在Redis的五大经典数据类型中,Hash因其直观的field-value结构而备受青睐。然而,为了在性能和内存之间寻求极致的平衡,一个看似简单的Hash对象,其底层实现却暗藏玄机。Redis会根据存储数据的大小和数量,动态地为其选择不同的编码方式——在早期版本中是ziplist(压缩列表)和hashtable,而在Redis 7中,主角则换成了listpack(紧凑列表)。
Hash的两种“面孔”:紧凑与分散
一个Hash对象在Redis中,通常会有两种存储形态:
- 紧凑形态 (Compact) :当Hash中存储的键值对数量较少,且每个键和值的长度都较短时,Redis会采用一种极其节省内存的连续存储结构。在Redis 6及之前是
ziplist,Redis 7之后是listpack。 - 分散形态 (Sparse) :一旦超出预设的阈值,Hash就会被转换为标准的
hashtable(字典)结构。
这个转换的“门槛”由两个参数共同决定:
-
hash-max-ziplist-entries / hash-max-listpack-entries:紧凑形态下允许的最大条目数(默认512)。 -
hash-max-ziplist-value / hash-max-listpack-value:紧凑形态下每个键或值的最大长度(默认64字节)。
# Redis 6中的配置
127.0.0.1:6379> CONFIG GET hash-max-ziplist-*
1) "hash-max-ziplist-entries"
2) "512"
3) "hash-max-ziplist-value"
4) "64"
# Redis 7中的配置 (同时保留ziplist以兼容)
127.0.0.1:6379> CONFIG GET hash-max-*-*
1) "hash-max-listpack-entries"
2) "512"
3) "hash-max-ziplist-entries"
4) "512"
5) "hash-max-listpack-value"
6) "64"
7) "hash-max-ziplist-value"
8) "64"只要任一条件不满足,Hash就会从紧凑形态自动升级为hashtable。这种升级是单向的,不可逆。
# 在Redis 6中演示ziplist到hashtable的转换
# 初始为ziplist
127.0.0.1:6379> HSET user:01 name "Alice"
(integer) 1
127.0.0.1:6379> OBJECT ENCODING user:01
"ziplist"
# 添加一个超长的值,触发转换
127.0.0.1:6379> HSET user:01 bio "A very long biography string that is definitely longer than 64 bytes to trigger the encoding conversion."
(integer) 1
127.0.0.1:6379> OBJECT ENCODING user:01
"hashtable"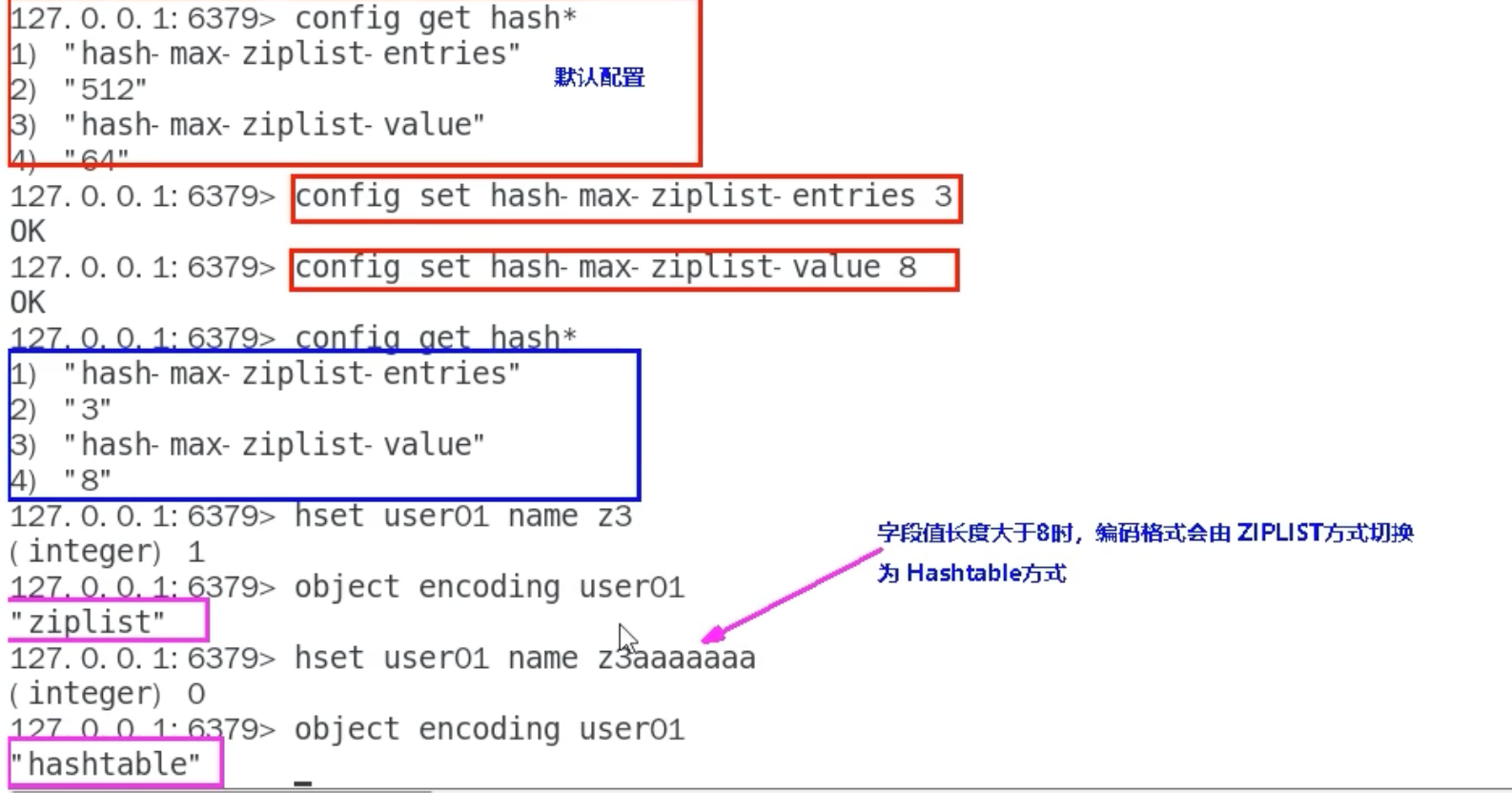
逻辑如下: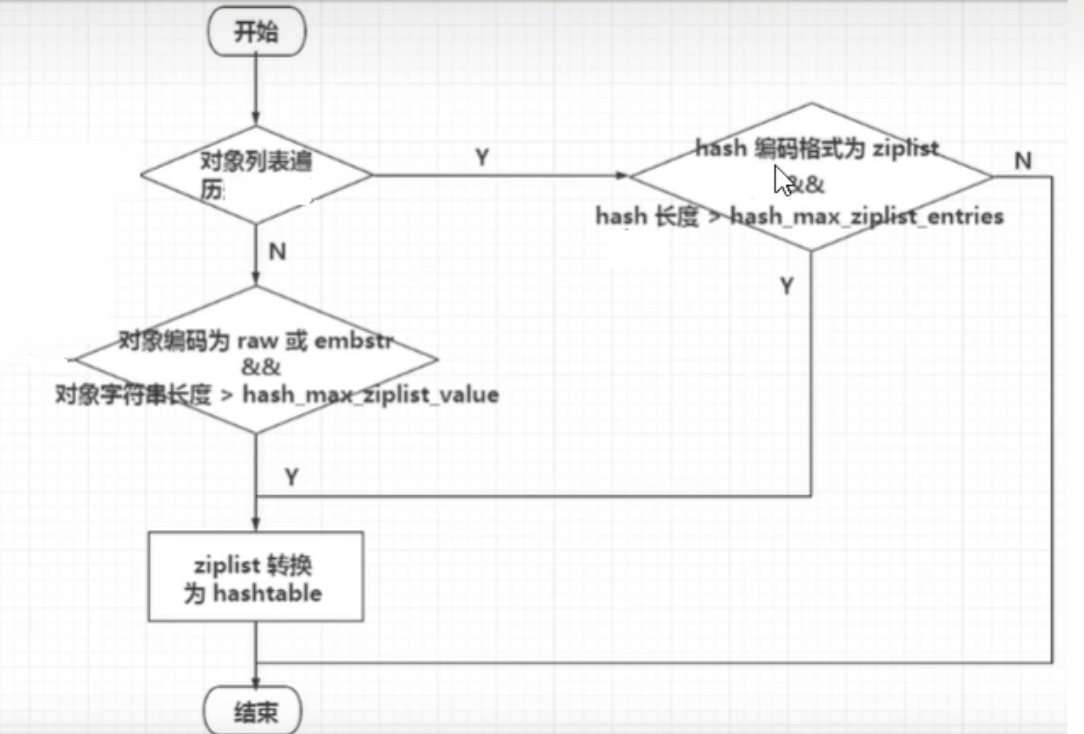
当紧凑不再:hashtable编码的登场
当一个Hash对象因为元素过多或过大,无法再使用节省空间的ziplist/listpack编码时,它就会采用OBJ_ENCODING_HT编码。这标志着它从一个紧凑的线性结构,演变成了一个真正的高性能哈希表——在Redis的源码中,它被称为字典 (dictionary) 。
OBJ_ENCODING_HT这种编码方式是Redis实现O(1) 平均时间复杂度读写的核心。它的内部结构是经典的“数组 + 链表”设计。

- 顶层结构 (
dict ) : 这是hashtable的“指挥中心”。它内部包含两个哈希表(ht[0]和ht[1]),这种设计是为了实现平滑的渐进式rehash(扩容),避免因数据迁移而导致服务长时间阻塞。 - 哈希表实现 (
dictht ) : 这是“数组”部分,一个由指针组成的数组,我们称之为“桶”(bucket)。 - 哈希节点 (
dictEntry ) : 如果多个键(Key)通过哈希计算后落入同一个“桶”,它们就会通过指针连接成一个链表,这就是“链地址法”解决哈希冲突的经典实现。每个dictEntry节点都包含了指向键和值的指针。
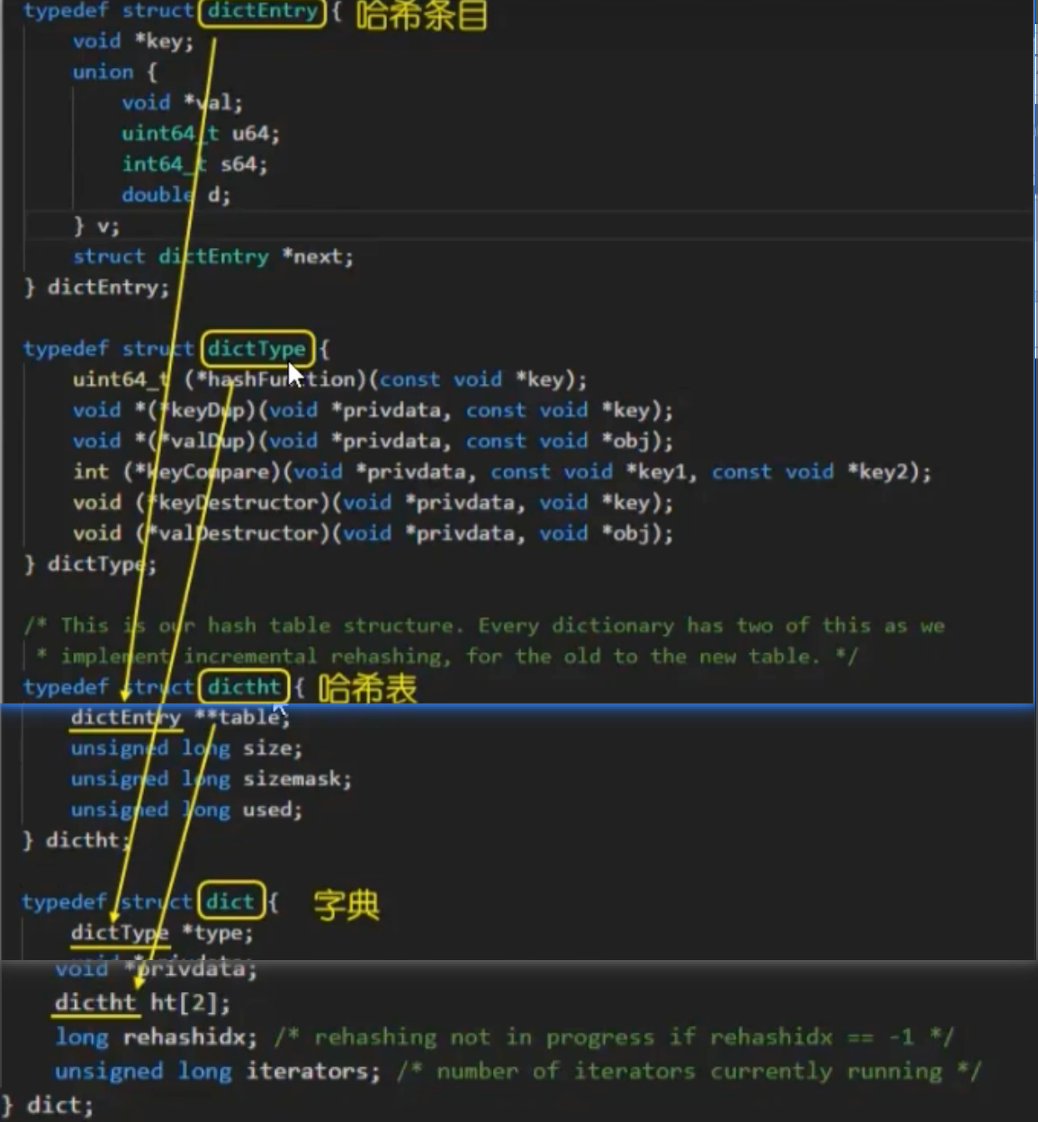
总结来说,
- 一个redisObject的ptr指针指向一个dict结构。
- dict结构中的ht[0]指向一个dictht(主哈希表)。
- dictht的table是一个指针数组。
- 数组的每个索引位置(“桶”)通过哈希函数 hash(key) & sizemask 来确定。
- 如果该位置没有元素,则指针为NULL。
如果该位置有元素,则指针指向第一个dictEntry。
如果发生哈希冲突,后续的dictEntry通过next指针形成一个链表。
redisObject
↓ ptr
dict
↓ ht[0]
dictht
↓ table (size=4)
+-----------+
| index 0 | → NULL
+-----------+
| index 1 | → [dictEntry: key="a"] → [dictEntry: key="c"] → NULL
+-----------+
| index 2 | → [dictEntry: key="b"] → NULL
+-----------+
| index 3 | → NULL
+-----------+源码片段解读:HSET命令背后的编码转换
当我们执行HSET命令时,Redis内部是如何决策和执行编码转换的呢?其核心逻辑位于hsetCommand函数中,它会调用更底层的函数来处理。
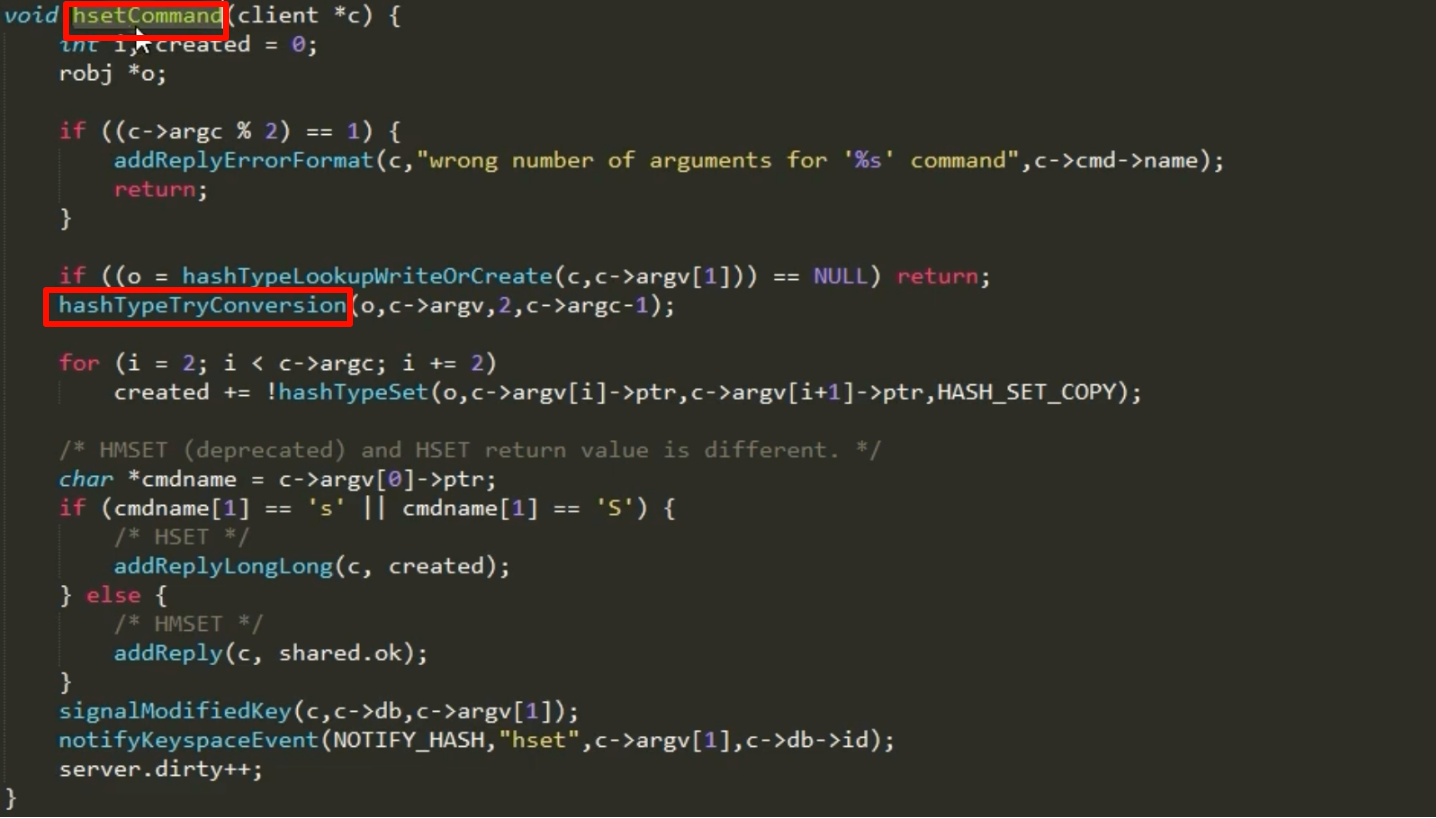
在对象创建和修改的函数中(如hashTypeSet),存在类似下面这样的关键判断逻辑:
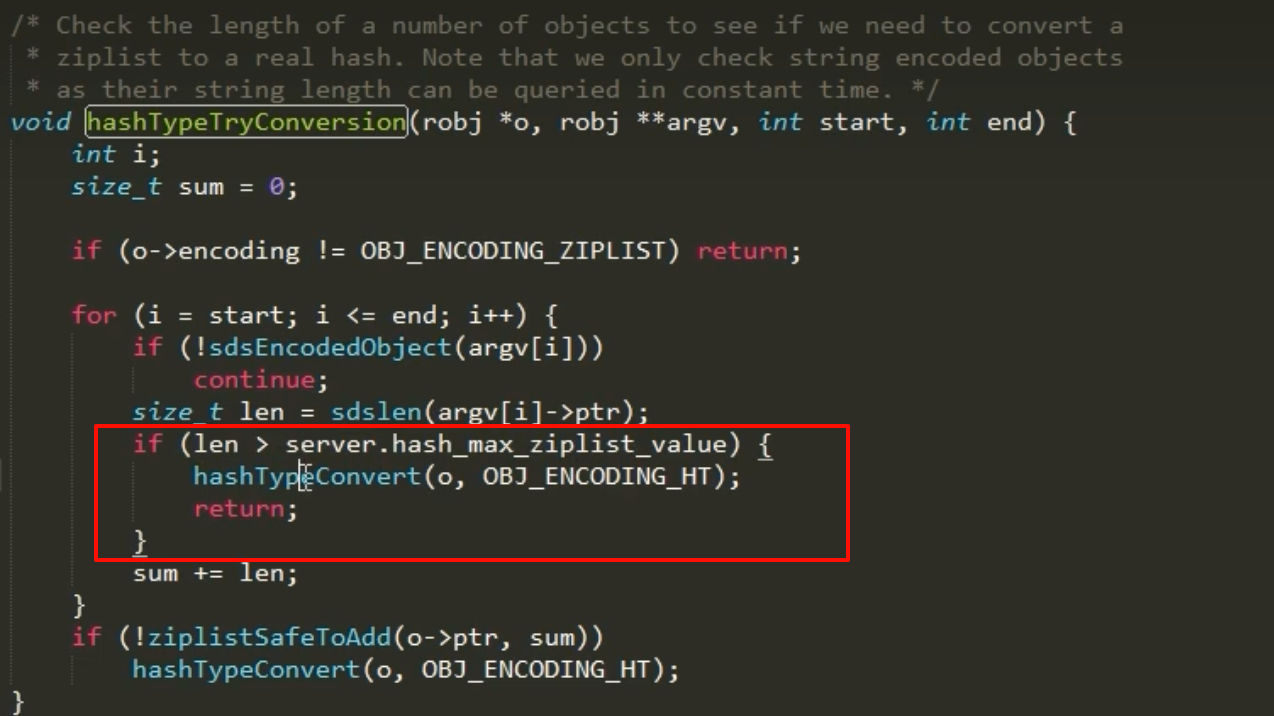
源码逻辑解读:
- 检查字段长度:在向Hash对象添加新字段前,代码会首先检查新加入的
field和value的长度是否超过了server.hash_max_ziplist_value(或listpack的对应配置)。 - 检查条目数量:如果长度检查通过,代码还会检查添加新元素后,总条目数是否会超过
server.hash_max_ziplist_entries。 - 触发转换:如果上述任一检查不通过,且当前编码是
ziplist(或listpack),Redis就会调用hashTypeConvert函数。这个函数会创建一个新的hashtable,并将旧ziplist中的所有数据迁移到新的hashtable中,最后释放旧的ziplist。
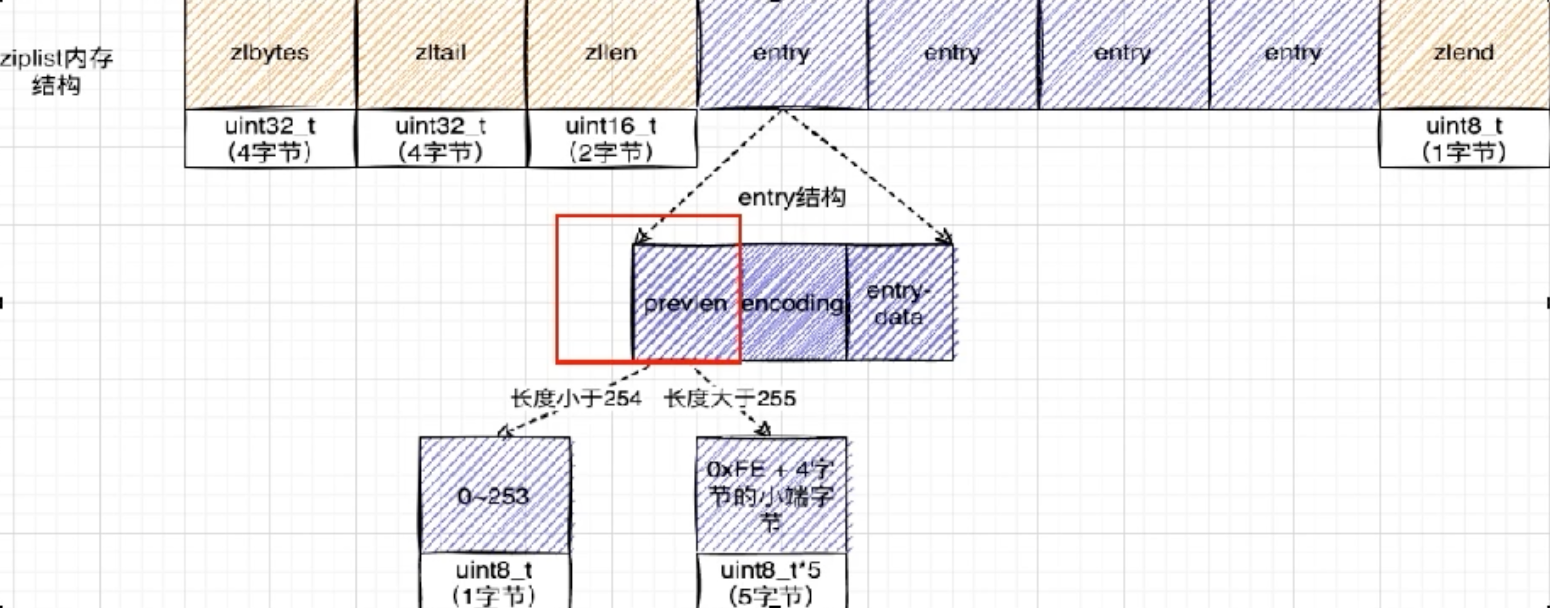
ziplist
ziplist(压缩列表)是Redis早期为了极致地节省内存而设计的一种数据结构。它的核心思想是:以部分读写性能为代价,换取极高的内存空间利用率。
Redis官方对Ziplist的描述 (ziplist.c):
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time. However, because every operation requires a reallocation of the memory used by the ziplist, the actual complexity is related to the amount of memory used by the ziplist.
ziplist 的内存布局
ziplist将所有数据存储在一块连续的内存中。它没有传统双向链表的prev和next指针,而是通过存储前一个节点的长度来实现反向遍历。
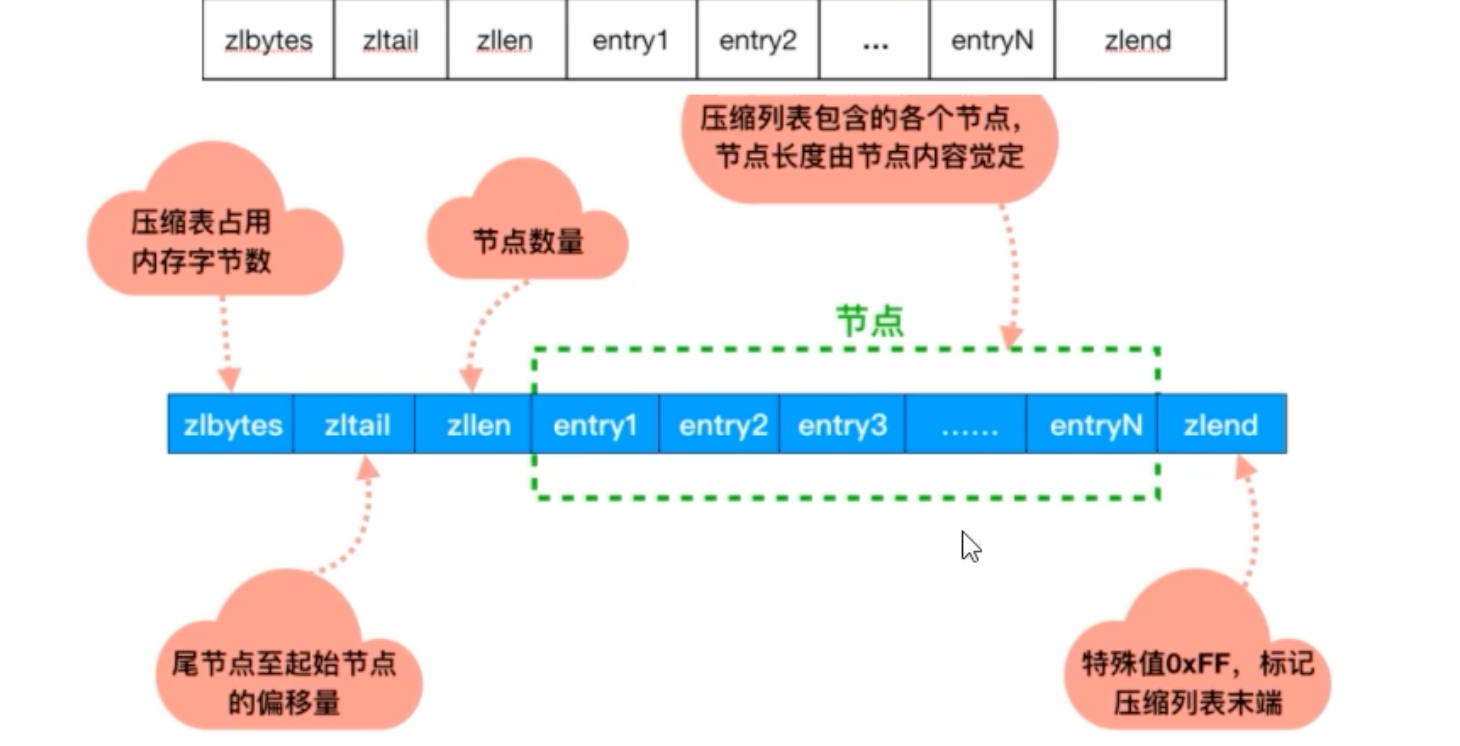
一个ziplist由以下几部分组成:
-
zlbytes: 整个ziplist的总字节数。 -
zltail: 到达尾节点的偏移量,用于快速定位尾部。 -
zllen: 节点数量。 -
entry: 若干个数据节点。 -
zlend: 特殊的结束标记 (0xFF)。
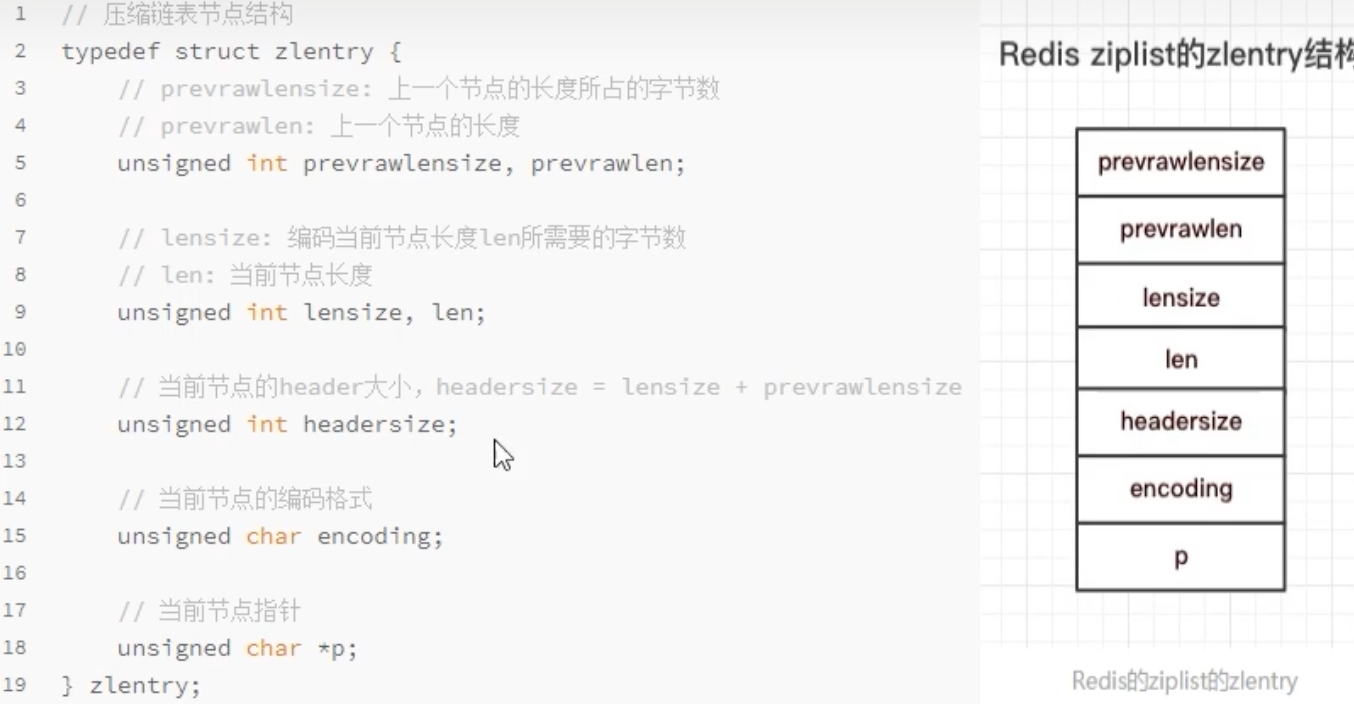
zlentry 节点结构
每个entry是ziplist的核心,其结构如下:
-
previous_entry_length: 记录前一个节点的长度。这是ziplist能够反向遍历的关键,也是其致命缺陷的根源。 -
encoding: 记录当前节点数据的类型。 -
content: 实际存储的数据。
通过previous_entry_length,ziplist可以从当前节点指针减去该长度,从而找到前一个节点的起始地址,实现了O(1)复杂度的反向跳转。
“ziplist 不是有 len 吗?为什么还要 prev_length ?”
ziplist 有 len,但它只是『数据部分的长度』,不是整个 entry 的总长度。它没有 self_total_len,所以必须依赖 prev_length 来实现正向跳转。
“连锁更新”问题
ziplist的设计初衷虽好,但previous_entry_length字段的存在引入了一个灾难性的问题——连锁更新 (Cascading Update) 。
previous_entry_length字段本身是变长的(1字节或5字节)。
- 如果前一个节点的长度
< 254字节,它占用1字节。 - 如果前一个节点的长度
>= 254字节,它占用5字节。
灾难场景:
假设我们有一个
ziplist,其中包含一连串长度都为250-253字节的节点。此时,每个节点的previous_entry_length都占用1字节。
现在,我们在头部插入一个长度
>= 254字节的新节点。
原先的第一个节点(
entry1)现在需要更新它的previous_entry_length来记录新头的长度。这个字段必须从1字节扩展到5字节。连锁反应开始:
entry1因为自身增加了4个字节,其总长度很可能也超过了254字节。这导致它的后继节点entry2也必须将其previous_entry_length从1字节扩展到5字节。这个过程像多米诺骨牌一样,一个接一个地向后传播,可能导致整个
ziplist进行大规模的空间重分配。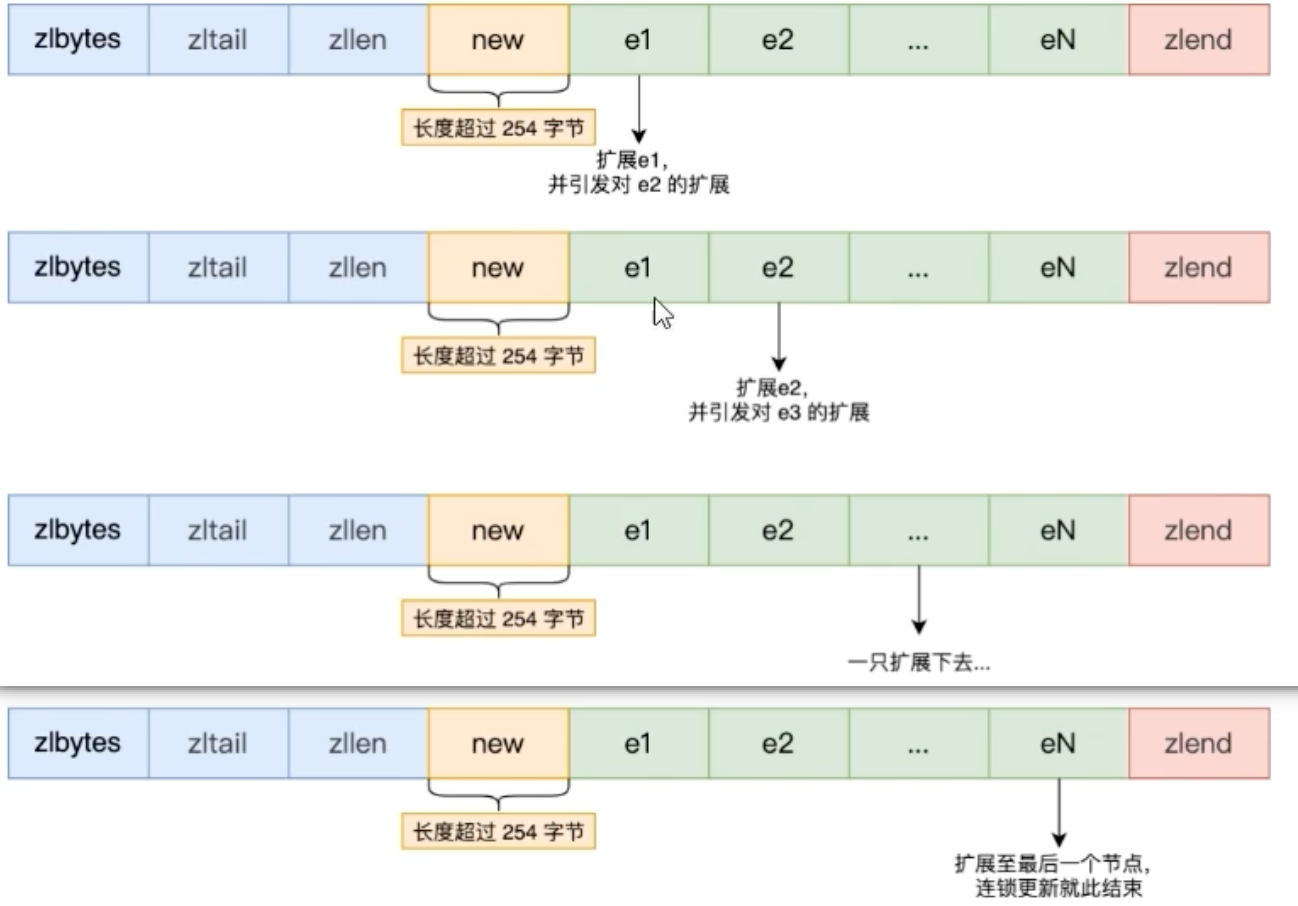
这种在最坏情况下需要O(N^2)复杂度的连锁更新,使得ziplist在某些场景下性能变得不可预测,成为了Redis一个待优化问题。
listpack
为了彻底根除“连锁更新”问题,Redis 7中引入了listpack(紧凑列表)作为ziplist的替代品。
listpack 的核心变化
listpack的设计非常巧妙,它解决了问题的根源:
listpack 的每个节点不再存储前一个节点的长度,而是只存储自己的元信息和内容。

一个listpack的entry结构如下:
-
encoding-type: 编码类型。 -
element-data: 元素数据。 -
element-total-len: 当前节点自身的总长度。
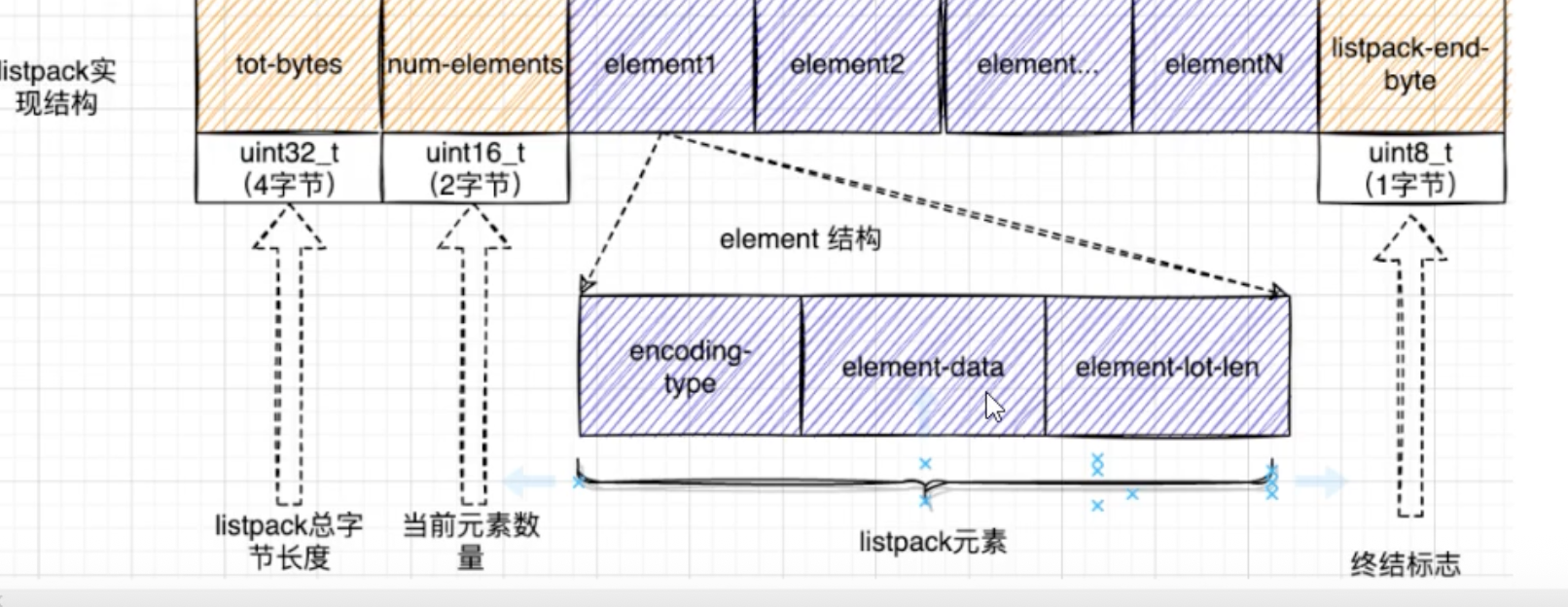
如何实现反向遍历?
既然不存前一个节点的长度,listpack如何从后往前遍历呢?
答案是:从后往前“跳” 。
- 指针首先指向
listpack的末尾。 - 通过末尾的
listpack-end-byte向前一个字节,定位到最后一个节点的末尾。 - 解析最后一个节点的
element-total-len字段,知道了该节点的总长度。 - 用当前指针减去这个长度,就精确地跳到了该节点的起始位置,也就是倒数第二个节点的末尾。
- 重复此过程,即可实现高效且安全的反向遍历。
通过这个设计,对listpack中任何一个节点的修改,都只会影响该节点自身的空间,绝不会波及其后继节点,从而彻底杜绝了连锁更新问题。
遍历机制的对决 —— ziplist vs listpack
最后让我们来深入对比一下这两种结构在正向和反向遍历上的设计。
正向遍历
正向遍历的目标很简单:从当前节点的起始位置,准确地跳转到下一个节点的起始位置。
ziplist 的正向遍历:计算后前进
结构:
[prev_len] [encoding] [content]流程:
- 指针位于当前
entry的起始位置。 - 解析
encoding 字段,这是一个“自描述”字段,通过解读它的前几个比特位,可以计算出content的长度。 - 计算出当前
entry 的总长度:总长度 = sizeof(prev_len) + sizeof(encoding) + sizeof(content)。 - 将当前指针加上这个计算出的总长度,即可跳到下一个
entry。
- 指针位于当前
- 特点:前进的“步长”是动态计算出来的。
listpack 的正向遍历:计算后前进(类似)
结构:
[encoding] [content] [self_total_len]流程:
- 指针位于当前
entry的起始位置。 - 解析
encoding 字段,同样可以计算出content的长度。 - 计算出当前
entry 的总长度(不含self_total_len部分)。 - 将当前指针加上这个计算出的长度,即可跳到
self_total_len 字段,再跳过它,到达下一个entry。
(或者,直接读取self_total_len字段,然后用当前指针加上它)
- 指针位于当前
特点:与
ziplist 类似,前进的步长也需要通过解析encoding来确定。
正向遍历对比结论:在正向遍历上,两者思路相似,都需要通过解析 encoding 来确定前进的距离,性能差异不大。
反向遍历—— 核心差异所在
反向遍历的目标是:从当前节点的起始位置,准确地跳转到前一个节点的起始位置。这正是两种结构分道扬镳的地方。
ziplist 的反向遍历:直接读取,精确后退
结构:
[prev_len] [encoding] [content]流程:
- 指针位于当前
entry的起始位置。 - 直接读取位于最头部的
prev_len 字段。这个字段直接、显式地存储了前一个节点的总长度。 - 将当前指针减去
prev_len的值。 - 指针就精确地回到了前一个
entry 的起始位置。
- 指针位于当前
特点:后退的“步长”是直接读取的,非常高效。但正是这个
prev_len字段,导致了“连锁更新”的致命问题。它让节点之间产生了紧密的物理耦合。
listpack 的反向遍历:先定位,再读取,然后后退
listpack 抛弃了 prev_len,那么它如何后退呢?答案是“从后往前看”。
结构:
[encoding] [content] [self_total_len]流程:
- 指针位于当前
entry 的起始位置。这个位置同时也是前一个 entry 的结束位置。 - 从这个位置向前读取1个字节,这个字节是前一个
entry 的self_total_len 字段的最后一部分。 -
self_total_len 字段本身也是变长的,但它的编码方式允许我们从后往前解析,从而解码出前一个 entry 的完整总长度。 - 将当前指针减去这个解码出的“前一个
entry的总长度”。 - 指针就精确地回到了前一个
entry 的起始位置。
- 指针位于当前
特点:后退的“步长”是通过读取前一个节点的尾部信息来解码的。这个过程比
ziplist略微复杂,但它彻底解除了节点间的耦合,根治了连锁更新。
总结
| 遍历方式 | ziplist (压缩列表) | listpack (紧凑列表) |
|---|---|---|
| 正向遍历 | 计算后前进 (解析encoding算总长) | 计算后前进 (解析encoding算总长) |
| 反向遍历 | 直接后退 (读取prev_len字段) | 解码后后退 (读取前一个节点的self_total_len字段) |
| 设计核心 | 依赖 prev_len 字段 | 依赖 self_total_len 字段 |
| 优点 | 反向遍历的实现非常直接。 | 彻底解决了连锁更新问题,更新操作稳定高效。 |
| 缺点 | 连锁更新的致命风险。 | 反向遍历的逻辑比 ziplist 略微复杂。 |
Redis如何实现无感扩容?
当一个Redis Hash对象的编码从ziplist/listpack升级为hashtable后,它就拥有了O(1)的平均读写性能。但这份高性能的背后,有一个持续的挑战:当哈希表变得越来越拥挤,哈希冲突增多,性能就会退化。此时,就需要对哈希表进行扩容,这个过程被称为Rehash。
如果一次性将一个包含数百万个键的哈希表进行Rehash,需要将所有数据从旧表迁移到新表,这可能会导致Redis服务出现秒级的阻塞,对于追求低延迟的Redis来说是不可接受的。为了解决这个难题,Redis实现了一种极其优雅的方案——渐进式Rehash (Progressive Rehashing) 。
一次性Rehash的痛点
想象一下,如果我们要给一个住满了数百万人的“旧小区”(旧哈希表)进行升级搬迁。
- 一次性方案:封锁整个小区,用大巴车把所有人一次性运到“新小区”(新哈希表)。在搬迁的几个小时内,整个小区对外“暂停服务”。
- 问题:对于Redis这样的实时服务来说,这种长时间的“暂停服务”是致命的。
“蚂蚁搬家”式的渐进方案
渐进式Rehash的核心思想,就是将庞大的迁移工作分摊到多次操作中,避免单次操作耗时过长。它就像“蚂蚁搬家”,每次只搬一点点,最终完成整个搬迁过程,而在此期间,对外服务几乎不受影响。
核心结构:双哈希表
实现渐进式Rehash的基础,是dict结构体中包含的两个哈希表(dictht)。
// dict.h in source code
typedef struct dict {
// ...
dictht ht[2]; // ht[0]是“旧小区”,ht[1]是“新小区”
long rehashidx; // 搬家进度指示器。-1表示不在搬家
// ...
} dict;-
ht[0]:当前正在使用的主哈希表(旧小区)。 -
ht[1]:只在Rehash期间使用的新哈希表(新小区)。 -
rehashidx:一个整数索引,用于追踪搬家的进度。当rehashidx = -1时,表示没有在进行Rehash。
Rehash的完整流程
第一步:触发与准备
当哈希表的负载因子(used / size)超过某个阈值时,Rehash被触发。
- Redis为
ht[1]分配一个更大的空间(通常是ht[0]大小的两倍)。 - 将
dict->rehashidx设置为0,标志着Rehash过程正式开始。
第二步:渐进式迁移
这是整个机制最核心的部分。数据的迁移工作会在两个时机进行:
- 主动迁移:在处理每一次对该字典的增、删、改、查操作时,除了完成客户端的请求,Redis还会“顺便”将
ht[0]中一个桶(由rehashidx索引指定)的所有数据,迁移到ht[1]中。然后rehashidx加1。 - 被动迁移:为了防止数据库在长期没有访问(“空闲”)时导致Rehash永远无法完成,Redis的后台定时任务(
serverCron)会周期性地检查是否有正在进行的Rehash,并主动执行一小部分迁移工作。
第三步:Rehash期间的读写操作
在数据被分散在ht[0]和ht[1]的“过渡期”,读写操作必须遵循以下规则:
- 写入 (Add/Set) :所有新的键值对都只写入
ht[1] 。这样可以确保ht[0]的数据只减不增,最终会变空。 - 读取 (Get) / 更新 (Update) / 删除 (Delete) :会先在
ht[0] 中查找,如果没找到,再去ht[1] 中查找。
这种双表查询的策略,保证了在Rehash期间数据的可访问性。
第四步:完成Rehash
当ht[0]中的所有数据都迁移到ht[1]后:
-
ht[0]的内存被释放。 -
ht[1]被设置为新的ht[0]。 -
ht[1]的指针被置为NULL,为下一次Rehash做准备。 -
rehashidx被重置为-1。
此时,整个Rehash过程平滑地完成了。
源码视角:渐进式Rehash的实现
1. 迁移“一小步”
dictRehash函数负责实际的数据迁移工作。参数n代表要迁移多少个桶。在渐进式Rehash中,n通常是1。
// dict.c
int dictRehash(dict *d, int n) {
// ...
// 循环 n 次,每次迁移一个桶
while(n-- && d->ht[0].used != 0) {
// ... (省略空桶检查逻辑) ...
// de 指向 ht[0] 中 rehashidx 桶的第一个节点
dictEntry *de = d->ht[0].table[d->rehashidx];
// 遍历该桶的链表,将所有节点迁移到 ht[1]
while(de) {
dictEntry *nextde = de->next;
// 计算在新表 ht[1] 中的索引
unsigned int h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 头插法将节点插入到新表 ht[1] 的链表中
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
// 将旧桶清空
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// ...
}2. 操作时“顺便”迁移
在执行增删改查等操作的函数中,都会在开头调用一个辅助函数来尝试执行一小步Rehash。
// dict.c
// 这个宏或函数会在很多字典操作函数的开头被调用
static int _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d, 1);
return 1;
}
// 示例:在 dictAddRaw 函数中
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
// 在执行真正的添加操作前,先尝试执行一小步rehash
if (dictIsRehashing(d)) _dictRehashStep(d);
// ... 后续的添加逻辑 ...
}3. 读写时的双表操作
在查找函数dictFind中,逻辑清晰地体现了双表查询。
// dict.c (逻辑伪代码)
dictEntry *dictFind(dict *d, const void *key) {
// ...
// 首先在 ht[0] 中查找
de = dictFindEntry(d, &d->ht[0], key);
// 如果正在rehash,且在ht[0]中没找到,则去ht[1]中查找
if (de == NULL && dictIsRehashing(d)) {
de = dictFindEntry(d, &d->ht[1], key);
}
return de;
}渐进式Rehash是Redis设计哲学中“实用主义与性能并重”的完美体现。它通过将一次高成本的密集型操作,巧妙地分解成无数次低成本的微操作,并将其“寄生”在日常的命令请求中,最终在用户几乎无感知的情况下,完成了哈希表的扩容,确保了Redis服务的高可用性和低延迟。
“渐进式rehash的时候有并发情况怎么办?
在Redis的世界里,对于单个字典(dictionary)的Rehash过程,不存在传统意义上的“并发情况”,因为Redis的命令处理是单线程的。
Rehash如何融入单线程模型?
渐进式Rehash的每一个“小步骤”都是嵌入在某个命令的执行过程中的。我们再回顾一下这个流程:
- 客户端发送一个命令(如
HSET myhash field value)。 - Redis主线程接收到这个命令,开始执行
hsetCommand函数。 - 在
hsetCommand函数的内部,它会先检查myhash对应的字典是否正在进行Rehash。 - 如果正在Rehash,它就会在同一个线程中,调用
_dictRehashStep(),将ht[0]的一个桶迁移到ht[1]。 - 迁移这一小步完成后,
hsetCommand函数继续执行它原本的逻辑——将新的field和value添加到ht[1]中。 - 整个
hsetCommand函数执行完毕,向客户端返回结果。 - 此时,主线程才会去处理队列中的下一个命令。
关键点在于:
- Rehash是命令的一部分:迁移的那一小步,是作为当前命令执行流程的一部分,同步地、阻塞地完成的。由于这一步操作非常快(只迁移一个桶),所以它对命令的总延迟影响微乎其微。
- 不存在数据竞争:因为从Rehash的一小步开始,到命令的读写操作结束,所有这一切都发生在同一个线程里,完全是串行执行。
ht[0]和ht[1]根本没有机会被多个线程同时访问,因此也就不存在任何数据竞争或并发问题。
Rehash期间的迭代器(Iterator)问题
虽然没有多线程并发问题,但在单线程中,Rehash确实需要处理一个特殊的“并发”场景:当一个命令正在对字典进行长时间迭代(比如SCAN命令),而此时另一个命令触发了Rehash,该怎么办?
如果Rehash改变了哈希表的结构,正在进行的迭代器可能会“迷路”或重复/遗漏元素。
Redis对此也有巧妙的设计:
-
dict结构体中有一个iterators计数器,记录了当前有多少个活动的迭代器正在遍历该字典。 -
_dictRehashStep()函数在执行时,会检查这个iterators计数器。 - 如果
iterators > 0 ,为了保证迭代器的一致性,本次的渐进式Rehash步骤就会被跳过,不会进行数据迁移。
// dict.c
static int _dictRehashStep(dict *d) {
// 如果有活动的迭代器,则不进行rehash
if (d->iterators == 0) dictRehash(d, 1);
return 1;
}这确保了在有迭代器活动的“敏感时期”,哈希表的结构是稳定的。虽然这可能会稍微减慢Rehash的进度,但保证了数据的正确性,这是首要原则。
所以,对于“渐进式rehash的时候有并发情况怎么办?”这个问题,最精准的回答是:
由于Redis采用单线程模型处理命令,Rehash的每一步都与命令的执行同步进行,这从根本上杜绝了多线程并发访问导致的数据竞争问题。Redis通过将Rehash操作原子化地嵌入到每个命令中,保证了在任何时刻,哈希表的数据状态都是一致和安全的。对于可能存在的迭代器冲突,Redis则通过暂停Rehash的方式来保证迭代的正确性。