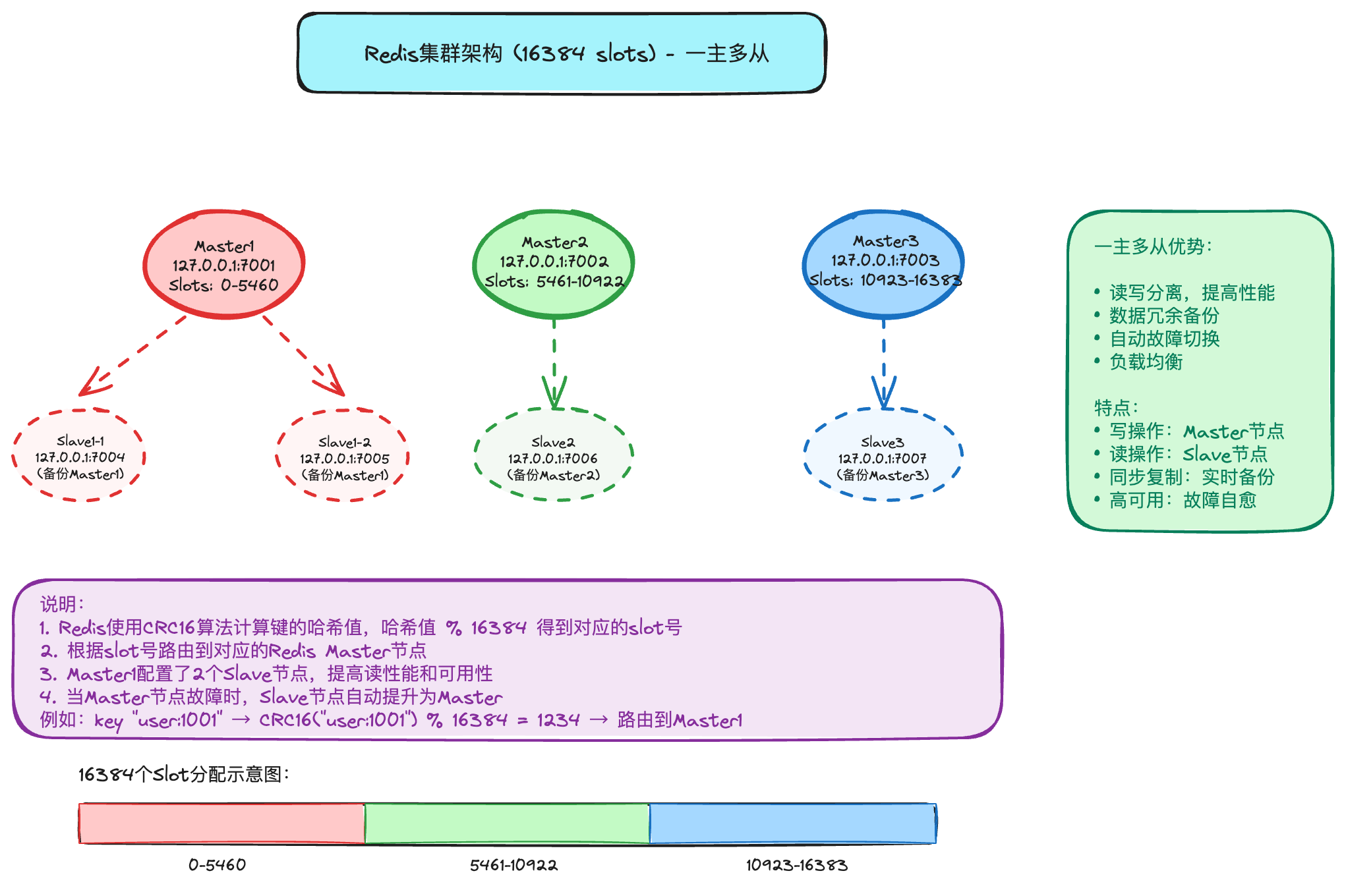
为什么需要 Redis 集群?
在现代应用中,数据量和并发量日益增长,单个 Redis Master 节点常常会遇到性能瓶颈。当数据量过大,单个 Master 副本集难以承担时,我们就需要一种能够水平扩展的方案。这便是 Redis 集群(Redis Cluster)的用武之地。
Redis 集群的核心思想是将数据分散存储在多个节点上,每个节点(或每个副本集)只负责存储整个数据集的一部分。通过这种方式,集群提供了一个在多个 Redis 节点间共享数据和协同工作的程序集,极大地提升了 Redis 的可扩展性和可用性。
Redis 集群的核心优势
Redis 集群并非简单地将多个 Redis 实例聚合在一起,它提供了一套完整的高性能、高可用分布式解决方案。
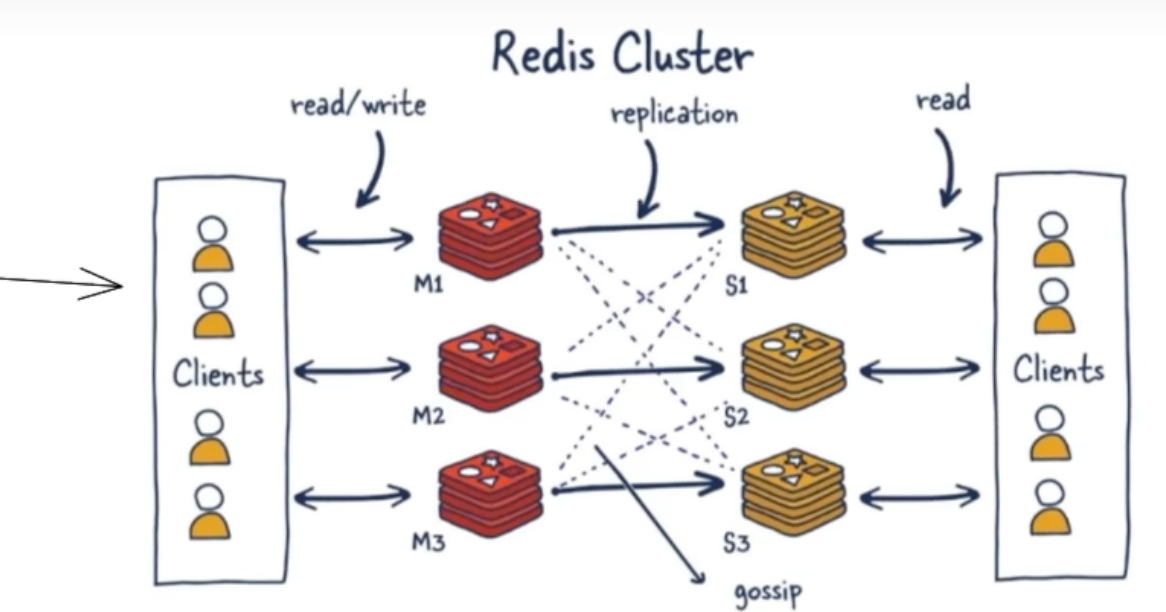
- 高可扩展性:集群支持多个 Master 节点,每个 Master 节点都可以处理读写请求,从而将数据和负载分散到不同节点上,实现了海量数据的读写存储操作。
- 高可用性:每个 Master 节点都可以挂载多个 Slave 节点。当某个 Master 发生故障时,集群内部的故障转移机制(类似于 Sentinel)会自动将其中一个 Slave 提升为新的 Master,确保服务的连续性。因此,部署 Redis 集群后无需再单独部署哨兵(Sentinel)功能。
- 简化的客户端连接:客户端与 Redis 集群交互时,不再需要维护一个包含所有节点的连接池。只需要连接集群中的任意一个可用节点,客户端便能感知到整个集群的拓扑结构,并自动将请求路由到正确的节点。
- 数据分片与管理:集群通过“槽位(slot)”机制来负责将数据分配到各个物理服务节点。整个集群共同负责维护节点、槽位和数据之间的映射关系。
业界常见的三种分区方案对比
为了更好地理解哈希槽的精妙之处,我们来对比一下业界常见的三种分布式数据分区方案。
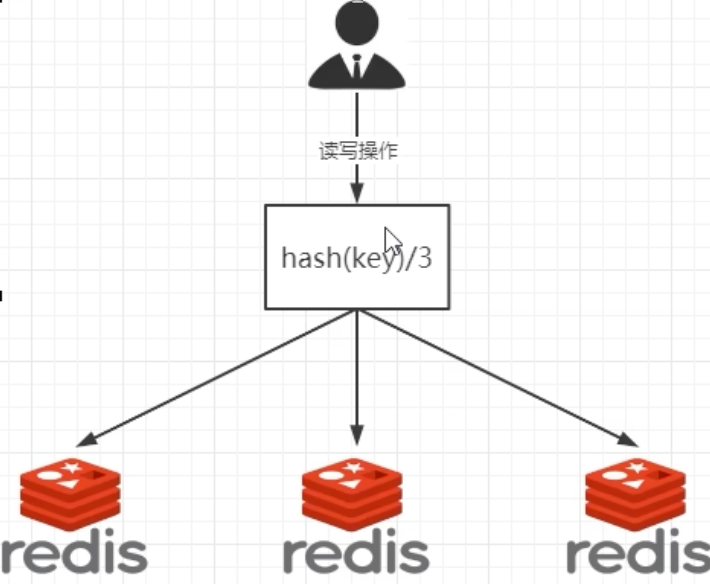
1. 哈希取余分区(Hash Modulo)
这是最简单直接的方案。假设我们有 2 亿条记录和 3 台机器,每次读写操作都通过以下公式来决定数据映射到哪个节点:hash(key) % N(N 为机器台数)。
优点:
- 实现简单粗暴,直接有效。
- 在节点数量固定的情况下,能够很好地将请求负载均衡到不同服务器上。
缺点:
- 扩展性差。一旦需要扩容或缩容,节点的数量 N 发生变化,取模公式
hash(key) % N的计算结果也会随之改变。这会导致几乎所有的数据都需要重新映射和迁移,引发大规模的数据“洗牌”,对系统造成巨大压力。例如,如果某台机器宕机,台数变化会导致所有数据映射关系失效。
- 扩展性差。一旦需要扩容或缩容,节点的数量 N 发生变化,取模公式
2. 一致性哈希算法分区(Consistent Hashing)
为了解决哈希取余分区在节点变动时带来的问题,麻省理工学院在 1997 年提出了一致性哈希算法。其设计目标是,当服务器数量发生变动时,能尽量减少受影响的数据。
算法原理
构建哈希环:
一致性哈希将整个哈希空间(例如0到2^32 - 1)想象成一个首尾相连的虚拟圆环。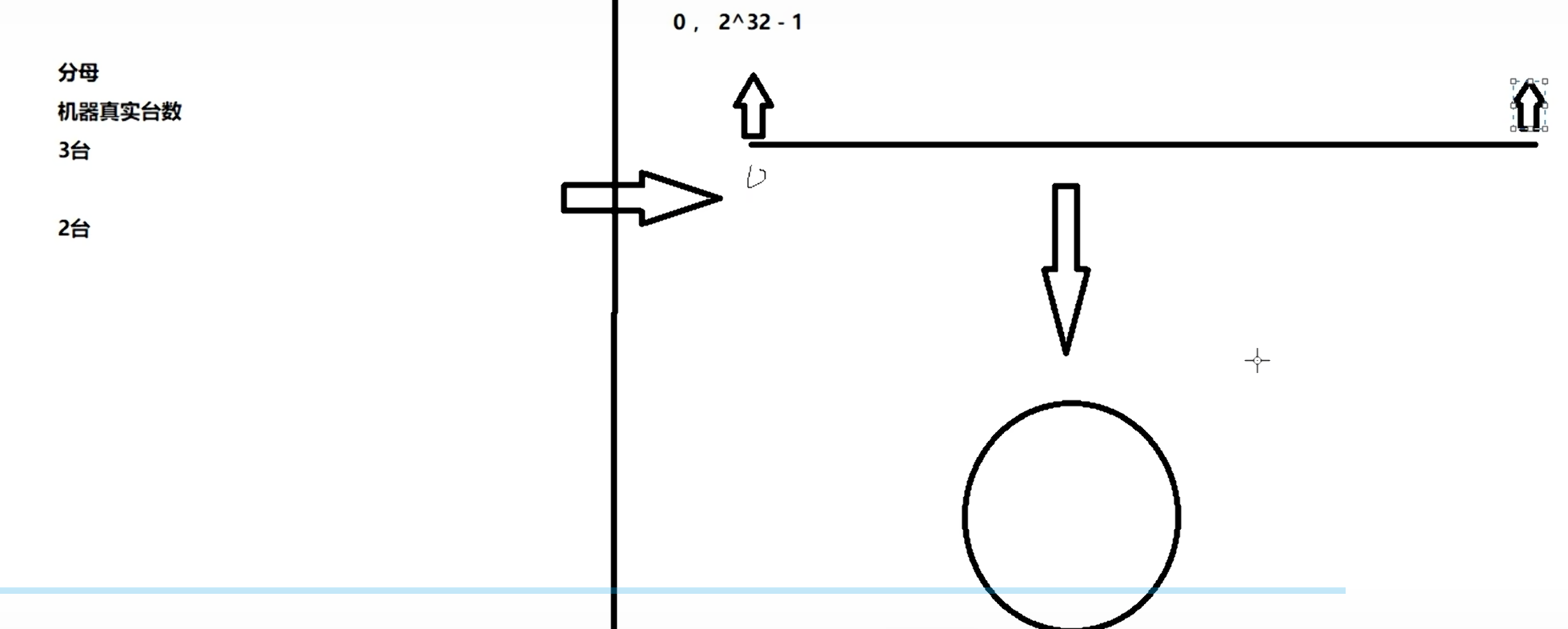
节点映射:
将集群中的每个节点(例如,通过其 IP 地址或主机名计算哈希值)映射到哈希环上的一个具体位置。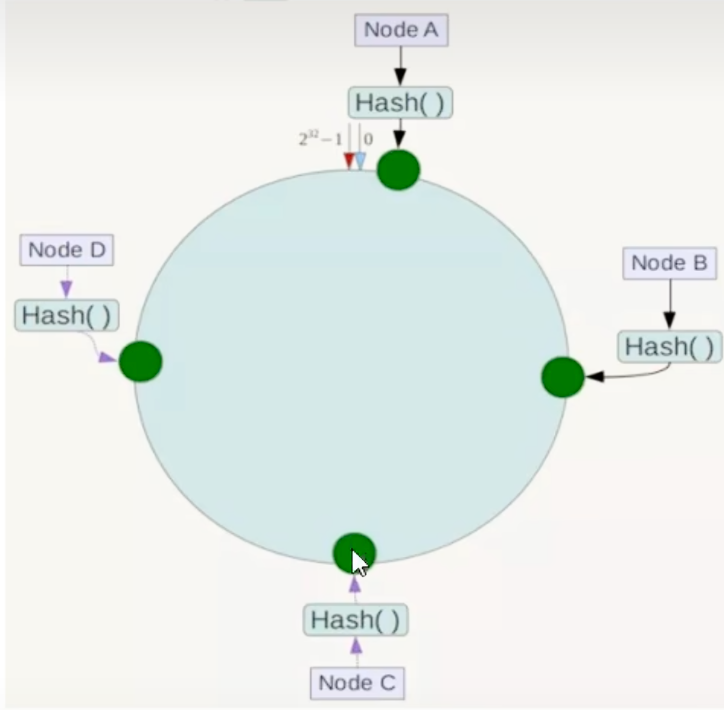
键值映射规则:
当需要存储一个键值对时,首先计算键的哈希值,将其定位到环上。然后,从此位置沿环顺时针方向“行走” ,遇到的第一个节点就是负责存储该键值对的目标服务器。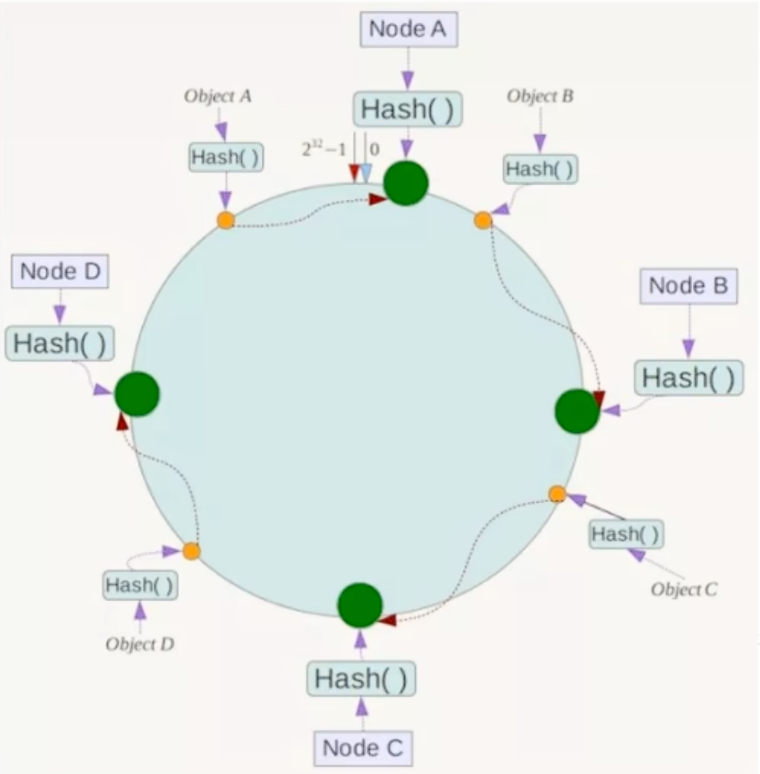
优点
- 良好的容错性:如果节点 C 宕机,只有原本存储在 C 上的数据会受到影响。这些数据现在会顺时针找到下一个节点 D 进行存储,而 A 和 B 节点上的数据不受任何影响。
- 优秀的扩展性:如果增加一个新节点 X(位于 A 和 B 之间),那么只有原本应该存储在 B 但位置在 X 之后的数据会受到影响,需要迁移到 X,而不会导致所有数据重新洗牌。
缺点
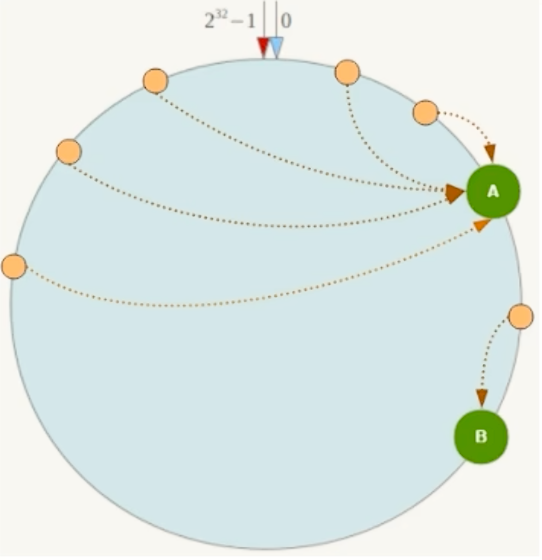
数据倾斜问题:当服务节点数量较少时,节点在哈希环上的分布可能不均匀,这容易导致数据倾斜——即大部分数据集中存储在某一台服务器上,造成负载不均。
3. 哈希槽分区(Redis 的选择)
为了解决一致性哈希可能带来的数据倾斜问题,Redis 引入了哈希槽。
核心思想:
哈希槽在数据和节点之间增加了一个中间层。它不再是key -> node的直接映射,而是key -> slot -> node的映射。哈希槽的本质是一个拥有 16384 个位置的数组。
工作流程:
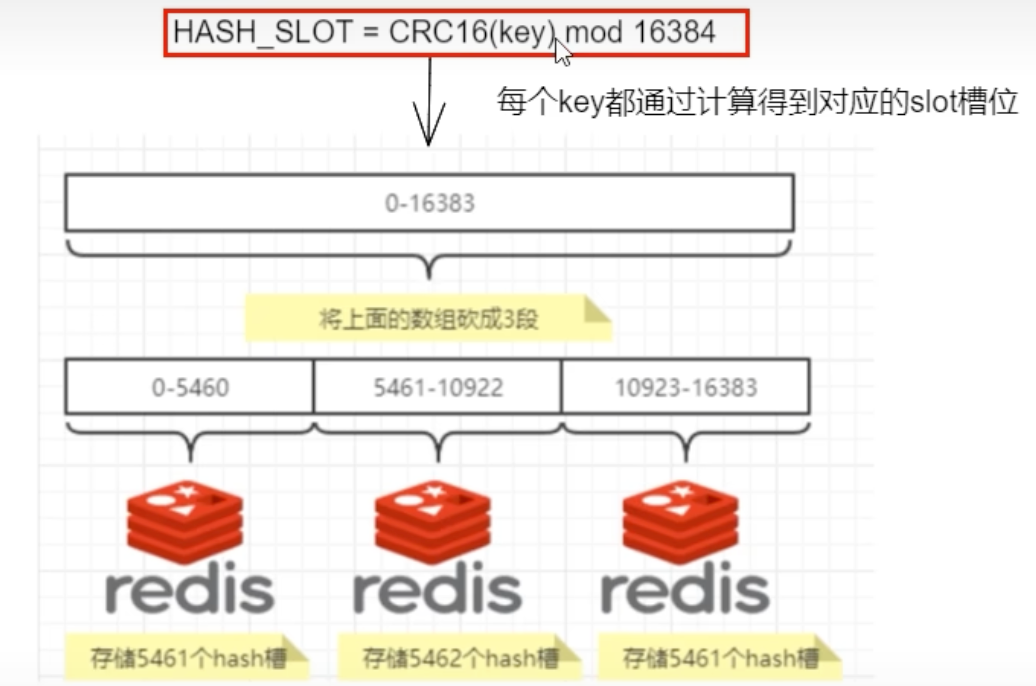
- 计算键的哈希值并对 16384 取模,确定其所属的槽位:
HASH_SLOT = CRC16(key) % 16384。 - 查找该槽位由哪个节点负责。
- 将键值对存取到对应的节点上。
- 计算键的哈希值并对 16384 取模,确定其所属的槽位:
优势:
- 解耦数据和节点:槽作为中间层,使得数据和节点之间的关系不再是强绑定的。节点的增减只需改变槽与节点之间的映射关系,而无需大规模移动数据本身。
- 简化数据移动:数据移动以槽为单位。例如,要将 100 个槽从节点 A 移动到节点 B,只需更新集群元数据,指明这 100 个槽现在由 B 负责,然后异步地将这些槽内的数据从 A 迁移到 B。这个过程对客户端是透明的。
数据分片(Sharding)
当我们使用 Redis 集群时,数据会被分散到多台 Redis 机器上,这个过程称为分片(Sharding) 。简而言之,集群中的每个 Redis 实例(Master)都被视为整个数据集的一个分片。
那么,集群如何确定一个给定的键(key)应该存储在哪个分片上呢?它并不是采用传统的一致性哈希,而是引入了哈希槽(Hash Slot) 的概念。
什么是哈希槽(Slot)?
Redis 集群将整个数据集划分成 16384 个哈希槽。要确定一个键应该放入哪个槽,集群会执行以下步骤:
- 使用 CRC16 算法计算键的哈希值:
CRC16(key)。 - 将计算出的哈希值对 16384 进行取模:
CRC16(key) % 16384。 - 取模得到的结果(一个 0 到 16383 之间的整数)就是该键对应的槽位编号。
集群中的每个 Master 节点会负责管理这些哈希槽的一部分。例如,在一个包含 3 个 Master 节点的集群中,槽位的分配可能是这样的:
- 节点 A 负责槽位 0 - 5460
- 节点 B 负责槽位 5461 - 10922
- 节点 C 负责槽位 10923 - 16383
这种确定性哈希函数确保了一个给定的键将始终映射到同一个槽位,从而也始终映射到同一个分片(节点)。这使得集群能够准确地推断出读取特定键时应该访问哪个节点。
哈希槽的优势:便捷的扩缩容
这种基于槽的架构最大的优势在于方便了集群的扩容和缩容,以及数据的分派和查找。
- 添加节点:如果想在集群中新增一个节点 D,只需从现有节点 A、B、C 中移动一部分槽位到 D 即可。
- 删除节点:如果想移除节点 A,只需将 A 负责的所有槽位移动到 B 和 C 节点上,然后将没有任何槽位的 A 节点从集群中移除。
关键在于,从一个节点向另一个节点移动哈希槽并不会导致服务中断。因此,无论是添加、删除节点,还是重新分配节点的哈希槽数量,都不会造成集群不可用的状态。
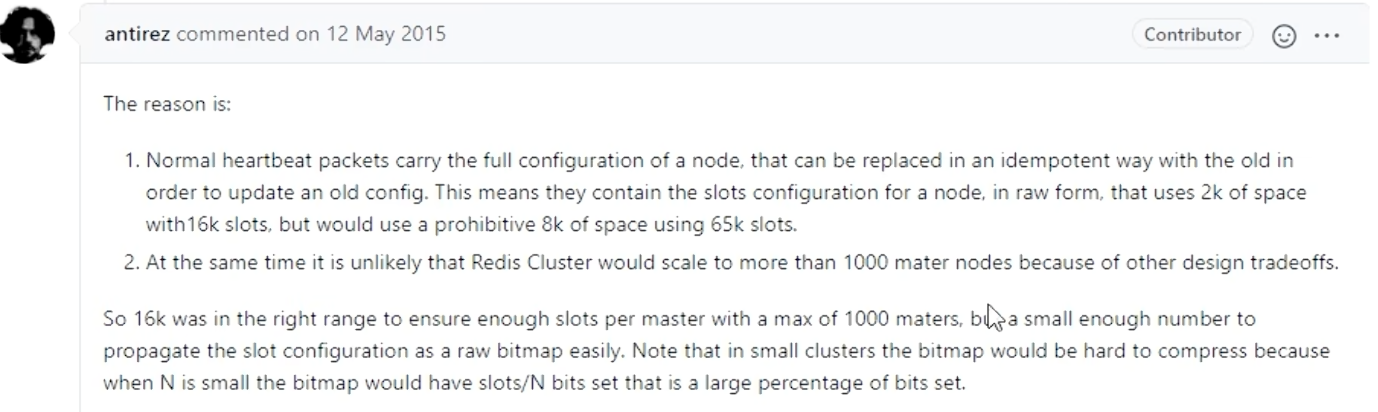
经典面试题:为什么 Redis 集群的槽位是 16384 个?
CRC16 算法产生的哈希值是 16 位的,理论上可以产生 2^16 = 65536 个不同的值。为什么 Redis 不使用 65536 个槽,而选择了 16384(2^14)个呢?
Redis 的作者 Salvatore Sanfilippo (antirez) 曾在 GitHub 的一个 issue 中对此进行了解释。主要原因有以下三点:
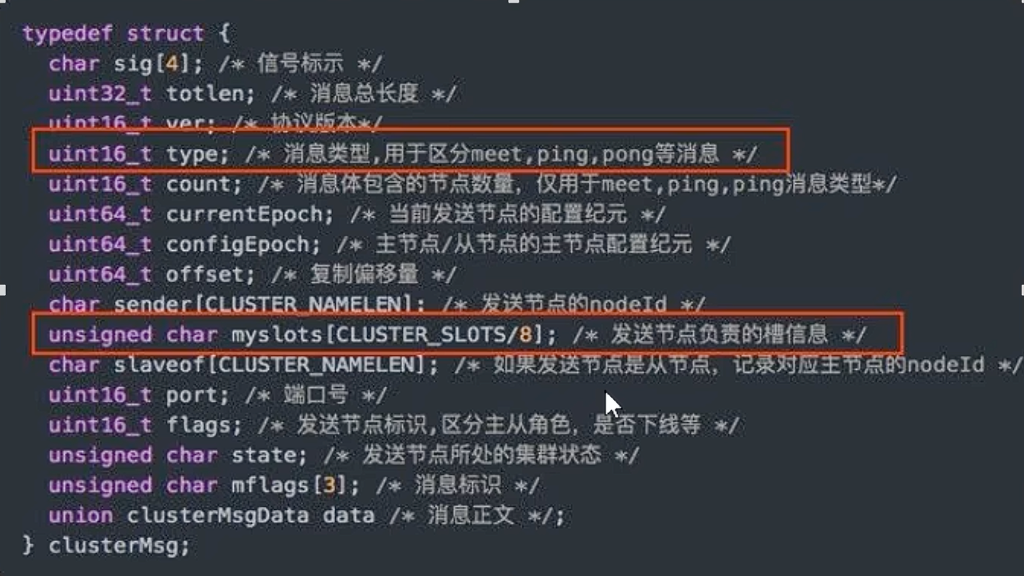
心跳包大小:
Redis 集群的节点之间会通过心跳包(ping/pong)来交换彼此的状态信息。这些信息中包含了该节点负责的槽位信息。这个槽位信息是通过一个位图(bitmap)来表示的。- 如果槽位是 65536,那么这个位图的大小就是
65536 / 8 / 1024 = 8 KB。 - 如果槽位是 16384,那么位图的大小就是
16384 / 8 / 1024 = 2 KB。
每次心跳都携带 8KB 的数据会造成不必要的带宽浪费,尤其是在大规模集群中。2KB 是一个更为合理的折衷。
- 如果槽位是 65536,那么这个位图的大小就是
集群规模限制:
Redis 集群的设计者不建议将集群节点的数量扩展到 1000 个以上,因为随着节点增多,心跳包需要携带的信息会急剧增加,可能导致网络拥堵。对于一个不超过 1000 个节点的集群来说,16384 个槽位已经完全足够,没有必要扩展到 65536 个。位图压缩效率:
在传输过程中,节点会对自己负责的槽位位图进行压缩。当集群节点数较少时,位图的填充率会很低(例如,10 个节点平分 16384 个槽,每个节点的位图只有约 1/10 的位是 1)。如果总槽位数过多,而节点数很少,位图会非常稀疏,导致压缩效率不高。16384 个槽是在节点数量和压缩效率之间取得的一个良好平衡。
Redis 集群的局限性
尽管 Redis 集群功能强大,但它也有一些需要注意的限制:
不保证强一致性:
Redis 集群在节点间采用的是异步复制。当 Master 节点处理完一个写请求后,它会立即向客户端返回成功,然后异步地将命令复制给 Slave 节点。如果此时 Master 发生故障,而数据尚未同步到 Slave,那么这个刚写入的数据就可能会丢失。多键操作的限制:
像MSET、MGET这样的多键操作,要求所有参与的键都必须位于同一个槽位中。如果尝试对分布在不同槽位的多个键执行这些操作,集群会返回CROSSSLOT错误。- 解决方案:可以通过哈希标签(Hash Tags) 来解决这个问题。如果一个键中包含
{...},那么只有花括号内的部分会被用来计算哈希槽。例如,{user:1000}:name和{user:1000}:age这两个键,因为它们的花括号内容相同,所以会被分配到同一个槽位,从而可以一起进行多键操作。
- 解决方案:可以通过哈希标签(Hash Tags) 来解决这个问题。如果一个键中包含