Kubernetes 架构深度解析:Master 与 Worker 节点全景
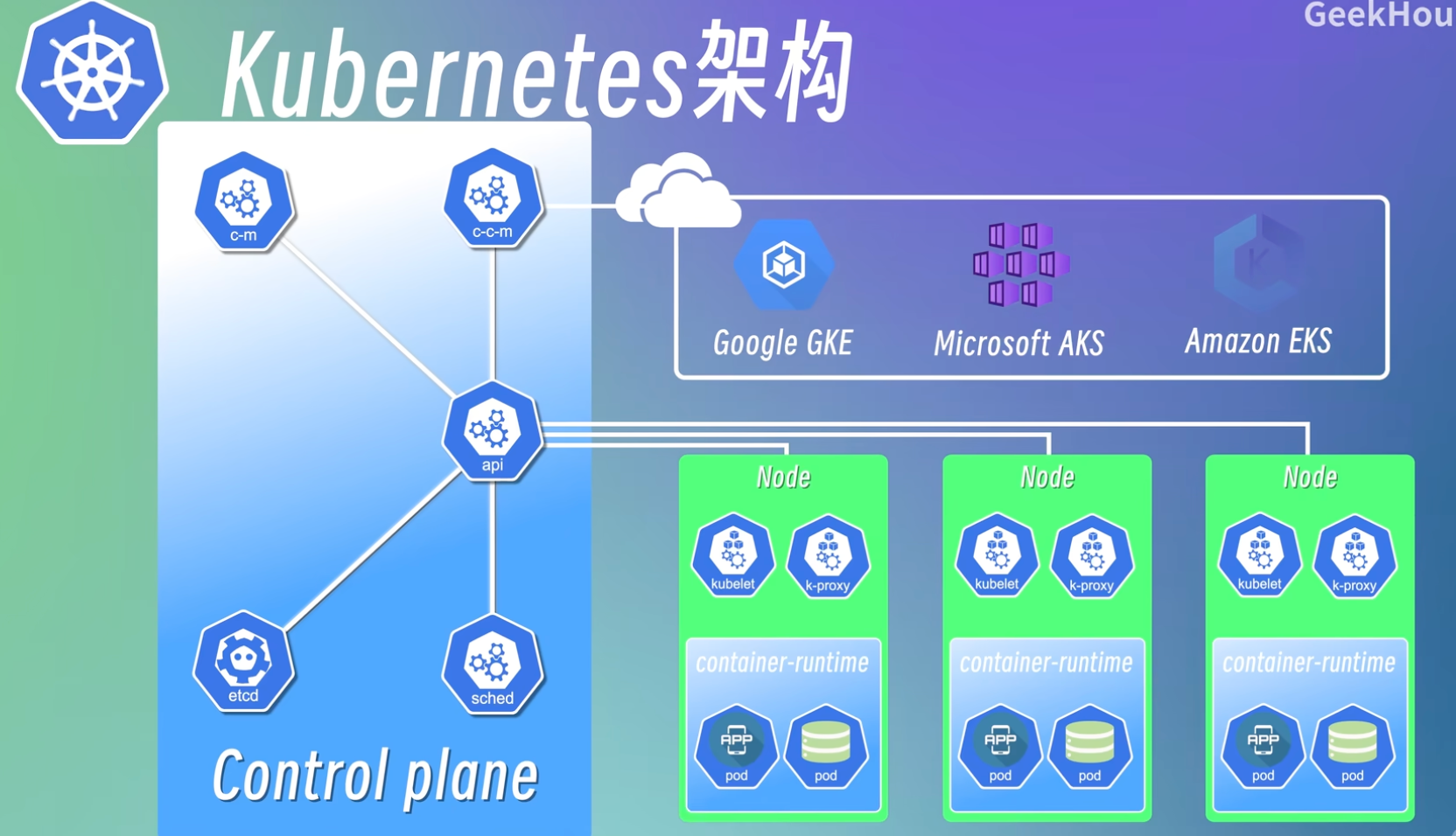
Kubernetes (K8s) 采用经典的 Master-Worker 架构。其中,Master 节点(主节点)负责管理和控制整个集群,而 Worker 节点(工作节点)则负责运行实际的应用程序和服务。

一、Worker 节点:集群的动力核心
我们先从真正承载业务的 Worker 节点开始。
官方定义言简意赅:
Kubernetes 通过将容器放入在节点(Node)上运行的 Pod 来执行你的工作负载。
简单来说,Node 就是 K8s 集群中真正“干活”的机器,是承载业务应用的实体,因此它也被形象地称为 Worker Node(工作节点)。
为了能正常工作并对外提供服务,每个 Worker 节点都必须包含三个核心组件:kubelet、kube-proxy 和容器运行时(Container Runtime)。
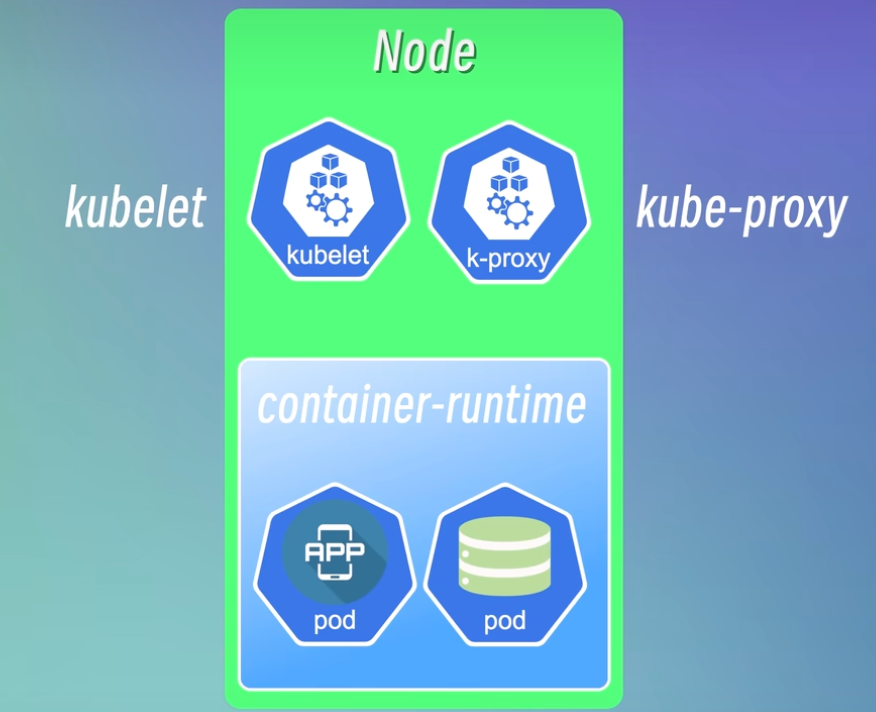
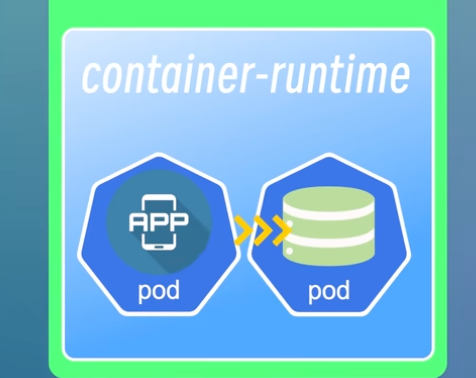
1. 容器运行时 (Container Runtime)
容器运行时的概念可能有些抽象,你可以把它理解为一个专门用于运行容器的底层软件。它负责所有与容器生命周期相关的操作,例如拉取容器镜像、创建和销毁容器、启动或停止容器等。
正如所有程序都需要操作系统来运行一样,所有容器也都需要容器运行时来运行。因此,每个 Worker 节点上都必须安装容器运行时。
在 K8s 中,你可以根据需求选择不同的容器运行时。虽然 Docker Engine 曾是主流,但现在 K8s 生态支持多种符合 CRI (Container Runtime Interface) 标准的运行时,常见的包括:
- containerd (目前最主流的选择)
- CRI-O
- Docker Engine (通过
cri-dockerd 适配) - Mirantis Container Runtime
2. kubelet:节点的“大管家”
kubelet 是运行在每个 Worker 节点上的代理程序,是 Master 节点在 Worker 节点上的“代言人”。它的核心职责是:
- 管理 Pod 生命周期:确保节点上的 Pod 和其中的容器按照预期状态运行。
- 接收指令:定期从 Master 节点的
api-server 组件接收新的或修改后的 Pod 规范(PodSpec)。 - 状态汇报:监控本节点的运行状况(如 CPU、内存使用率)和 Pod 的状态,并将这些信息汇报给
api-server。
3. kube-proxy:集群网络代理
kube-proxy 是每个 Worker 节点上的网络代理和负载均衡器,负责实现 Kubernetes 的 Service 通信。它的主要工作是:
- 维护网络规则:在节点上维护网络规则,允许从集群内部或外部与 Pod 进行网络通信。
- 服务发现与负载均衡:当流量发往一个 Service 时,
kube-proxy 会将这些流量高效地路由到正确的后端 Pod 中,实现负载均衡。
它能实现一个重要的优化:当一个 Pod 需要访问同一个节点上的另一个 Pod(例如,应用访问本地数据库)时,kube-proxy 会智能地将流量直接路由到目标 Pod,避免了不必要的跨节点网络开销,提升了通信效率。
二、Master 节点:集群的智慧大脑
既然 Worker 节点负责执行任务,那么谁来管理和协调这些节点呢?例如,如何将 Pod 调度到最合适的节点?如何监控节点状态?如何处理节点的增删?
这便是 Master 节点 的核心职责。Master 节点是集群的控制平面,由四个基本组件构成:kube-apiserver、etcd、kube-controller-manager 和 kube-scheduler。
1. kube-apiserver:集群的统一入口
apiserver 是 Kubernetes 控制平面的唯一入口和数据交互中心。所有组件,无论是外部用户还是内部组件,都只能通过这个 API 接口进行通信。
当你作为用户,希望在集群中部署应用时,就需要通过客户端与 apiserver 交互。这个客户端可以是 kubectl 命令行工具,也可以是 Dashboard 等图形化 UI 工具。
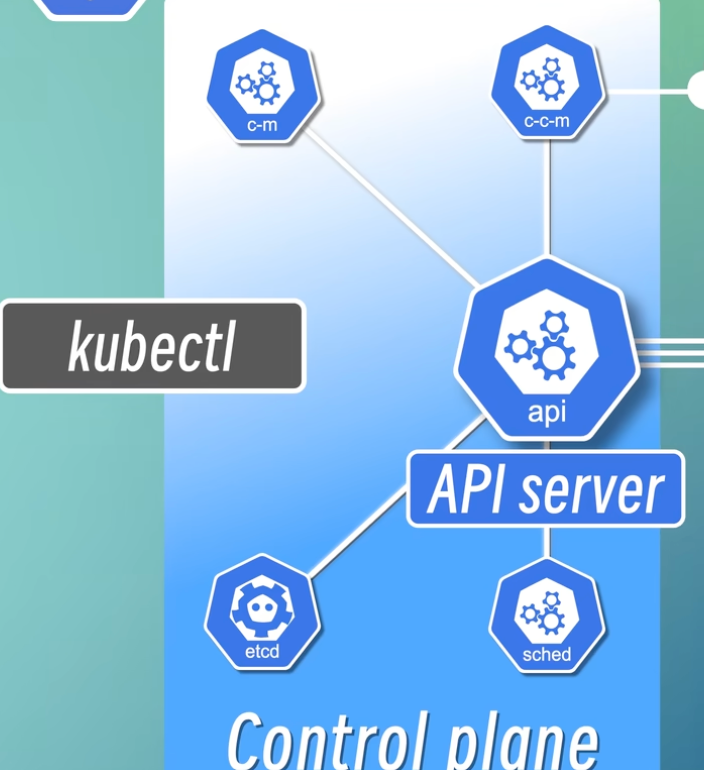
apiserver 就像是集群的“网关”,它承担两大核心功能:
- API 服务:提供 RESTful API,处理所有资源的增、删、改、查请求,并将它们分发给其他组件处理。
- 访问控制:负责认证、授权和准入控制,确保只有合法的用户才能对集群资源进行操作,保障了整个集群的安全性。例如,当你使用
kubectl 创建一个 Pod 时,请求首先到达apiserver,它会验证你的身份和权限,通过后才会执行后续流程。
2. etcd:集群的状态存储
etcd 是一个高可用的分布式键值存储系统,被誉为集群的“大脑”或“真理之源” 。它负责存储整个集群所有资源对象的状态信息,例如 Pod 的定义、Node 的状态、Service 的配置等等。
- 数据中心:集群中任何状态的变更(如一个 Pod 崩溃、一个新 Pod 被创建)都会被记录在
etcd 中。 - 可靠性基石:其他组件(如
controller-manager)通过监视etcd 中的数据变化来做出响应,从而实现集群的自愈和自动化管理。 - 查询来源:我们通过
kubectl 或 UI 查询到的集群状态,其数据都源自etcd。
注意:
etcd 只存储集群的元数据和状态信息,不存储应用程序的业务数据(例如数据库中的数据)。
3. kube-scheduler:智能的“调度员”
scheduler(调度器)的工作非常专一:为新创建的 Pod 寻找最合适的 Worker 节点。
它会持续监控集群中所有节点的资源使用情况,并根据一系列预设的调度策略(如资源需求、亲和性/反亲和性规则、污点和容忍等),将 Pod “分配”到最合适的节点上运行。
举个例子:当一个新 Pod 需要被调度时,如果节点 A 资源占用 80%,节点 B 占用 20%,节点 C 占用 40%,那么 scheduler 极有可能将这个 Pod 智能地调度到资源最充裕的节点 B 上,从而实现资源的合理利用。
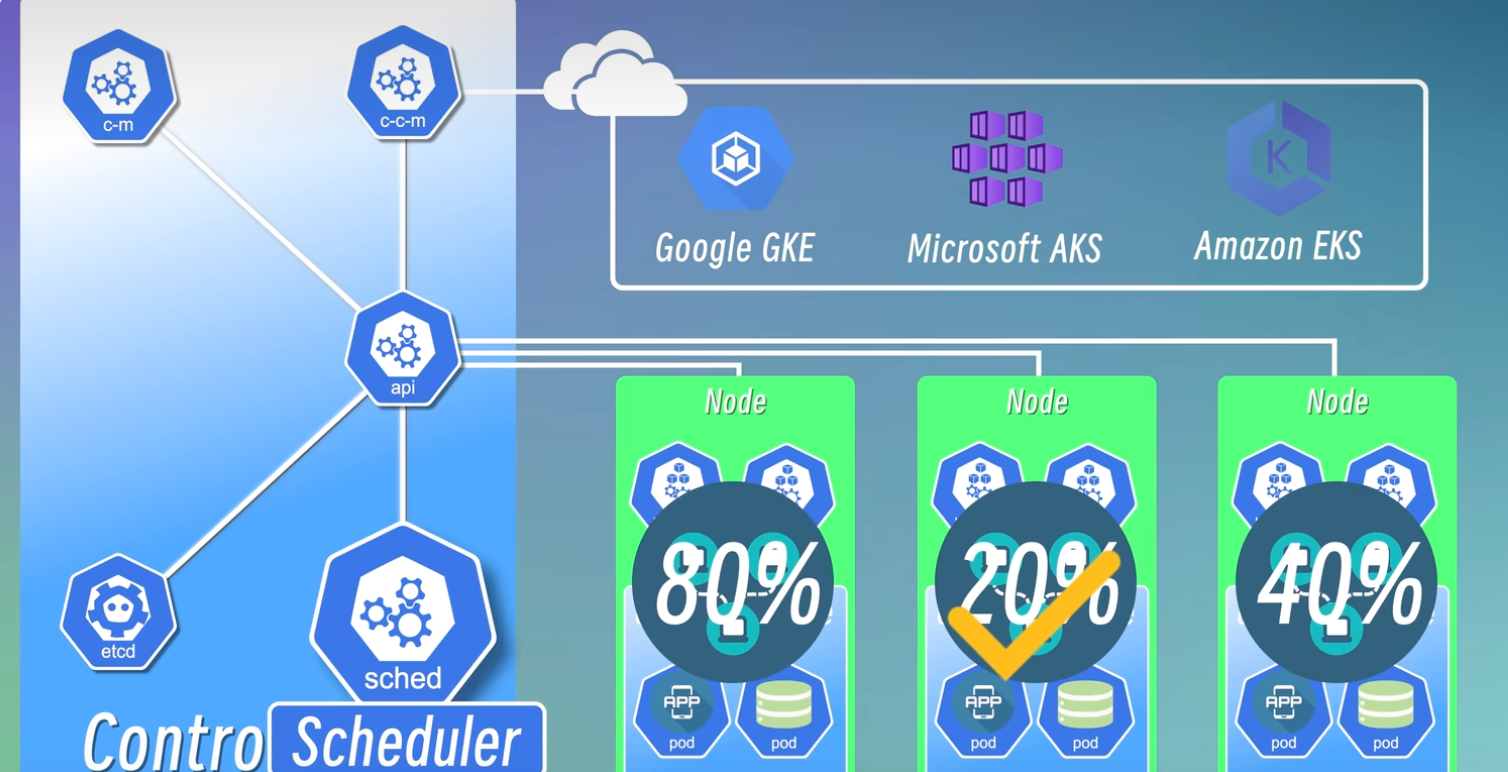
4. kube-controller-manager:状态的“维护者”
controller-manager(控制器管理器)是确保集群状态与用户期望状态一致的核心组件。它内部包含多种控制器,每种控制器负责管理一类特定的资源。
它的工作模式可以理解为一个持续运行的“调节循环”(Reconciliation Loop):
- 监控:通过
apiserver 监控集群的当前状态(例如,运行中的 Pod 数量)。 - 比较:将当前状态与
etcd 中存储的期望状态进行比较。 - 调节:如果两者不一致,控制器会采取行动来修复差异。
例如,当某个节点上的 Pod 意外崩溃时,controller-manager 中的 ReplicaSet 控制器会检测到这一变化,并立即创建一个新的 Pod 来替代它,从而确保运行的 Pod 数量始终符合用户的设定。
三、一个特殊的云端组件:Cloud Controller Manager
如果你使用的是云服务商(如 AWS、GCP、Azure)提供的托管 K8s 集群,还会有一个额外的组件:cloud-controller-manager(云控制器管理器)。
它是一个与特定云平台相关的控制器,负责与云平台的 API 进行交互,管理云端的特有资源,如负载均衡器、存储卷等,为用户提供跨云平台的一致性管理体验。