随着业务量的增长,单台Redis实例很快会面临性能瓶颈和单点故障的风险。如何扩展Redis的读写能力?如何保证服务的高可用?答案就是主从复制 (Master-Slave Replication) 。
是什么:主从复制的核心思想
一句话概括:主从复制,就是让一台Redis服务器(我们称之为主库Master),自动地、异步地将数据同步到其他一台或多台Redis服务器(我们称之为从库Slave)。
这种架构带来了两大核心优势:
- 读写分离:Master节点专注于处理写操作,而Slave节点则可以分担大量的读操作。这极大地提升了Redis的并发处理能力。
- 高可用性:当Master节点意外宕机时,可以将其中一个Slave节点提升为新的Master,从而保证服务的持续可用,实现了数据的热备份。
怎么玩:轻松搭建主从集群
配置主从关系非常简单,核心原则是 “配从不配主” ,即所有的配置都在从库上进行。
1. 配置文件方式(推荐)
在从库的 redis.conf 文件中,添加或修改以下配置:
# 指定主库的IP和端口
slaveof <master_ip> <master_port>
# 如果主库设置了密码 (requirepass),从库必须配置此项
masterauth <master_password>例如:
slaveof 192.168.1.100 6379
masterauth "your_strong_password"配置完成后,重启从库即可自动建立主从关系。
2. 命令行方式(临时生效)
也可以在Redis客户端中动态设置主从关系,但这只在当前运行期间有效,重启后会失效。
# 让当前实例成为指定主库的从库
127.0.0.1:6380> SLAVEOF 192.168.1.100 6379
# 让当前实例“自立为王”,断开主从关系,变回主库
127.0.0.1:6380> SLAVEOF no one常用命令:
-
INFO replication: 查看当前节点的主从状态、连接信息和复制进度。
主从复制的N个“灵魂拷问”
从库可以执行写命令吗?
- 不可以。默认情况下,从库是只读的 (
read-only)。尝试在从库上执行写命令会收到错误提示:(error) READONLY You can't write against a read only replica.。这是为了保证数据的一致性,所有写操作都必须源自Master。
- 不可以。默认情况下,从库是只读的 (
从库是从什么时候开始复制的?
- 首次全量,后续增量。当一个从库首次连接上主库时,会进行一次“全量复制”,将主库当时所有的数据都复制过来。此后,主库上发生的任何写操作,都会被“增量”地同步到从库。即使一个从库在中途加入,它也能通过全量复制,赶上“大部队”。
主库宕机了,从库会自动“上位”吗?
- 不会。在单纯的主从复制模式下,如果主库宕机,所有从库会原地待命,继续提供读服务,但整个集群将失去写能力。它们会不断尝试重连主库,直到主库恢复。自动故障转移需要更高级的“哨兵模式”或“集群模式”来实现。
主库重启后,主从关系还在吗?
- 在的。只要配置写入了
redis.conf,主库重启后,从库会自动重连上来,并根据复制积压缓冲区的数据进行增量同步,恢复主从关系。
- 在的。只要配置写入了
从库宕机后重启,能跟上进度吗?
- 可以。从库重启后,会重新连接主库。它会告诉主库自己宕机前的复制偏移量(offset)。主库会检查这个offset是否还在自己的“复制积压缓冲区”内,如果在,就直接发送这部分丢失的数据(类似断点续传);如果不在(宕机时间太长),则会触发一次全量复制。
更灵活的架构
- 薪火相传(Chaining)
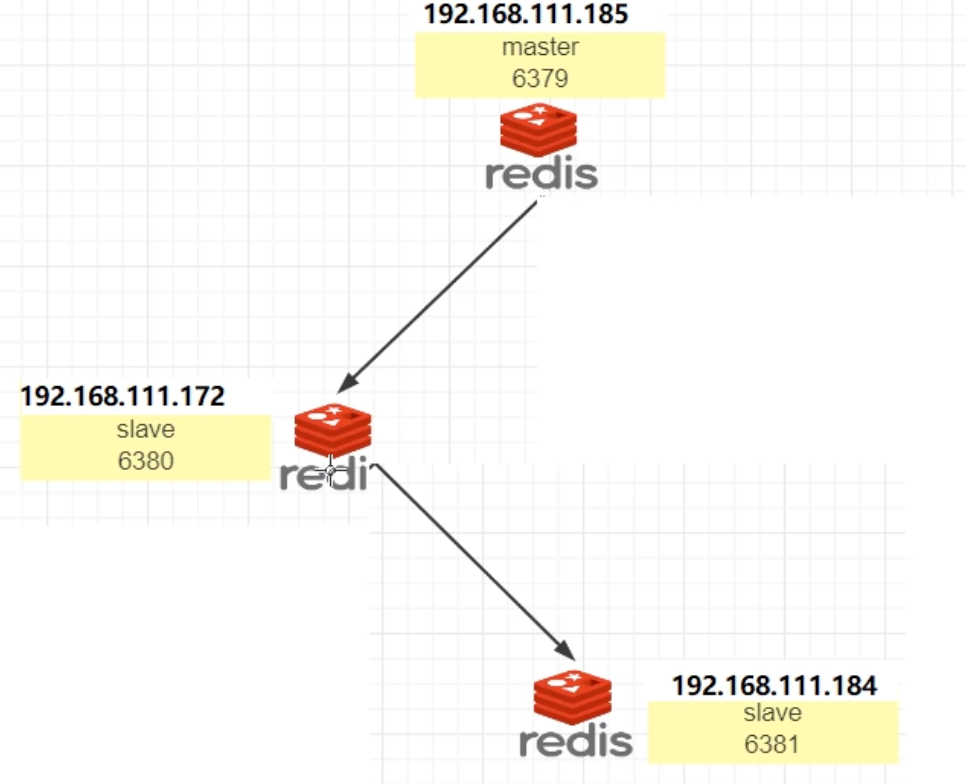
一个从库也可以成为另一个从库的主库。这样可以形成一个链式结构:Master -> Slave1 -> Slave2。这种架构可以有效减轻主Master的同步压力,因为Master只需要同步给Slave1即可。 - 反客为主
当主库永久性宕机,需要手动将一个从库提升为新主库时,只需在该从库上执行SLAVEOF no one命令即可。然后让其他从库转而复制这个新的主库。
核心原理:复制的三大阶段
Redis主从复制的过程,主要分为三个阶段:
第一阶段:全量复制 (Full Resynchronization)
当从库初次连接主库,或因断线时间过长导致数据差异巨大时,会触发全量复制。
- SYNC命令:从库向主库发送
SYNC命令。 - RDB快照:主库收到
SYNC后,会立即在后台执行BGSAVE,生成一份当前内存数据的RDB快照文件。在生成RDB期间,所有新的写命令会被缓存起来。 - 发送数据:主库将生成的RDB文件发送给从库。发送完毕后,再将缓存的写命令也发送给从库。
- 加载数据:从库接收到RDB文件后,会** 清空自己的所有旧数据 **,然后加载RDB文件到内存。之后,再执行主库发来的缓存写命令。至此,主从数据达到一致。
第二阶段:增量复制 (Continuous Replication)
全量复制完成后,主从进入平稳的增量复制阶段。
- 主库每执行一个写命令,都会异步地将这个命令发送给所有从库。
- 从库接收到命令后,在自己的数据库中执行,从而保持与主库的数据同步。
第三阶段:心跳与断线重连
- 心跳机制:主从之间会周期性地(默认10秒)发送
PING命令,以检测连接状态和维持通信。 - 断点续传:如果从库短暂断线后重连,它会利用复制偏移量(offset) 和复制积压缓冲区(replication backlog) 来实现高效的增量同步,避免了昂贵的全量复制。主库只会把从库断线期间错过的命令重新发送给它。
主从复制的挑战
- 复制延迟:由于写操作是先在Master执行,再异步同步到Slave,所以存在一定的延迟。在高并发场景下,延迟可能会加剧。这可能导致在从库上读到的是旧数据。
- Master的单点故障:在没有哨兵或集群的情况下,Master宕机会导致整个系统无法写入,需要人工介入进行故障转移。
结论:主从复制是构建高可用、高性能Redis服务的基石。虽然它存在一些固有的挑战,但这为更高级的哨兵和集群模式铺平了道路,是理解Redis分布式架构不可或缺的一环。