在现代应用架构中,缓存(如 Redis)与数据库(如 MySQL)的组合是提升性能的利器。我们最常用的模式是 Cache-Aside Pattern(旁路缓存) :
- 读请求:先读 Redis,命中则返回;未命中则读 MySQL,将结果写入 Redis 后再返回。
- 写请求:更新数据时,需要同时维护数据库和缓存中的状态。
问题恰恰出在第二步。只要涉及双写,就必然会遇到数据一致性的挑战。这篇文章将带你循序渐进地探讨这个问题,并分析各种策略的优劣。
核心议题:四种更新策略的博弈
当数据库数据发生变化时,我们如何处理缓存?主要有四种策略,我们来一一剖析。
策略一:先更新数据库,再更新缓存
这个方案看似直观,但在高并发下存在致命的线程安全问题。
【异常逻辑】两个线程 A 和 B 并发更新同一数据:
- 线程 A 更新数据库 (值: 100)
- 线程 B 更新数据库 (值: 80)
- 线程 B 更新缓存 (值: 80)
- 线程 A 更新缓存 (值: 100) <– 由于网络延迟等原因,A 的更新后到
最终结果:数据库中的值是 80,而缓存中的值是 100,数据永久性不一致。
策略二:先更新缓存,再更新数据库
这个方案问题更大。缓存的更新成功了,但数据库更新失败了怎么办?此时缓存中是新数据,数据库中是旧数据,数据同样不一致。
更重要的是,缓存应该是数据库的“镜像”,而不是权威数据源。业务上,我们永远应该以数据库(底单)为准。
既然“更新缓存”这条路走不通,我们换个思路:不更新,只删除。让数据在下次被读取时,通过 Cache-Aside 模式重新加载。
策略三:先删除缓存,再更新数据库
这个方案在高并发下也会引入问题。
【异常逻辑】一个写请求 A 和一个读请求 B 并发:
- 写请求 A 删除 Redis 缓存。
- 读请求 B 发现缓存未命中。
- 读请求 B 从数据库读取到旧值。
- 写请求 A 将新值写入数据库。
- 读请求 B 将旧值写回 Redis 缓存。

最终结果:数据库是新值,缓存是旧值,数据再次不一致,且这个脏数据会一直存在,直到下次更新或过期。
解决方案:延迟双删 (Delay Double Delete)
为了解决上述问题,我们可以在更新完数据库后,再进行一次删除。
- 删除缓存
- 更新数据库
- 休眠 N 毫秒
- 再次删除缓存
休眠的目的:休眠至关重要,它确保了“读请求回写缓存”的操作发生在“第二次删除”之前。休眠时间 N 需要大于一次“读请求 + 写缓存”的总耗时。这样,我们就能确保在写操作线程休眠结束后,并发的读线程已经完成了它“污染”缓存的动作,我们的第二次删除才能精准地将脏数据清除。
第二次删除的目的:这次删除是为了清除在步骤 1 和步骤 3 之间,由其他并发的读请求所写入的脏数据。正如我们上面分析的失败场景,请求 B 会将旧数据写回缓存,而请求 A 的第二次删除操作正是为了将这个旧数据清除。
问题:
- 吞吐量降低:写请求需要额外等待,性能开销大。
- 休眠时间难确定:这个时间需要大于“读 DB + 写 Cache”的总耗时,难以精确评估。
优化:可以将第二次删除操作异步化,减少写请求的等待时间。但这依然没有从根本上解决问题,只是一个“打补丁”的方案。

休眠时间 N 应该设置多久?
休眠时间的设置是这个方案的难点和关键。理论上,这个时间需要大于数据库主从复制的延迟加上读业务逻辑执行的时间。
- 为什么考虑主从复制延迟? 在读写分离的架构下,写操作在主库(Master),而读操作可能在从库(Slave)。请求 A 更新了主库,但数据同步到从库需要时间。如果请求 B 在数据同步完成前去从库读取,读到的必然是旧数据。因此,休眠时间必须覆盖掉这个数据同步的延迟窗口。
这个 N 值的确定需要经过审慎的业务评估和压力测试,它是一个经验值,并没有一个放之四海而皆准的标准。
策略四:先更新数据库,再删除缓存(业内推荐)
这是微软推荐的 Cache-Aside Pattern 的标准实践,也是目前业界最主流、最推荐的方案。

优势:
- 操作简单:逻辑清晰,代码实现简单。
- 安全性高:即使删除缓存失败,也只是在缓存过期前存在短暂的不一致,不会像“先删缓存”那样导致脏数据长期污染。
唯一的理论缺陷:
在“更新数据库成功”和“删除缓存”之间,有一个极短的时间窗口。如果此时恰好有读请求,会读到旧的缓存值。但这种情况概率极低,且影响短暂,对于绝大多数业务场景是可以接受的。
追求极致:如何保证最终一致性?
“先更新数据库,再删除缓存”虽然优秀,但仍有两个问题需要解决:
- 缓存删除失败怎么办?
- 如何应对高并发下读请求的“缓存击穿”?
方案一:失败重试与消息队列
如果删除缓存的步骤因为网络抖动或 Redis 故障而失败,数据就会出现不一致。我们需要一个补偿机制。
最常见的做法是异步重试:
- 将需要删除的缓存 Key 发送到一个消息队列(如 Kafka, RabbitMQ)中。
- 由一个独立的消费服务从队列中取出 Key,并尝试删除缓存。
- 如果删除失败,消息队列的重试机制会确保操作最终被执行。
这个方案保证了最终一致性,即使过程中出现短暂失败,最终状态也能修复。
方案二:终极武器 —— 订阅数据库变更日志 (Binlog)
上述方案需要在业务代码中耦合“发送消息”的逻辑。有没有更优雅、更解耦的方式?答案是 订阅 Binlog。
Canal 是阿里巴巴开源的一款优秀中间件,它可以模拟成一个 MySQL 的从库,实时订阅并解析主库的 Binlog 日志。
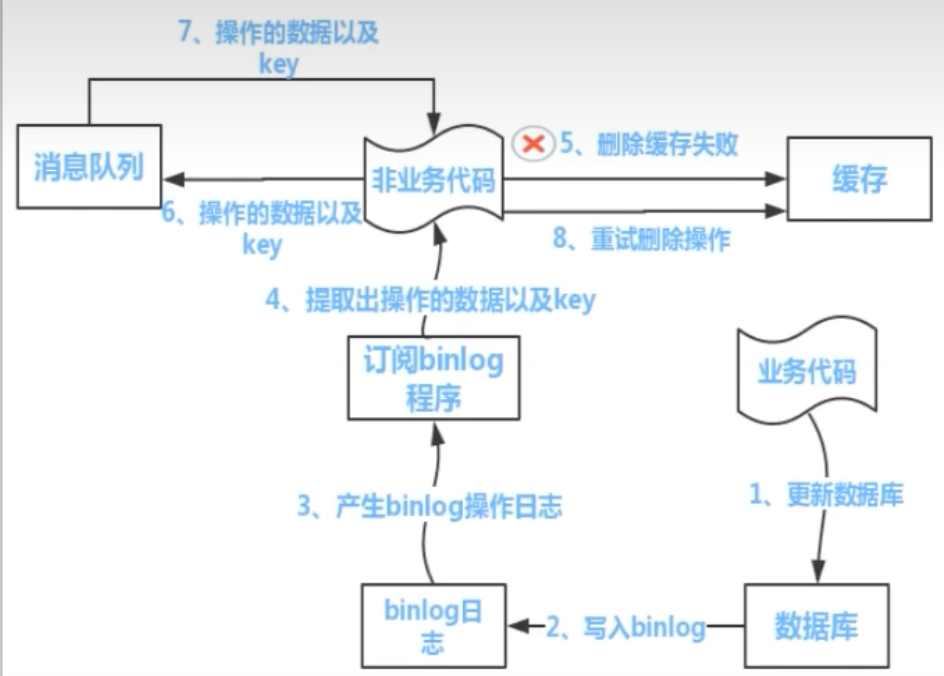
流程如下:
- 业务代码只管更新数据库,无需关心任何缓存操作。
- MySQL 将数据变更记录到 Binlog。
- Canal 订阅 Binlog,捕获到数据变更事件。
- Canal 将变更消息发送到消息队列。
- 一个独立的订阅服务消费消息,并精确地删除对应的缓存。
优势:
- 业务解耦:业务代码完全与缓存操作解耦。
- 可靠性极高:基于数据库的日志,不会漏掉任何变更。
- 保证最终一致性:结合消息队列的重试机制,是工业级的最终一致性解决方案。
补充:如何避免缓存击穿?—— 双检加锁 (Double-Checked Locking)
在 Cache-Aside 模式下,当一个热点 Key 过期时,大量并发请求会同时穿透到数据库,导致数据库压力剧增,这就是缓存击穿。
双检加锁是解决此问题的经典策略:
- 第一个线程获取到锁,去查询数据库。
- 其他线程在锁外等待。
- 第一个线程将数据写入缓存后,释放锁。
- 后续线程获取到锁后,再次检查缓存,发现已命中,直接返回,无需再查数据库。

这个策略能有效防止大量请求同时冲击数据库。
结论与总结
| 更新顺序 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 先更新库,再更新缓存 | – | 并发下导致永久不一致 | 严禁使用 |
| 先更新缓存,再更新库 | – | 违背数据源原则,DB 更新失败问题大 | 严禁使用 |
| 先删缓存,再更新库 | – | 高并发下会引入脏数据 | 不推荐,除非配合延迟双删,但实现复杂 |
| 先更新库,再删缓存 | 实现简单、安全 | 存在极短暂的不一致 | 绝大多数业务场景的首选 |
| 订阅 Binlog 异步删缓存 | 业务解耦、高可靠 | 架构变重,引入新中间件 | 对一致性要求极高的核心业务 |
核心建议:
在绝大多数业务场景下, “先更新数据库,再删除缓存” 是兼具性能、简单性和可靠性的最佳实践。如果删除失败,再引入消息队列进行异步重试作为补偿,即可保证数据的最终一致性。