用 CPU。
- 非阻塞 (Non-blocking) :你的线程不被挂起,可以继续运行。如果它想知道 I/O 是否就绪,它需要自己不断地去查询。
现在,让我们用去图书馆借书的场景来解释:
| 阻塞 (Blocking) | 非阻塞 (Non-blocking) | |
|---|---|---|
| 同步 (Synchronous) | 同步阻塞 (BIO) 你跟图书管理员说:“我要《UNIX网络编程》”。然后你就站在柜台前,什么也不干,一直等到管理员把书找到并递到你手上。 | 同步非阻塞 (NIO) 你问管理员:“书好了吗?” 管理员说:“没好。” 你转身去旁边的报纸架看报纸,过一会又回来问:“现在好了吗?”… 你需要反复主动询问,直到管理员说“好了”,并把书递给你。 |
| 异步 (Asynchronous) | 异步阻塞 (理论上存在,但无意义) 你跟管理员说:“书找到了通知我”,然后你依然站在柜台前,什么也不干,干等着管理员来通知你。 | 异步非阻塞 (AIO) 你跟管理员说:“书找到了,请直接送到我家,这是地址。” 然后你就直接回家了。几天后,你收到了一个快递,书到了。你从头到尾只发出了一个指令。 |
核心区别点:
同步 vs 异步 的核心区别在于:数据从内核空间到用户空间的拷贝,是由谁来完成的?
- 同步:必须由你的应用程序自己调用
read 来触发这个拷贝。 - 异步:由内核自动完成所有事情,你只需要等待一个“全部完成”的通知。
- 同步:必须由你的应用程序自己调用
阻塞 vs 非阻塞 的核心区别在于:当数据还未就绪时,你的应用程序调用
read 会发生什么?- 阻塞:你的线程会卡住(睡眠) 。
- 非阻塞:调用会立刻返回一个错误码,你的线程不会卡住。
UNIX 网络编程中的五种 I/O 模型
了解了上述概念后,我们就可以正式审视 UNIX 系统提供的五种 I/O 模型了。
1. 阻塞 I/O (Blocking I/O - BIO)
这是最古老、最简单的 I/O 模型。当应用程序调用如 recvfrom 这样的系统调用时,整个流程分为两个阶段:
- 等待数据:内核等待网络上的数据包到达并准备好。
- 拷贝数据:内核将准备好的数据从内核空间拷贝到用户空间。
关键特点:在这两个阶段中,应用程序进程都会被完全阻塞,无法执行任何其他操作。
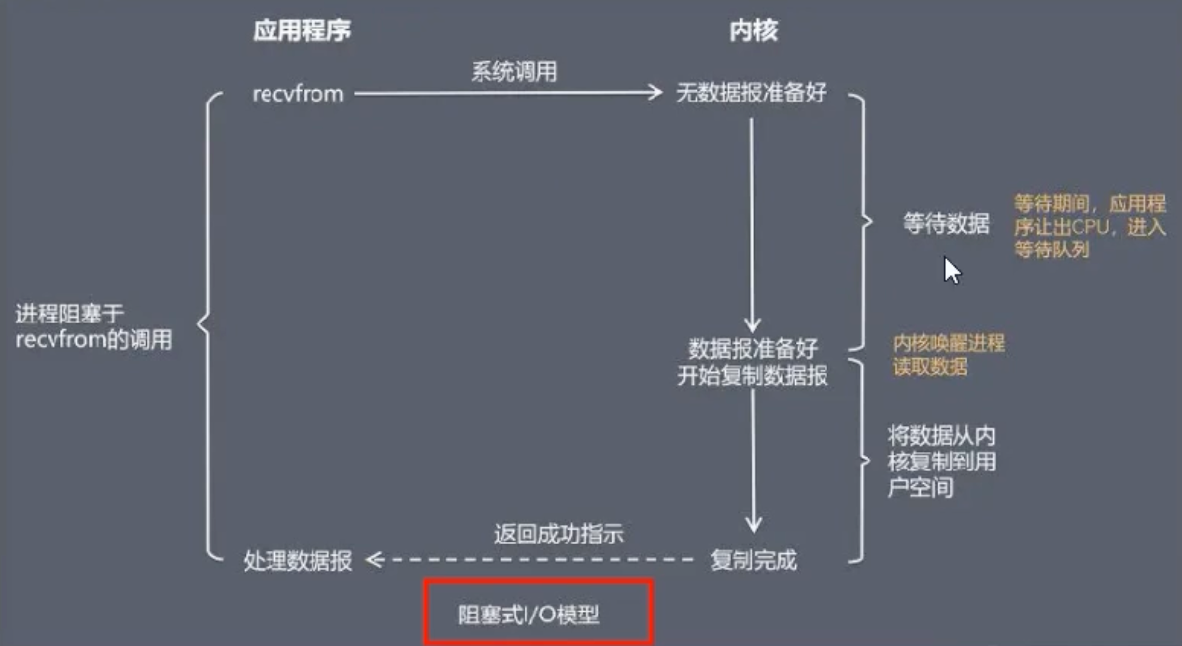
问题所在:这种模型在并发场景下是灾难性的。如果一个客户端建立了连接,但迟迟不发送数据,那么处理这个连接的服务器线程就会永远阻塞在 read() 操作上,导致其他所有客户端都无法被处理。
最初的解决方案:多线程
为了解决一个客户端阻塞整个服务的问题,人们想出了一个直接的办法:每当有新的客户端连接进来 (accept),就为它创建一个新的线程。这样,每个线程只负责一个客户端,read() 的阻塞只会影响当前线程,而不会影响主线程继续接受其他连接。
新问题:这个方案虽然解决了阻塞问题,却引入了严重的性能问题。每来一个连接就创建一个线程,如果有 1 万个连接,就要创建 1 万个线程。线程是昂贵的系统资源,频繁的创建、销毁和上下文切换会消耗大量的 CPU 和内存,服务器很快就会不堪重负。使用线程池可以缓解,但无法从根本上解决海量连接下的资源消耗问题。
2. 非阻塞 I/O (Non-blocking I/O - NIO)
为了避免被 read() 操作卡死,NIO 模型应运而生。在这种模式下,所有的 I/O 操作(如 accept, read)都是非阻塞的。
- 当调用
read()时,如果内核数据还没准备好,它不会阻塞进程,而是立即返回一个错误码 (e.g.,EWOULDBLOCK)。 - 应用程序收到这个错误码后,就知道数据还没来,它会过一会儿再试一次。
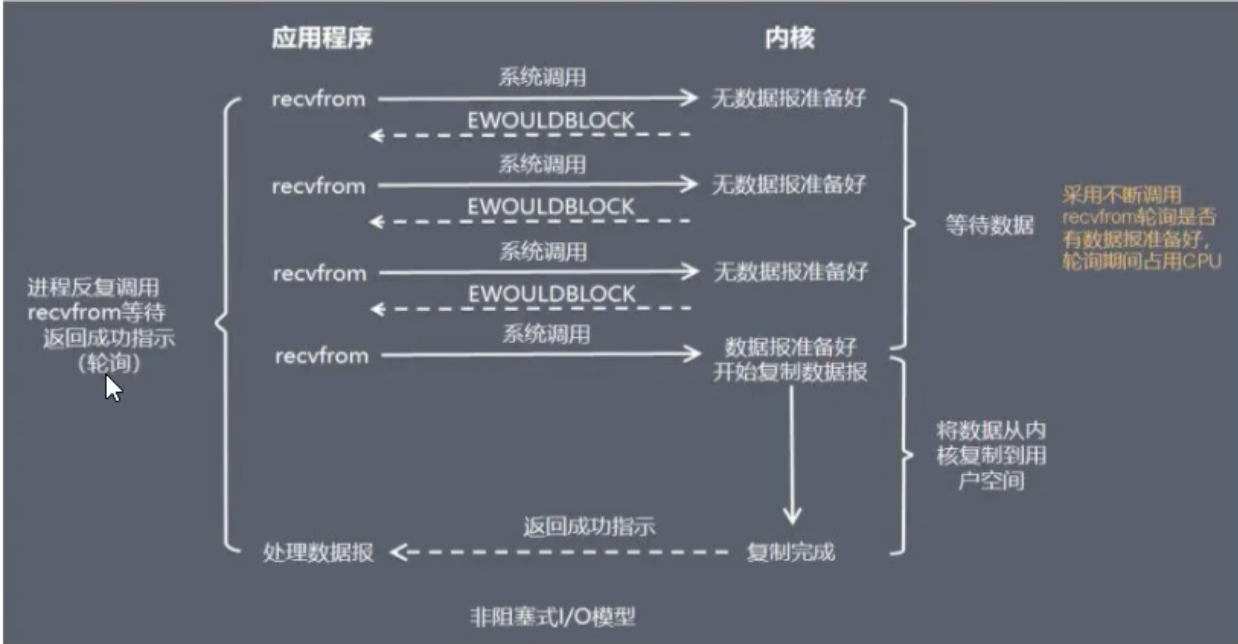
工作模式:NIO 通常在一个单线程的循环中工作。这个线程会不断地遍历所有的连接(sockets),挨个尝试 read()。
为何说NIO的“检查工作”是在用户态完成的?
要理解这一点,我们必须明确区分 “谁在做决定” 和 “谁在执行动作” 。
在非阻塞I/O(NIO)模型中,虽然最终检查数据是否到达的“动作”是由内核完成的,但 “发起检查” 、 “决定下一个检查谁” 以及 “处理检查结果” 这一整套逻辑,完全是由我们的应用程序在用户态主导的。
让我们把这个过程拆解得更细致一些,想象一下你的应用程序是一个勤奋但有点“笨”的仓库管理员(运行在用户态),而内核是仓库本身。
NIO的工作流程——管理员的“笨”循环
假设管理员需要管理10000个货柜(sockets),等待货物(数据)送达。他的工作手册(你的应用程序代码)是这样写的:
// 用户态代码 (伪代码)
List<Socket> sockets = getAllSockets(); // 获取10000个货柜的列表
while (true) { // 永不停止的循环
// 这个 for 循环,就是用户态的“笨”循环
for (Socket socket : sockets) {
// 1. 【用户态决策】管理员决定:“现在,我要检查这一个货柜!”
// 2. 【发起系统调用】管理员跑到仓库门口大喊:“报告!我要查一下X号货柜!”
// 这就是一次 read() 系统调用,是从用户态到内核态的切换。
int result = socket.read(buffer);
// 3. 【内核执行与返回】仓库(内核)查看了一下,立刻回应:
// - "没货!" (返回 EWOULDBLOCK 错误码)
// - "有货,给你!" (返回读取到的字节数)
// 4. 【用户态处理结果】管理员拿到结果。
if (result == EWOULDBLOCK) {
// "哦,没货,那算了。" 他什么也不做,继续下一步。
} else if (result > 0) {
// "太好了,有货!" 他开始处理这批货物。
processData(buffer);
}
// 循环继续,管理员走向下一个货柜,重复上述所有步骤。
}
}为什么说这个“智能”在用户态?
决策的主体是用户态程序:
for (Socket socket : sockets)这个循环,是整个工作流程的驱动核心。是你的应用程序代码在决定检查的顺序、检查的范围以及检查的频率。内核在此过程中完全是被动的,它只是一个“问询台”,你问一个,它答一个。它不会主动告诉你哪个货柜来货了。内核缺乏“全局视野” :对于每一次单独的
read()调用,内核只关心这一个socket。它不知道你接下来还要检查另外9999个,也不知道你最终的目标是什么。所有的统筹、调度和管理工作,都是由用户态的那个for循环来完成的。“笨”循环的代价:
- CPU空转:如果10000个货柜中只有1个有货,管理员依然要徒劳地跑10000趟,其中9999趟都是无用功。这导致CPU在用户态的
for循环上空转,浪费了大量的计算资源。 - 高昂的上下文切换成本:每一趟跑腿(每一次
read()调用)都伴随着一次从“办公室”(用户态)到“仓库”(内核态)的昂贵切换。10000次询问就意味着10000次切换,这个开销是惊人的。
- CPU空转:如果10000个货柜中只有1个有货,管理员依然要徒劳地跑10000趟,其中9999趟都是无用功。这导致CPU在用户态的
优点与新问题:
- 优点:成功地用一个线程处理了多个连接,避免了多线程的开销。
- 问题一(CPU 空转) :当连接数非常多(例如 1 万个),但只有少数几个是活跃的,这个线程每次循环都需要遍历全部 1 万个连接,并进行 1 万次系统调用。绝大多数的调用都是“无用功”,极大地浪费了 CPU 资源。
- 问题二(上下文切换开销) :每一次循环中的
read()都是一次系统调用,都涉及到从用户态到内核态的切换,当连接数巨大时,这个开销是惊人的。
思考:
NIO 的问题在于,检查“数据是否就绪”这个工作是在用户态由我们的应用程序通过一个“笨”循环来完成的。如果我们能把这个“遍历和检查”的工作交给更高效率的内核来完成,并且只在“真正有事发生”时才通知我们,问题不就解决了吗?
这,正是 I/O 多路复用模型的核心思想。
好的,我们进入最核心的部分。
IO多路复用“三代演进”:从Select、Poll到Epoll
在高性能网络编程的殿堂中,IO多路复用是支撑起海量并发连接的核心支柱。它的核心思想,是将 “遍历所有连接以检查其状态”这一繁重任务,从应用程序(用户态)转移到操作系统内核(内核态) 。如此一来,应用程序便无需进行低效的轮询,可以“高枕无忧”,只在内核通知它“有事可做”时才被唤醒。
为了理解这其中的奥秘,不妨想象一位聪明的监考老师,面对满教室的学生,他有三种截然不同的监考策略:
- Select 策略:老师将所有答卷的“快照”复制一份,然后反复扫描这份快照,检查谁的答卷状态发生了变化。这种方式不仅费力,而且能监考的学生数量(比如1024人)还有上限。
- Poll 策略:老师换了个更大的文件夹,可以装下任意数量的答卷快照,解决了人数上限问题。但他依然需要从头到尾完整地扫描一遍,才能发现谁完成了答卷。
- Epoll 策略:这是一种革命性的策略。老师不再扫描答卷,而是告诉所有学生:“谁做完了就举手!”。然后他便在讲台上休息,只需处理那些主动举手的学生即可。效率天差地别。
这三种策略,精准地对应了IO多路复用的三代实现:select、poll与epoll。
Reactor模式:高性能服务的“心脏”
在探讨select、poll和epoll的技术细节之前,我们必须先理解它们在Redis这样的高性能组件中是如何被应用的。Redis的网络事件处理器,正是大名鼎鼎的Reactor设计模式的经典实现。这个模式是Redis能够以单线程处理海量并发请求的关键所在。
Reactor模式包含两个核心角色:
- Reactor(反应器/调度器) :在单个线程中运行,负责监听所有事件源,并将捕获到的事件分发给对应的处理器。它如同公司的总机接线员,统一接收所有来电,再转接给相应负责人。
- Handlers(处理器) :负责执行事件关联的具体业务逻辑,是真正处理业务的“员工”。
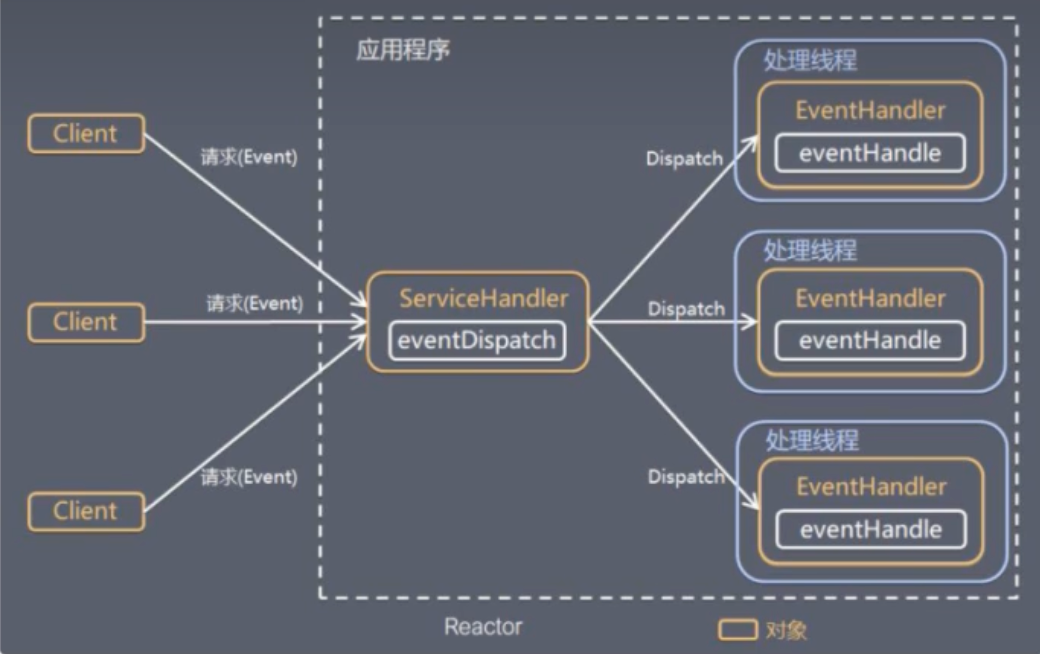
在Redis中,这一模式体现得淋漓尽致:
让我们将Redis的事件处理机制想象成一个高度协同的“中央厨房”。
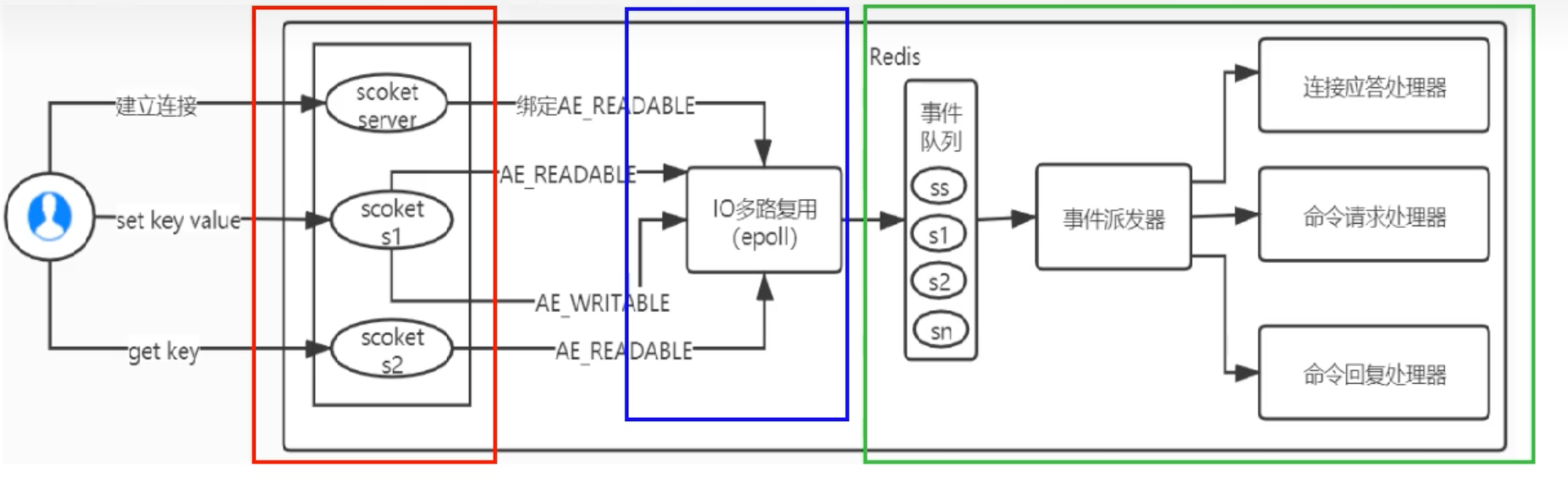
这个“厨房”有四个核心组成部分:
套接字 (Sockets) :成千上万的客户端连接,就像是成千上万个等待上菜的餐桌。每个连接在Redis内部都由一个套接字(socket)表示。
IO多路复用程序 (The Lookout) :这是厨房的“瞭望员”,由
epoll(在Linux上)、kqueue(在BSD/macOS上)或select来担当。它的职责只有一个:高效地监控所有餐桌(sockets),一旦有餐桌举手示意(有IO事件发生,如客户端发送命令),就立刻报告给“总调度”。文件事件分派器 (The Dispatcher) :这是厨房的“总调度”,也是Reactor模式的核心。它从“瞭望员”那里接收到就绪事件后,并不会自己去处理,而是根据事件的类型(是新客人来了?还是老客人点菜了?),将事件精准地派发给相应的“厨师”。
事件处理器 (The Specialists) :这些是厨房里各司其职的“专科厨师”(Handlers)。主要有:
- 连接应答处理器:专门负责迎接新客人。当一个新的客户端连接请求到来时(
accept事件),这位“厨师”就负责创建连接、初始化客户端状态。 - 命令请求处理器:专门负责处理客人的点餐。当一个已连接的客户端发送来命令时(
read事件),这位“厨师”就负责读取数据、解析命令、执行命令,并将结果准备好。 - 命令回复处理器:专门负责上菜。当有结果需要返回给客户端时(
write事件),这位“厨师”就负责将数据发送出去。
- 连接应答处理器:专门负责迎接新客人。当一个新的客户端连接请求到来时(
单线程的事件循环
现在,最关键的部分来了。Redis的“总调度”(文件事件分派器)以及所有的“专科厨师”(事件处理器),都在同一个线程中工作。这个线程永不停歇地执行一个循环,我们称之为事件循环 (Event Loop) 。
这个单线程的事件循环流程如下:
启动循环:Redis主线程启动,进入一个
while(true)的事件循环。等待事件:在循环的开始,线程会调用IO多路复用程序(比如
epoll_wait),然后阻塞在这里。此时,线程不消耗任何CPU,静静地等待“瞭望员”的信号。事件就绪:当一个或多个客户端有活动时(例如,发送
SET key value命令),epoll_wait会解除阻塞,并返回一个包含所有就绪socket的列表。分派与处理:事件循环线程被唤醒,它会遍历这个(通常很短的)就绪列表。
- 对于每一个就绪的socket,它会查看是哪种事件(读?写?)。
- 如果是读事件,“总调度”就会调用“命令请求处理器”。
- 这位“厨师”在当前线程中,立刻开始工作:读取socket中的数据 -> 解析出
SET key value命令 -> 在内存中执行这个命令 -> 将结果"OK"放入该客户端的回复缓冲区。
循环往复:处理完所有就绪事件后,事件循环回到第2步,再次调用
epoll_wait,等待下一批事件的到来。
为什么单线程反而快?
至关重要的是,文件事件分派器消费事件队列以及所有处理器执行任务的动作,都是在这个单线程中有序进行的。这正是我们常说Redis是“单线程模型”的核心所在。这种设计带来了巨大的好处:
- 避免了锁竞争:由于所有的数据操作(如对内存中键值对的读写)都在一个线程中完成,完全不存在多个线程同时修改一个数据的可能。这使得Redis可以完全避免多线程编程中复杂的锁机制(如互斥锁、自旋锁),极大地提升了执行效率。
- 上下文切换开销极小:单线程模型避免了多线程之间频繁的上下文切换,这些切换会消耗宝贵的CPU周期。
- 代码简洁,易于维护:单线程的逻辑使得代码更简单,更容易开发和维护。
现在,让我们深入探索驱动这颗“心脏”的动力源,并通过内核伪源码来揭示它们的工作机理。
第一代:select (1983年)
select 使用一个名为 fd_set 的数据结构,你可以把它想象成一个位图 (bitmap),其中每一位 (bit) 对应一个文件描述符 (File Descriptor, fd)。

内核视角:sys_select 伪源码分析
// 内核中的 select 实现逻辑
int sys_select(int nfds, fd_set *readfds, ...) {
// 1.【开销点1】将用户空间的 fd_set 完整拷贝到内核空间
fd_set *kernel_fds = copy_from_user(readfds, nfds);
int res = 0;
for (;;) {
// 2.【开销点2】在内核中进行 O(n) 的线性遍历
for (int i = 0; i < nfds; i++) {
if (FD_ISSET(i, kernel_fds)) {
// 检查 fd 是否就绪,并注册当前进程到 fd 的等待队列
if (fd[i]->poll(wait_queue)) {
res++; // 发现就绪事件
FD_SET(i, res_fds); // 标记就绪
}
}
}
if (res > 0 || timeout) break; // 有事件或超时则跳出
// 3. 没有任何事件,进程进入睡眠,等待被唤醒
schedule();
}
// 4.【开销点3】将结果 fd_set 再次完整拷贝回用户空间
copy_to_user(readfds, res_fds, nfds);
return res;
}select 的四大硬伤:
通过源码,我们能清晰看到问题所在:
- 硬性连接数上限:
fd_set的大小由FD_SETSIZE宏限制,通常为1024。 - 昂贵的双重拷贝:每次调用,
fd_set都要在用户态和内核态之间来回完整拷贝。 - O(n)的线性扫描:内核中必须对所有fd进行完整遍历。
- 状态重置:
fd_set会被内核修改,每次循环前都必须重新设置所有fd。
第二代:poll (1997年)
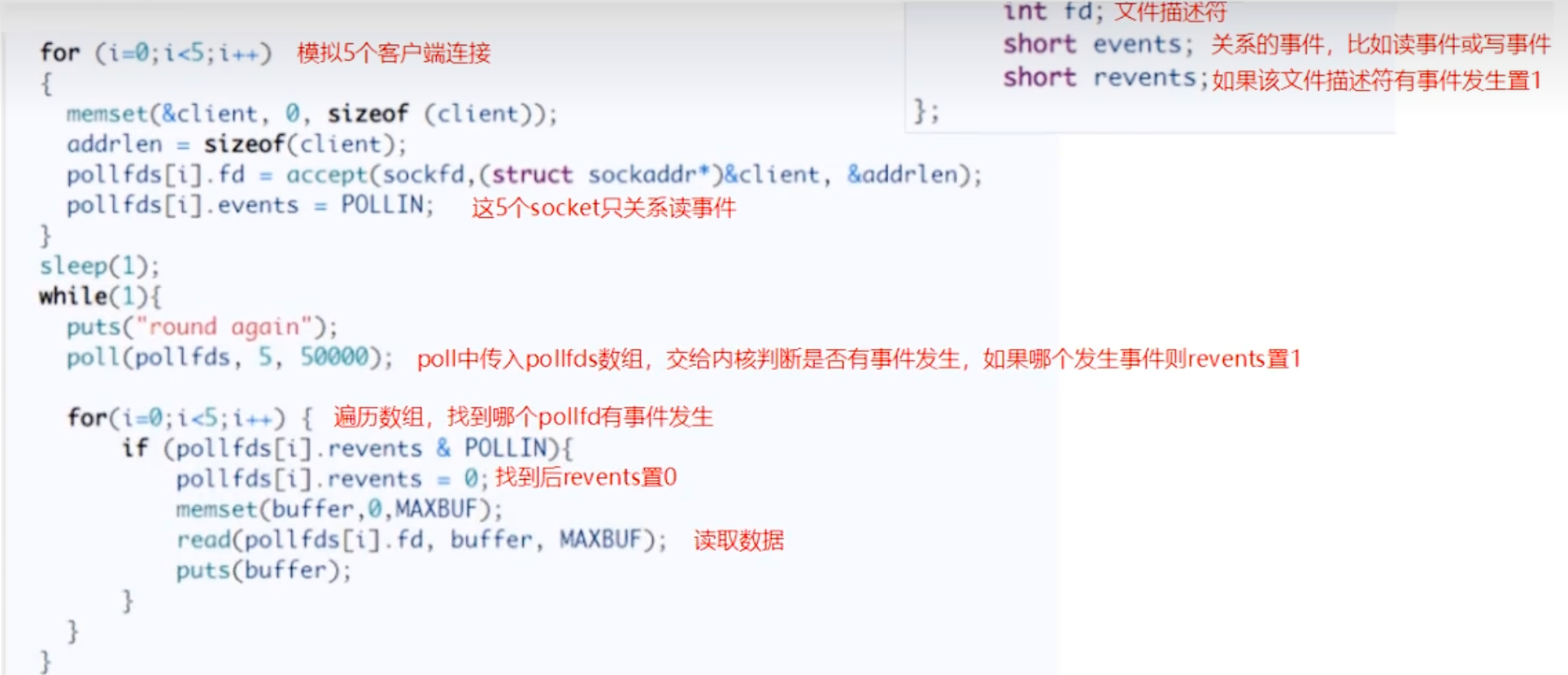
poll 使用 struct pollfd 数组替代了 fd_set,解决了连接数限制和状态重置的问题,但其核心的“遍历”思想并未改变。
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 期望监听的事件 */
short revents; /* 内核返回的实际事件 */
};
内核视角:sys_poll 伪源码分析
// 内核中的 poll 实现逻辑
int sys_poll(struct pollfd *fds, nfds_t nfds, ...) {
// 1.【开销点1】将整个 pollfd 数组从用户态拷贝到内核态
// 这是一个 O(n) 的开销
struct pollfd *kernel_fds = copy_from_user(fds, nfds);
int res = 0;
for (;;) {
// 2.【开销点2】在内核中进行 O(n) 的线性遍历
for (int i = 0; i < nfds; i++) {
// 调用 fd 对应的 poll 方法检查是否就绪
int mask = kernel_fds[i].fd->poll(wait_queue);
if (mask & kernel_fds[i].events) {
kernel_fds[i].revents = mask; // 记录发生的事件
res++;
}
}
if (res > 0 || timeout) break;
// 3. 没有任何事件,进程进入睡眠
schedule();
}
// 4.【开销点3】将包含 revents 结果的数组再次完整拷贝回用户空间
copy_to_user(fds, kernel_fds, nfds);
return res;
}poll 的改进之处:
- 解决了连接数限制:
pollfd数组的大小是动态的,不再有 1024 的硬性限制,理论上只受限于系统内存。 - 结构更清晰:
events字段(我们期望的事件)和revents字段(实际发生的事件)是分开的,每次调用后只需要检查revents字段,而events字段无需重置,可以复用。
poll 仍然存在的问题:
poll 仅仅是换了一种数据结构,其核心工作模式与 select 几乎一样。
- 重复的内存拷贝:每次调用
poll,仍然需要将整个pollfd数组从用户态拷贝到内核态。 - O(n) 的时间复杂度:
poll返回后,应用程序依然需要遍历整个pollfd数组,检查每个元素的revents字段,以找出就绪的 fd。
总的来说,poll 只是对 select 的小修小补,并没有从根本上解决性能瓶颈。
第三代:epoll (2002年,Linux 特有)
epoll 是对 select 和 poll 的一次彻底颠覆,它引入了全新的事件驱动思想,将 O(n) 的操作彻底消灭。
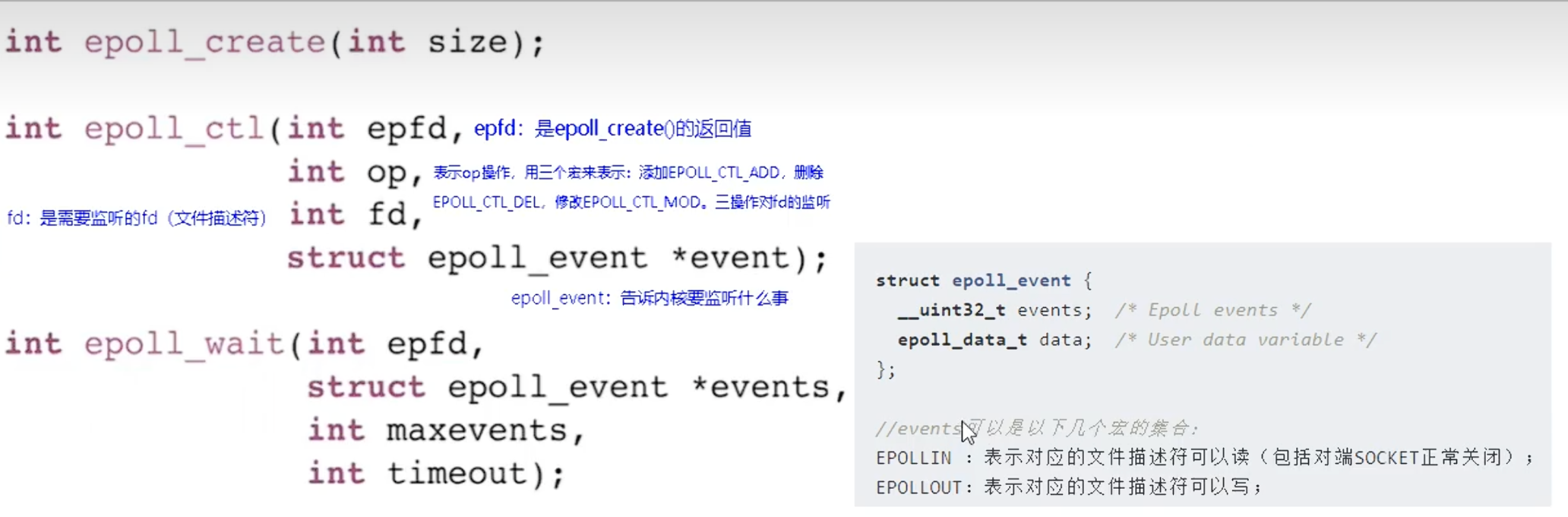
epoll 的三大核心操作与内核实现:
epoll_create(int size) :创建事件中心内核会创建一个
eventpoll对象。它内部包含两个关键数据结构:- 红黑树 (
rbr ) :用来高效地存储和查找所有被监视的fd。 - 就绪链表 (
rdllist ) :用来存放已经就绪的fd。
- 红黑树 (
epoll_ctl(epfd, op, fd, ...) :注册事件与回调
epoll_ctl是epoll机制的“管家”,负责动态地、精准地管理“事件中心”所监控的fd列表。它不像select或poll那样每次都需要传递整个列表,而是按需进行增、删、改操作。
epfd:epoll_create返回的句柄。
op: 要执行的操作,主要有三种:-
EPOLL_CTL_ADD:添加一个新的fd到监控列表。 -
EPOLL_CTL_MOD:修改一个已存在fd的监听事件(例如,从只关心读事件,变为同时关心读和写事件)。 -
EPOLL_CTL_DEL:删除一个fd,不再对其进行监控。
-
fd: 要操作的目标文件描述符。
event: 一个结构体,告诉内核我们关心这个fd上的哪些事件(如EPOTLLIN代表可读,EPOLLOUT代表可写)。
epoll_ctl 的内核优化:- 一次性拷贝:当使用
EPOLL_CTL_ADD添加一个新的fd时,内核会将这个fd及其相关的事件数据从用户态拷贝到内核态一次。这些信息会被封装成一个epitem对象,并插入到“事件中心”的红黑树中。此后,只要不删除这个fd,就再也无需重复拷贝。这从根本上解决了select和poll每次调用都必须完整拷贝fd集合的巨大开销。 - 注册回调函数(核心机制) :这是
epoll事件驱动模型的心脏。在将epitem插入红黑树的同时,内核会找到该fd对应的设备驱动程序(例如网卡驱动),并在其“等待队列”上注册一个回调函数。这个回调函数的功能非常专一和高效:“一旦这个fd的数据准备就绪(例如,网卡收到数据包),请立即把我(这个 epitem )添加到 eventpoll 的就绪链表 rdllist 中,并唤醒正在等待的进程。 ”
通过
epoll_ctl,我们将监控任务完全委托给了内核,并建立了一套高效的、由硬件中断驱动的通知机制。
epoll_wait(epfd, ...) :等待事件的发生。这个调用会阻塞,直到有 fd 就绪。
// 内核中的 epoll_wait 实现逻辑
int sys_epoll_wait(int epfd, struct epoll_event *events, ...) {
// 获取 epoll 实例
struct eventpoll *ep = get_epoll_instance(epfd);
for (;;) {
// 1.【O(1) 检查】直接检查就绪链表是否为空
if (!list_empty(&ep->rdllist)) {
// 2.【O(k) 拷贝】如果不为空,直接将链表中的 k 个就绪事件
// 拷贝到用户空间的 events 数组中
int k = copy_to_user(events, ep->rdllist);
return k; // 返回就绪的数量
}
if (timeout) break;
// 3. 链表为空,进程睡眠,等待被回调函数唤醒
schedule();
}
return 0;
}
epoll 的革命性优势:
- 内存共享,避免重复拷贝:
fd只需在epoll_ctl时拷贝一次到内核。epoll_wait调用时,无需拷贝任何 fd 集合。 - 事件驱动,O(1)的非凡效率:这是
epoll的精髓。内核不再主动轮询,而是被动等待回调。epoll_wait的工作仅仅是检查就绪链表,其时间复杂度为 O(1) ,与监控的总连接数无关! - 按需索取,无需遍历:
epoll_wait直接返回就绪列表。应用程序只需处理返回的这几个fd即可,彻底告别了无效的全局遍历。
三代演进总结
| 特性 | select | poll | epoll |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 (事件驱动) |
| 底层数据结构 | 位图 (bitmap) | 数组 | 红黑树 + 就绪链表 |
| 最大连接数 | 有限 (1024) | 无上限 | 无上限 |
| FD 拷贝 | 每次调用都完整拷贝 | 每次调用都完整拷贝 | 仅 epoll_ctl 时拷贝一次 |
| 效率 | O(n),随连接数增加而下降 | O(n),随连接数增加而下降 | O(1),不随连接数变化 |
| 适用场景 | 连接数少且固定的场景 | 同 select | 高并发、海量连接场景 |
一句话总结:IO多路复用通过将“检查”工作交给内核来提升效率。而epoll的革命性在于,它将内核的“检查”方式从 “费力的 O(n) 轮询” 升级为了 “高效的 O(1) 事件回调” ,从而实现了质的飞跃。
结论
NIO的“笨”,在于它将 “发现就绪事件” 这一本该由操作系统高效完成的统筹工作,强行放在了用户态,通过一个简单、暴力但开销巨大的循环来完成。而IO多-路复用,特别是epoll,则是将这份“智能”交还给了最擅长做这件事的内核,从而实现了从“我挨个问”到“你主动告诉我”的根本性转变,带来了性能上的巨大飞跃。
select, poll, epoll 本质上都属于同步非阻塞 I/O。因为当 epoll_wait 通知你某个 socket 就绪时,你仍然需要自己调用 read 函数去把数据从内核拷贝到用户空间,所以它是同步的。而在你调用 epoll_wait 等待事件时,你的线程是阻塞的(但可以设置超时使其非阻塞),它是在等待“就绪”这个事件,而不是在等待“数据本身”。