在 Redis 的使用过程中,海量键(MoreKey)和过大键(BigKey)是两种常见但容易被忽视的性能杀手。它们会给 Redis 的稳定性、响应延迟和运维带来巨大挑战。本文将深入探讨这两类问题的成因、危害,并提供一套完整的发现、处理和规避方案。
一、MoreKey(海量键)问题
MoreKey 指的是在单个 Redis 实例中存在过多的键,例如数千万甚至上亿的 Key。
模拟海量数据
首先,我们向一个文本文件中写入一百万条 Redis SET 命令。
# 生成一百万条 set 命令并存入 /tmp/redisTest.txt 文件
# 使用 seq 命令生成序列,效率更高
for i in $(seq 1 1000000)
do
echo "SET k$i v$i" >> /tmp/redisTest.txt
done接下来,使用 Redis 的 pipe (管道) 模式将文件中的命令批量导入 Redis,这种方式可以极大提升写入效率。
# 使用管道模式将数据高速导入 Redis
cat /tmp/redisTest.txt | redis-cli -h 127.0.0.1 -p 6379 -a your_password --pipe导入前后,我们可以通过 DBSIZE 命令查看键数量的变化,以确认数据已成功导入。

海量键的挑战:如何安全删除
致命的 KEYS 命令
一个直观的想法是使用 KEYS k* 来查找并删除我们刚刚插入的所有键。

然而,KEYS 命令在生产环境中是极其危险的,应绝对避免使用。
- 阻塞性操作:Redis 是单线程处理命令的。
KEYS命令会一次性遍历所有符合条件的键,这是一个 O(N) 复杂度的操作。如果实例中有数千万的键,这个过程会耗费很长时间(从毫秒到数秒甚至更久)。 - 服务卡顿:在
KEYS命令执行期间,Redis 无法处理任何其他请求,会导致所有客户端的读写操作被阻塞,引发大量超时错误。 - 引发雪崩:如果大量应用依赖该 Redis 实例,长时间的阻塞可能导致应用服务大面积瘫痪,甚至引发缓存雪崩,最终冲击到后端的数据库。
同样,FLUSHDB 和 FLUSHALL 命令在数据量大时也会造成长时间阻塞,需要慎用。
生产环境的最佳实践
为了防止误操作,可以通过 redis.conf 文件禁用这些高危命令。在 SECURITY 配置部分,可以这样设置:
# 重命名或禁用危险命令
# rename-command KEYS ""
# rename-command FLUSHDB ""
# rename-command FLUSHALL ""KEYS 的替代者:SCAN 命令
为了解决 KEYS 命令的阻塞问题,Redis 2.8 版本后引入了 SCAN 命令。它是一种安全、增量的迭代方式。
-
SCAN:用于迭代当前数据库中的所有键。 -
HSCAN:用于迭代哈希类型中的键值对。 -
SSCAN:用于迭代集合类型中的元素。 -
ZSCAN:用于迭代有序集合中的元素和分值。
SCAN 命令语法
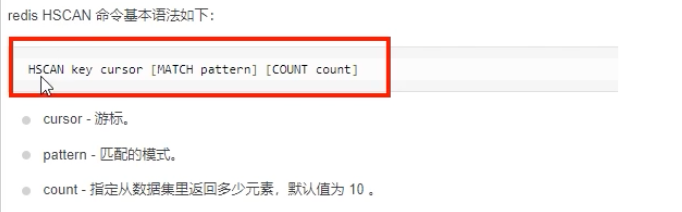
SCAN cursor [MATCH pattern] [COUNT count]-
cursor (游标) :迭代的起点。第一次迭代时,游标为 0。每次SCAN调用会返回一个新的游标,下一次迭代时需要传入这个新游标。当返回的游标为 0 时,表示整个迭代过程结束。 -
MATCH pattern:可选参数,用于匹配指定的键模式,类似KEYS的通配符。 -
COUNT count:可选参数,提示 Redis 单次迭代应返回的元素数量大约有多少。这只是一个提示,实际返回的数量可多可少。
SCAN 的特点
SCAN 的返回结果是一个包含两个元素的数组:第一个是下一次迭代要用的新游標,第二个是本次迭代出的元素列表。

SCAN 的遍历顺序很特殊,它并非从头到尾的线性扫描,而是采用了一种更复杂的高位进位加法策略。这种设计的目的是为了有效处理在遍历过程中发生的字典(Redis 底层存储结构)扩容或缩容,避免元素的重复或遗漏。
案例补充:使用 SCAN 安全删除百万个键
以下是一个 Shell 脚本示例,它使用 SCAN 命令安全地查找并删除所有以 k 开头的键:
#!/bin/bash
# Redis 连接信息
REDIS_HOST="127.0.0.1"
REDIS_PORT="6379"
REDIS_AUTH="your_password"
CURSOR=0
echo "Starting key deletion..."
# 循环执行 SCAN,直到返回的游标为 0
while true; do
# 执行 SCAN 命令,一次扫描约 1000 个键
# 使用 --raw 选项确保输出不被转义
REPLY=($(redis-cli -h $REDIS_HOST -p $REDIS_PORT -a $REDIS_AUTH --raw SCAN $CURSOR MATCH "k*" COUNT 1000))
# 提取新的游标和键列表
CURSOR=${REPLY[0]}
KEYS=("${REPLY[@]:1}")
# 如果键列表不为空,则删除这些键
if [ ${#KEYS[@]} -gt 0 ]; then
echo "Deleting ${#KEYS[@]} keys..."
redis-cli -h $REDIS_HOST -p $REDIS_PORT -a $REDIS_AUTH DEL "${KEYS[@]}"
fi
# 如果游标回到 0,表示遍历完成
if [ "$CURSOR" == "0" ]; then
break
fi
done
echo "Deletion complete."二、BigKey(大键)问题
BigKey 通常指的不是 Key 的名字过长,而是 Key 对应的 Value 过大。一个 String 类型的 Value 有 50MB,或者一个 Hash 类型的 Value 包含 200 万个元素,都属于 BigKey。
BigKey 的定义标准
业界并没有一个绝对的标准,但结合(阿里云 Redis 开发规范)等行业实践,可以参考以下建议:
- 【强制】 :拒绝 BigKey,因为它会引起网络流量阻塞和慢查询。
- String 类型:大小控制在 10KB 以内。
- 集合类型(Hash, List, Set, ZSet) :元素个数建议不超过 5000 个。
疑问:为什么是 5000 个元素?
这个数值是一个工程实践上的权衡,主要基于以下几点考虑:
- 命令耗时:Redis 的命令处理是单线程的。对一个包含数万元素的集合进行一次操作(如
HGETALL),序列化和传输数据会消耗毫秒级甚至秒级的时间,足以阻塞其他所有请求。 - 网络带宽:一次性获取一个巨大的 Value 会瞬间占满服务器网卡带宽,影响该服务器上 Redis 及其他服务的正常运行。
- 内存分配:大键的内存分配和释放可能导致内存碎片,或在删除时造成长时间的 CPU 阻塞。
将元素数量限制在 5000 以内,通常可以确保大部分操作在亚毫秒级完成,从而保障 Redis 的高性能。
BigKey 的危害
- 内存分布不均:在集群模式下,BigKey 会导致某个特定节点内存使用量远超其他节点,造成数据倾斜,难以进行负载均衡。
- 阻塞风险:对 BigKey 的操作(如删除)会长时间占用 CPU,阻塞 Redis 主线程。一个大 ZSet 键的过期删除,虽然不会记录在慢查询日志中,但同样会引发服务卡顿。
- 网络流量阻塞:当客户端(如
redis-cli)或主从同步时获取一个 BigKey,巨大的网络流量可能导致连接中断或服务变慢。 - 迁移困难:在集群扩缩容或迁移时,包含 BigKey 的分片迁移耗时会非常长,甚至失败。
如何发现 BigKey?
redis-cli --bigkeys
这是一个内置的工具,它会扫描整个实例,并给出每种数据类型中“最大”的键(按大小或成员数)。
- 优点:简单易用,提供一个快速概览。
- 不足:只能找到每种类型中最大的那一个 Key,无法自定义阈值(如查找所有大于 10KB 的 String),并且扫描本身也可能对线上服务产生一定影响。
MEMORY USAGE 命令
此命令可以精确地返回一个键及其 Value 在内存中占用的字节数。MEMORY USAGE key [SAMPLES count]
结合
SCAN命令,我们可以编写脚本来遍历所有键,并使用MEMORY USAGE找出所有超过指定大小的键,这是更精细化的发现方法。
如何优雅地删除 BigKey?
绝对不要对集合类型的 BigKey 直接使用 DEL ! 正确的方式是渐进式删除。
- String:如果 Value 过大(例如超过 1MB),直接
DEL仍可能阻塞。Redis 4.0 以后推荐使用 UNLINK 命令,它会将删除操作放入后台线程异步执行。 - Hash:使用
HSCAN迭代获取少量(如每次 100 个)字段,然后用HDEL删除这些字段。
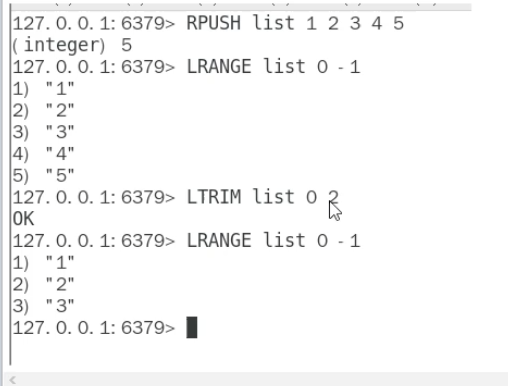
- List:使用
LTRIM命令,每次修剪掉一小部分元素(如LTRIM mylist 100 -1),循环执行直到列表为空。
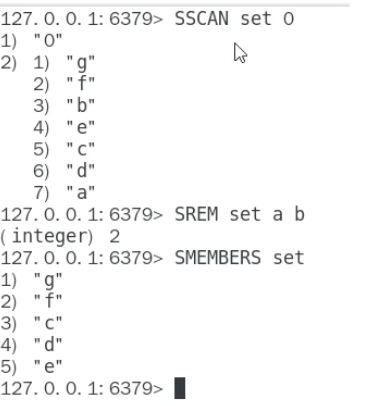
- Set:使用
SSCAN迭代获取少量元素,然后用SREM删除。
- ZSet:使用
ZSCAN迭代元素,或更常用的是使用ZREMRANGEBYRANK/ZREMRANGEBYSCORE等命令,每次删除一个排名或分数区间内的小批量元素。

三、面试题精讲:BigKey 调优与惰性删除 (Lazy Free)
面试官:你做过 BigKey 的调优吗?了解 Redis 的惰性释放(Lazy Free)机制吗?
回答思路:
当然。BigKey 调优的核心思想是避免 Redis 主线程的阻塞。这包括在业务层面进行数据结构拆分来规避产生 BigKey,以及在必须处理 BigKey 时,采用非阻塞的方式进行操作。Redis 4.0 引入的 Lazy Freeing 机制正是解决这个问题的利器。
1. 什么是 Lazy Freeing?
Lazy Freeing(惰性删除)是一种异步的内存回收机制。传统的 DEL 命令在删除一个键时,会同步地完成所有内存的回收。如果这个键是一个 BigKey,回收过程会耗费很长时间,从而阻塞主线程。
Lazy Freeing 将内存回收任务交给了后台线程。当执行一个异步删除命令时(如 UNLINK),主线程仅仅是将键从键空间中移除,这个动作耗时极短(O(1)),然后将真正的内存回收任务放入一个队列,由后台线程去完成。
2. DEL vs UNLINK
-
DEL:阻塞式删除。对于小 Key,它的速度很快。对于 BigKey,它是一场灾难。 -
UNLINK:非阻塞式删除。它总是能快速返回,是删除 BigKey 的首选。
3. 自动的 Lazy Freeing
除了手动的 UNLINK,Redis 还允许我们将某些由内部触发的删除操作配置为默认异步执行。在 redis.conf 中,有以下几个关键配置:
# 当 Redis 因内存达到 maxmemory 而淘汰键时,是否异步删除
lazyfree-lazy-eviction no
# 当设置了过期时间的键到期被删除时,是否异步删除
lazyfree-lazy-expire no
# 当一个键因为被新值覆盖而“隐式”删除时(如 SET key new_val 覆盖旧值),是否异步删除
lazyfree-lazy-server-del no
# 从节点在全量同步时清空数据库,是否异步执行
replica-lazy-flush no在处理 BigKey 问题的场景下,强烈建议将以下选项全部设置为 yes,以避免因过期、淘汰等后台操作引发的意外阻塞。

总结:
我的 BigKey 调优经验主要有三点:
预防:在代码设计阶段,评估数据规模,对可能成为 BigKey 的数据结构进行拆分。例如,将一个大的 Hash 拆分成多个小 Hash。
发现:通过
redis-cli --bigkeys和SCAN+MEMORY USAGE脚本定期巡检,建立监控告警,及时发现潜在的 BigKey。处理:
- 手动删除:坚决使用
UNLINK替代DEL,并采用HSCAN,SSCAN等方式渐进式清理。 - 自动删除:开启 Redis 的各项
lazyfree-配置,让 Redis 在处理过期、淘汰等场景时自动采用非阻塞方式,保障服务的稳定性。
- 手动删除:坚决使用
通过这一套组合拳,可以有效地管理和优化 BigKey 问题,确保 Redis 服务的高性能和高可用。