从SET命令到redisObject的KV存储
当我们使用Redis时,一个简单的 SET mykey "hello" 命令就能瞬间完成。我们知道Redis是一个高性能的Key-Value数据库,但你是否曾深入思考过:这个简单的键值对,在Redis内部究竟是如何被组织和存储的?为什么它的Value可以是字符串、列表、哈希等多种复杂结构,却依然能保持O(1)的查询复杂度?
接下来将深入Redis的源码核心,从全局的字典结构出发,层层剖析其核心对象redisObject,最终理解Redis是如何巧妙地实现其强大而高效的KV存储系统的。
宏观视角:Redis的数据类型版图
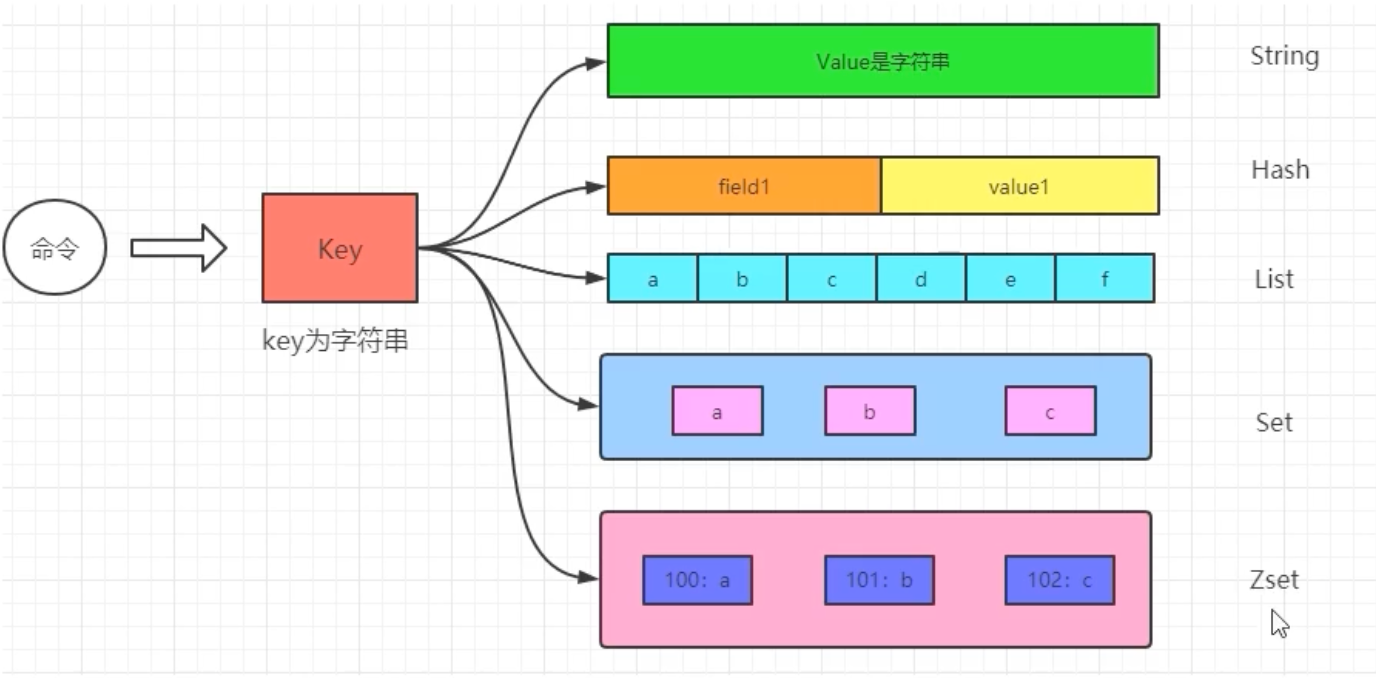
首先,我们要明确Redis的“Value”远非一个简单的字符串。它的数据类型生态十分丰富,通常可以分为:
五大传统类型:这是我们最熟悉的五大传统类型。
- String (字符串)
- List (列表)
- Hash (哈希/字典)
- Set (集合)
- ZSet (有序集合)
新兴数据类型:随着版本迭代,Redis引入了更多强大的类型以适应不同场景。
- Bitmap (位图,实质为String)
- HyperLogLog (基数统计,实质为String)
- GEO (地理空间,实质为ZSet)
- Stream (流,Redis 5.0引入的核心数据结构)
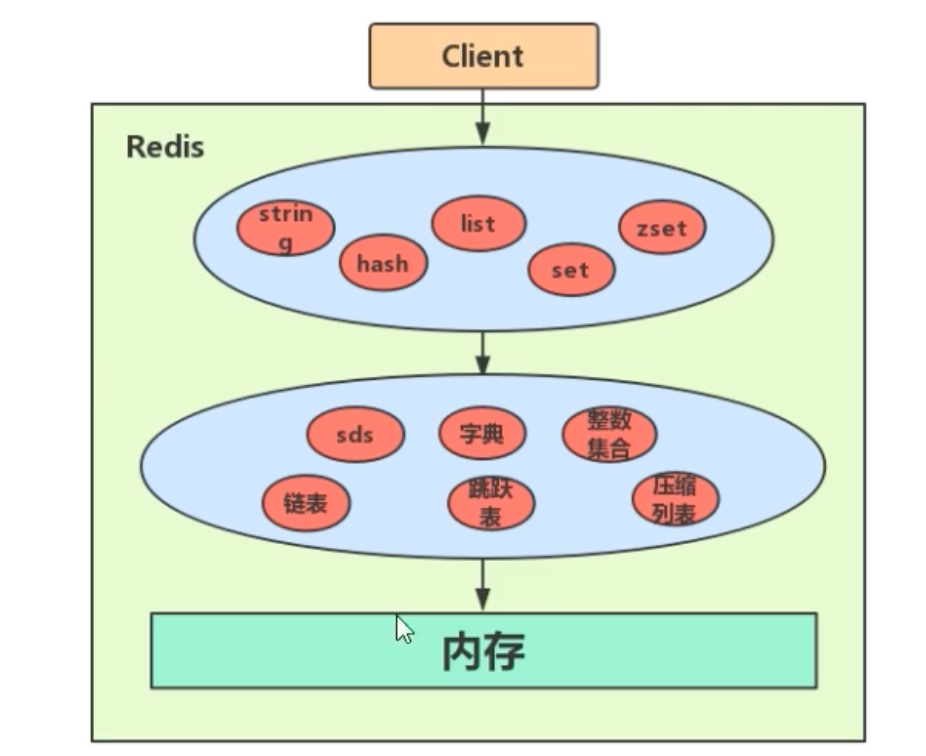
如此多的数据类型,Redis是如何统一管理它们的呢?答案始于其最顶层的设计——一个巨大的字典(哈希表)。
作为数据库的字典 (Dictionary)
从本质上讲,一个Redis数据库就是一个巨大的字典(dict ) 。我们存储的所有键值对,都保存在这个字典中。字典的每个节点,在Redis中由一个名为dictEntry的结构体表示。
这是dictEntry在源码(dict.h)中的简化定义:
typedef struct dictEntry {
void *key; // 指向键的指针
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 指向值的指针 (以联合体形式存在)
struct dictEntry *next; // 指向下个哈希冲突节点的指针
} dictEntry;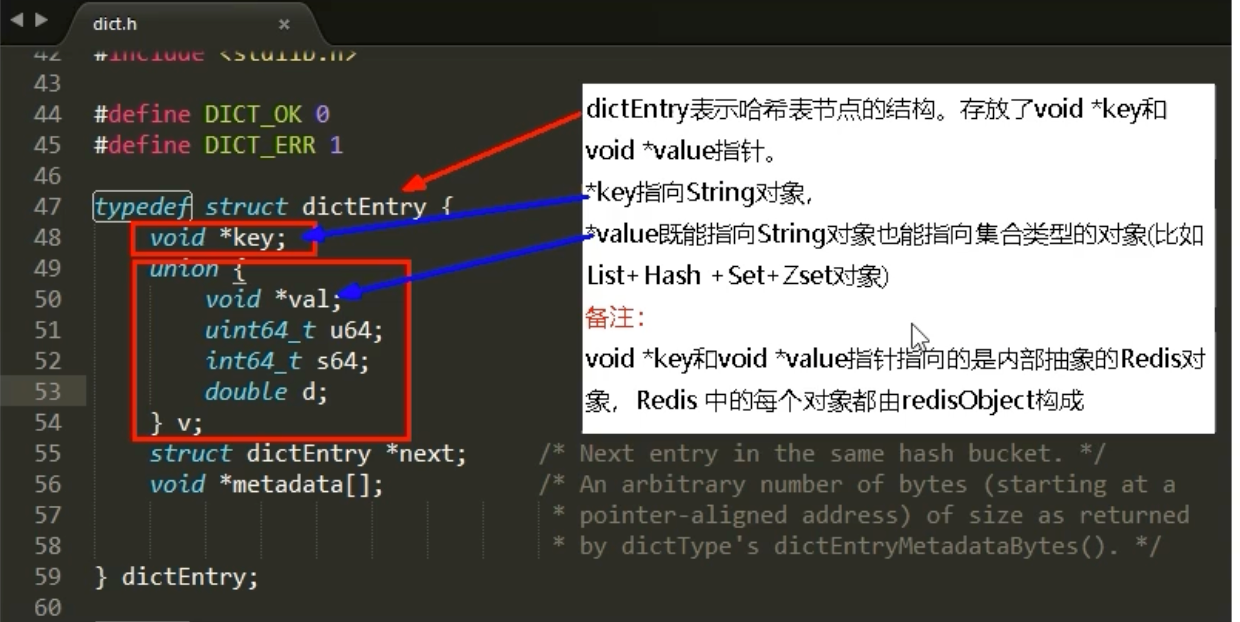
-
key指针指向的是一个SDS(动态字符串),这是Redis对C语言字符串的增强实现。 -
v联合体中的val指针,则指向了我们的Value。
关键问题来了:既然Value有String、List、Hash等多种类型,这个void *val指针到底指向了什么?为了解决这个问题,Redis引入了redisObject。
统一的包装器 redisObject
为了统一处理所有不同类型的Value,并在此基础上进行性能优化,Redis设计了一个精巧的中间层结构——redisObject(也常被称为robj)。我们可以将其理解为所有Redis数据类型的“父类”或“包装器”。
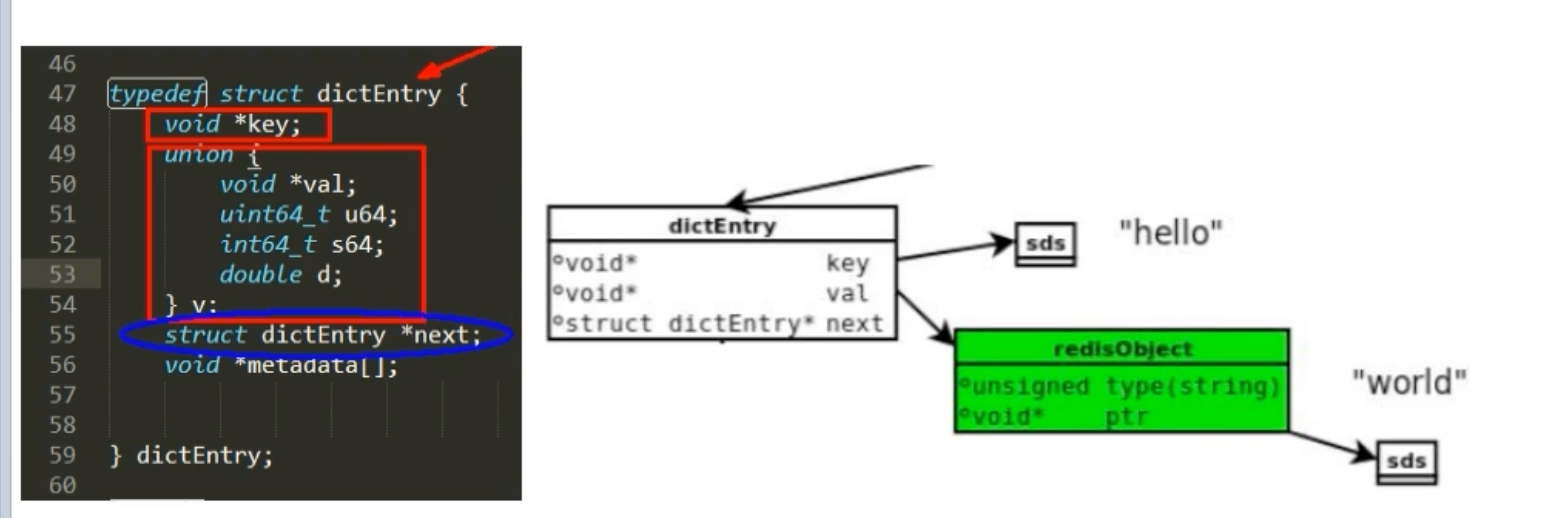
任何一个Value,都不是直接存储其数据,而是先被封装成一个redisObject 。
redisObject的结构定义如下:
typedef struct redisObject {
unsigned type:4; // 4 bits: 对象的逻辑类型 (String, List, etc.)
unsigned encoding:4; // 4 bits: 对象的物理编码方式
unsigned lru:LRU_BITS; // 24 bits: LRU信息,用于内存淘汰
int refcount; // 引用计数,用于内存回收
void *ptr; // 指向底层真实数据结构的指针
} robj;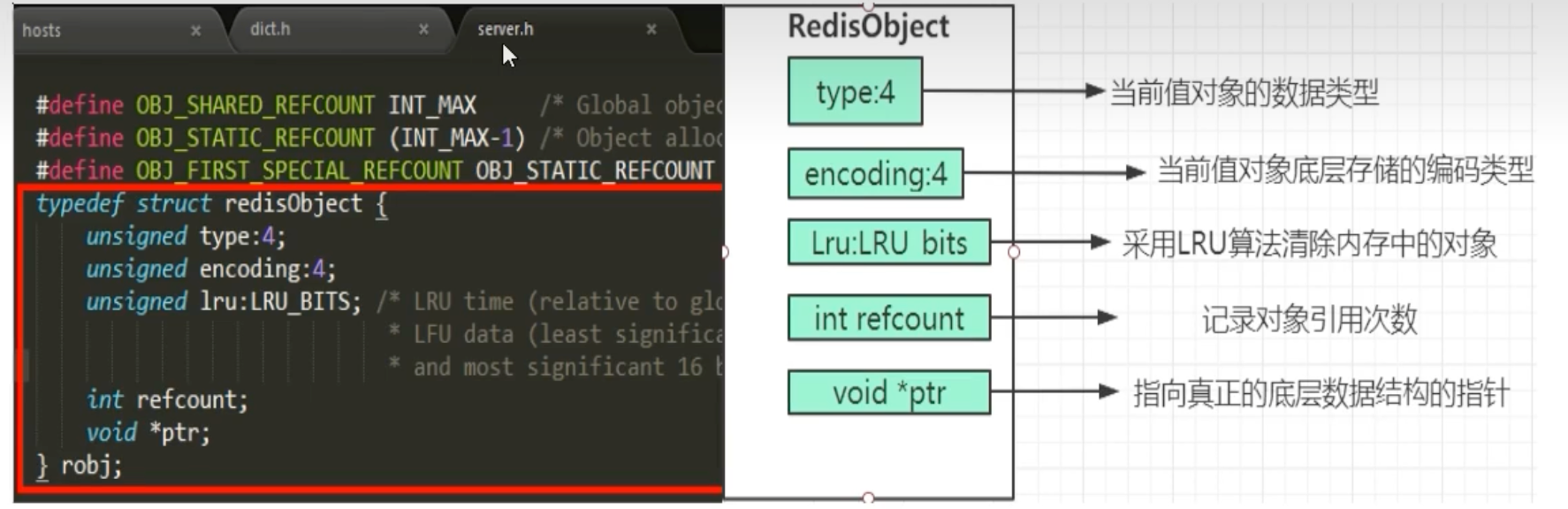
这个结构是理解Redis内部机制的钥匙,我们来逐一解析它的每个字段:
-
type (类型) :标记了这个对象是哪种逻辑数据类型,如String、List、Hash等。这解决了“它是什么”的问题。 -
encoding (编码) :这是Redis性能优化的核心。它表示为了存储这个对象,底层实际使用了哪种物理数据结构。同一种type可能对应多种encoding。 -
lru (最近最少使用) :记录了对象最后一次被访问的时间,用于在内存不足时执行LRU淘汰策略。 -
refcount (引用计数) :用于对象的生命周期管理。当refcount为0时,该对象占用的内存会被回收。 -
ptr (指针) :这个指针才是真正指向存储数据的物理结构。
所以,Redis的完整存储结构如下图所示:
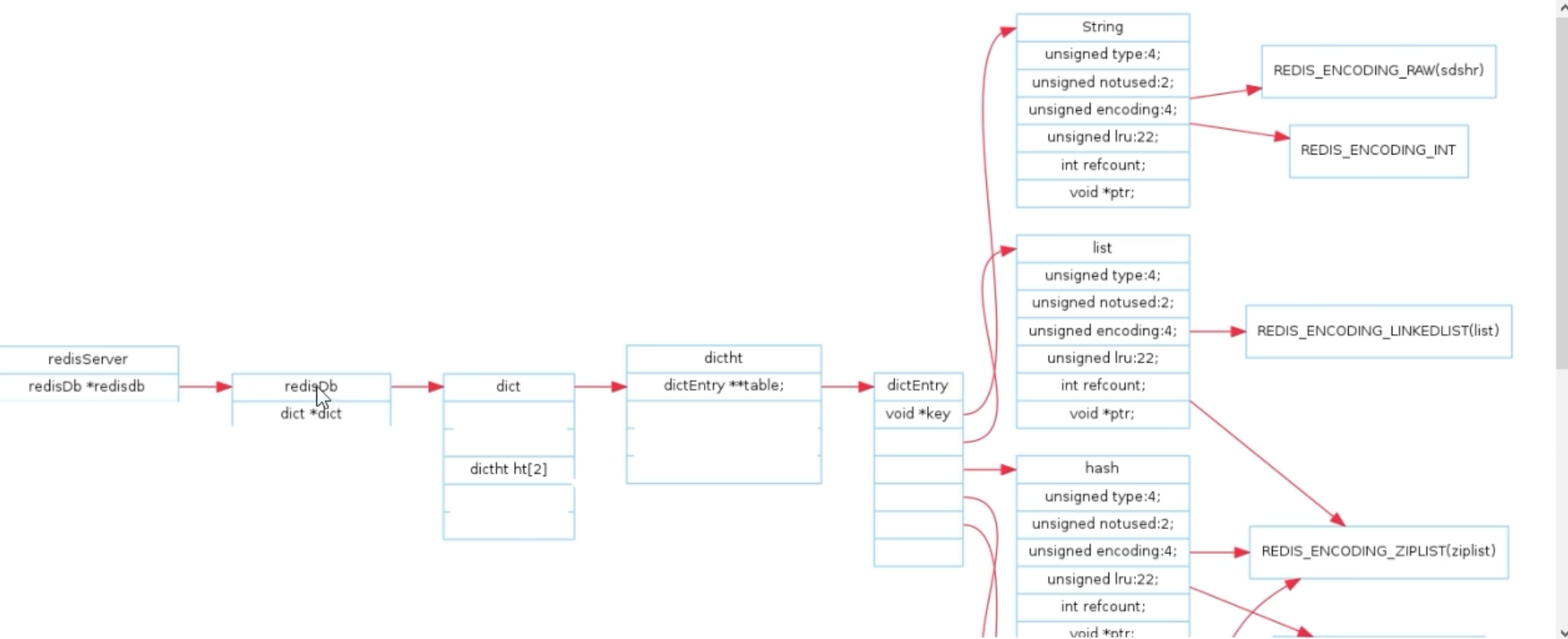
类型与编码的分离
redisObject中最精妙的设计,就是将逻辑类型 (type ) 和物理编码 (encoding ) 分开。这使得Redis可以根据数据的实际情况,自动选择最高效的内部编码来存储,从而在保证功能的同时,极大地优化内存使用和运行效率。
以下是Redis 7中主要数据类型与编码的对应关系:
| 逻辑类型 (Type) | 物理编码 (Encoding) | 描述 |
|---|---|---|
| String | int | 当值为纯数字时,直接用整数存储 |
embstr | 短字符串(长度<=44字节),一次内存分配 | |
raw | 普通SDS字符串 | |
| List | quicklist | 双向链表,每个节点是一个listpack |
| Hash | listpack | 键值对少且短时,用紧凑列表存储 |
hashtable | 标准的哈希表 | |
| Set | intset | 元素全为整数且数量不多时,用整数集合 |
hashtable | 标准的哈希表 | |
| ZSet | listpack | 元素少且短时,用紧凑列表存储 |
skiplist | 跳表 + 哈希表 |

注意:在Redis 7中,ziplist(压缩列表)已被更高效的listpack(紧凑列表)全面取代。
实战追踪:SET age 17 的底层之旅
让我们通过一个简单的命令,来追踪Redis的内部工作流程:
127.0.0.1:6379> SET age 17
OKRedis创建一个新的
dictEntry。
key指针指向一个内容为 “age” 的SDS对象。
value指针指向一个新建的redisObject。Redis分析值 “17” 是一个纯数字,可以被优化。
因此,这个
redisObject的字段被设置为:-
type:OBJ_STRING(逻辑上它仍是字符串类型) -
encoding:OBJ_ENCODING_INT(物理上用整数编码) -
ptr: 不再是指针,而是直接存储了整数值17 (这是一个指针大小整数的优化)。
-
我们可以通过命令来验证:
127.0.0.1:6379> TYPE age
string
127.0.0.1:6379> OBJECT ENCODING age
"int"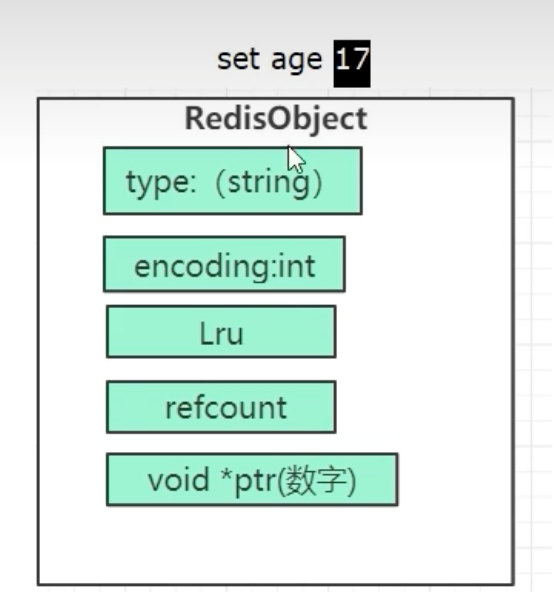
如果我们设置一个普通字符串:
127.0.0.1:6379> SET name "redis"
OK
127.0.0.1:6379> OBJECT ENCODING name
"embstr"可以看到,type同为string,但encoding根据值的不同而自动选择了最优方案。
Redis 7 的演进
相较于之前的版本,Redis 7在底层做了很多优化,其中最显著的是:
-
listpack 全面取代 ziplist:listpack解决了ziplist连锁更新的性能问题,现在是Hash、List、ZSet在紧凑模式下的标准编码。 - 多AOF文件支持:增强了AOF持久化的灵活性和可靠性。
- 客户端内存限制:可以对所有客户端连接的总内存使用量进行限制,防止因连接过多导致内存溢出。
结论
Redis之所以能成为一个高性能、多功能的内存数据库,其成功的秘诀并不仅仅是“快”,更在于其内部设计的精巧与智能。通过dictEntry构建KV骨架,再利用redisObject这一统一的包装器,将数据的逻辑类型与物理编码解耦,使得Redis能够在不同场景下自动选择最优的数据结构,实现了极致的内存和性能优化。
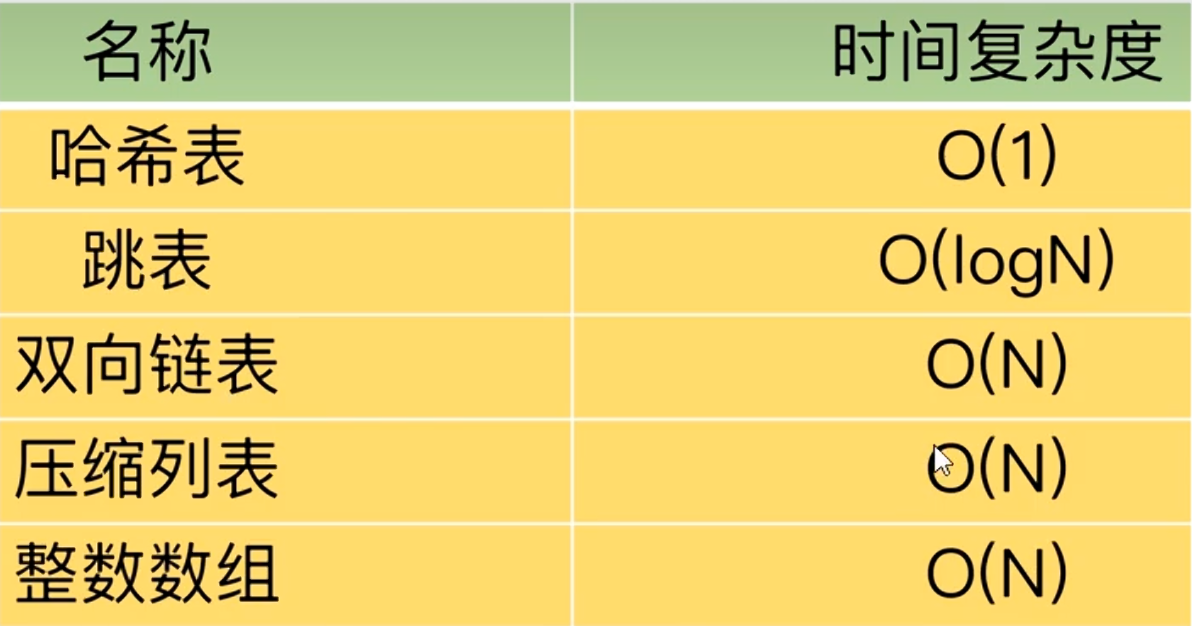
redis数据类型以及数据结构的时间复杂度