揭秘操作系统如何与硬件设备对话
我们知道,操作系统是硬件的大管家。但 CPU 是如何精确地命令打印机打印一个字符,或者从硬盘读取一个数据块的呢?
今天,我们就来深入硬件的底层,看看 CPU 是如何通过总线、设备控制器和两种核心寻址方式,与外部设备进行高效通信的。
1. 硬件世界的“高速公路”:总线分层
CPU 与其他硬件组件并非随意连接,而是通过不同等级的“高速公路”——总线(Bus) 来通信。为了平衡成本与性能,总线通常是分层的:
内存总线:这是最快、最核心的“F1 赛道”,专为 CPU 和内存之间的高速数据交换而设计。它带宽高、距离短、成本高。
I/O 总线:连接 CPU 与各种外部设备。它又可细分为:
- 高速 I/O 总线 (如 PCIe) :靠近 CPU,为显卡、高速网卡这类需要巨大带宽的“VIP 设备”服务。
- 外围总线 (如 USB, SATA) :带宽较低,但成本低、可扩展性强,用于连接键盘、鼠标、硬盘、打印机等“平民设备”。
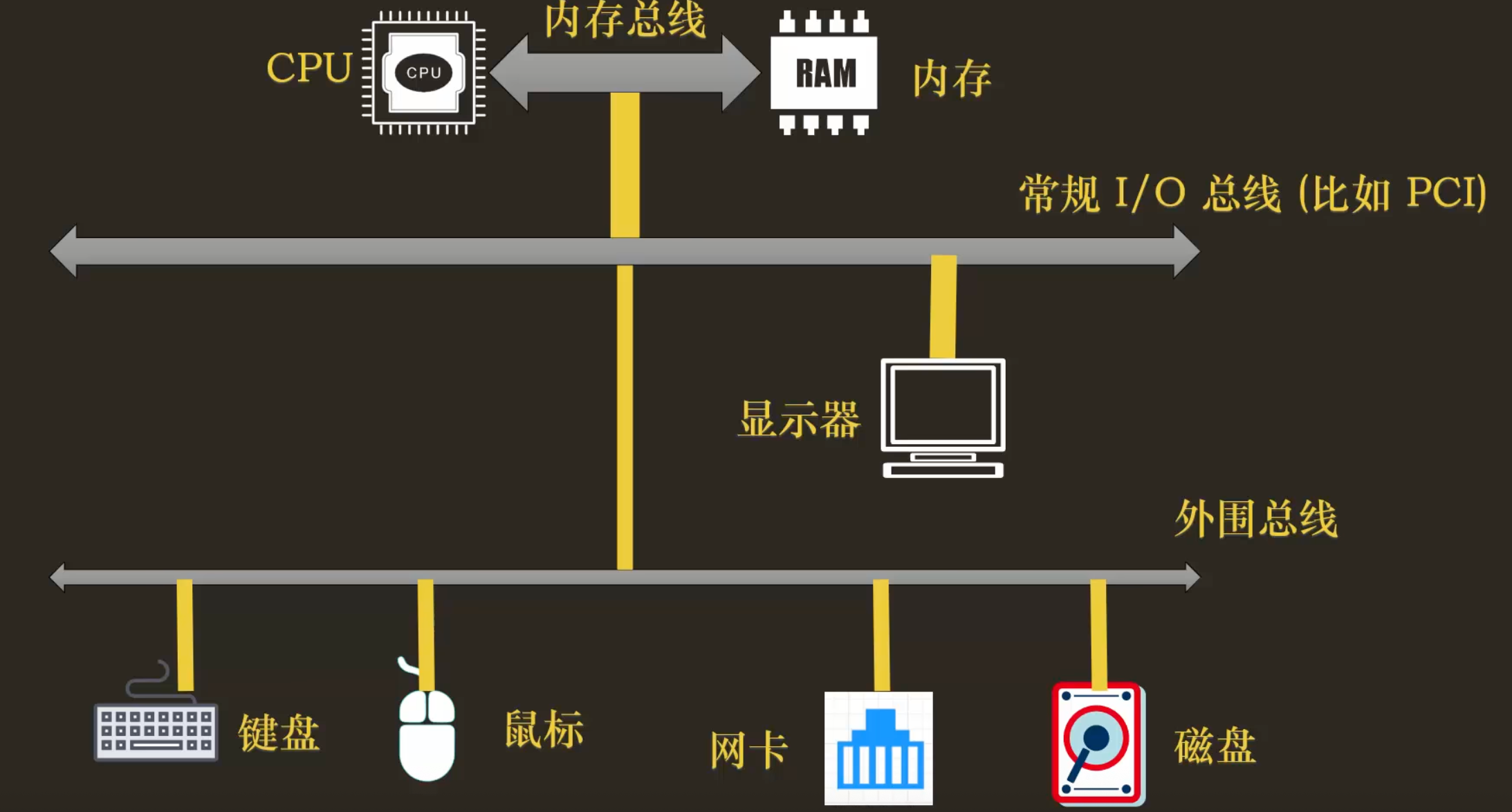
这种分层设计,确保了高性能设备能享受专属通道,而大量低速设备也能经济高效地接入系统。
2. 设备的“翻译官”:设备控制器
CPU 并不直接与打印机的喷头或硬盘的磁头对话,那样太复杂了。每个设备都配备了一个设备控制器(Device Controller) ,它像一个专业的“翻译官”和“秘书”,负责屏蔽设备内部的物理细节,向 CPU 提供一套简单、统一的编程接口。
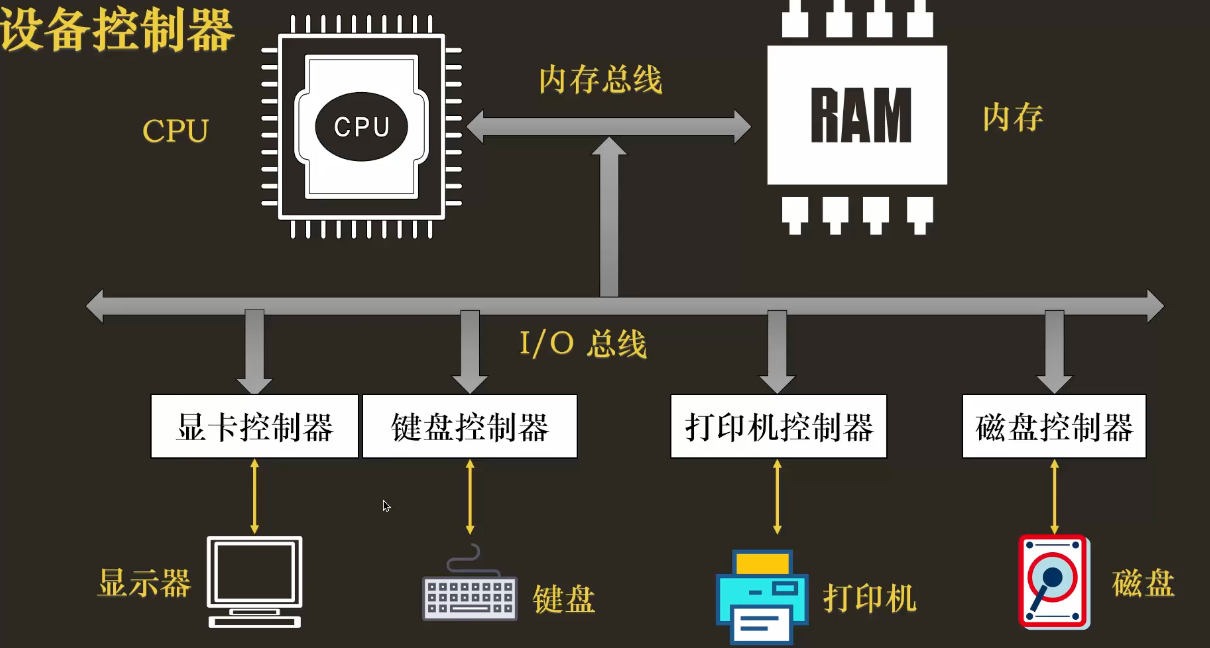
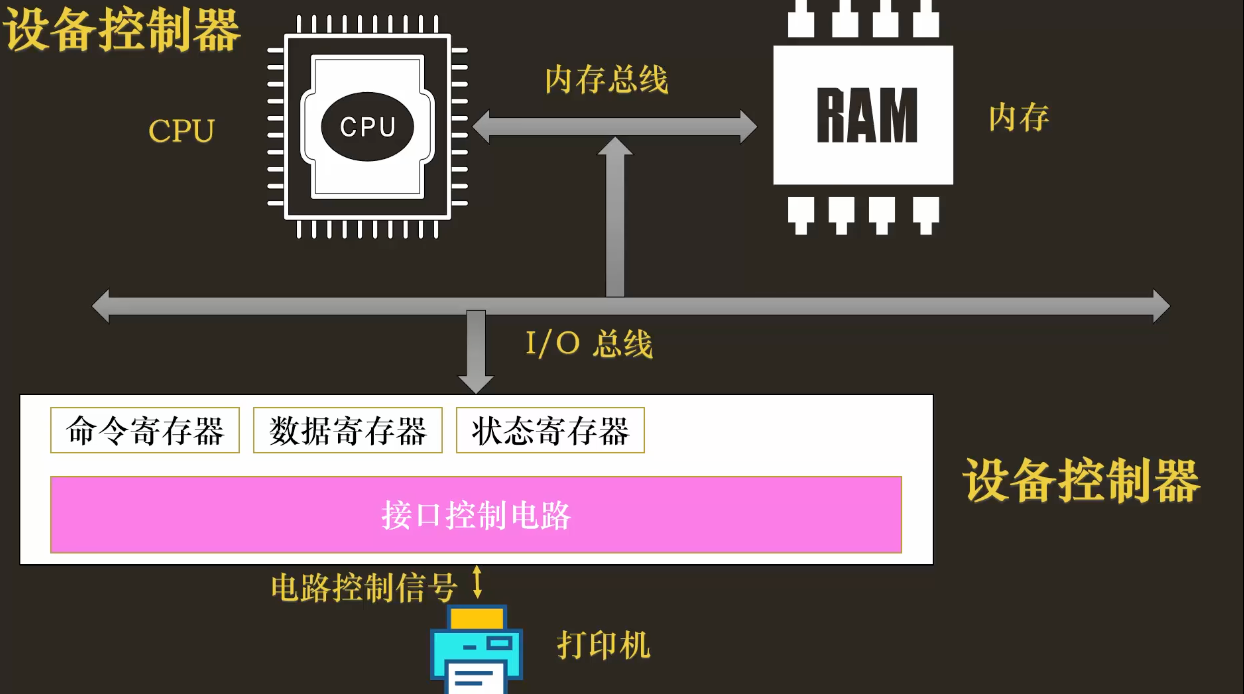
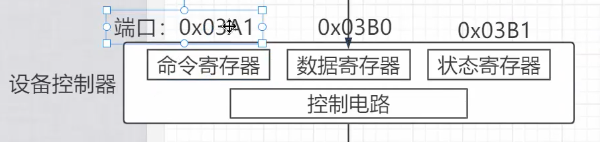
一个典型的设备控制器,会向 CPU 暴露三个核心的寄存器:
- 状态寄存器 (Status Register) :告诉 CPU 设备当前的状态,是“忙碌 (
BUSY)”、“空闲就绪 (READY)”还是“出错了 (ERROR)”。 - 命令寄存器 (Command Register) :CPU 在这里下达指令,比如
PRINT(打印)、READ(读取)、WRITE(写入)。 - 数据寄存器 (Data Register) :CPU 与设备之间交换数据的“中转站”。要打印的字符、从硬盘读出的数据,都通过这里传递。
3. 最原始的对话方式:轮询 (Polling)
在没有中断的古老时代,CPU 与设备控制器主要通过轮询(或称“忙等待”) 的方式协作。我们以连续打印 “A B C D” 为例,看看这个过程:
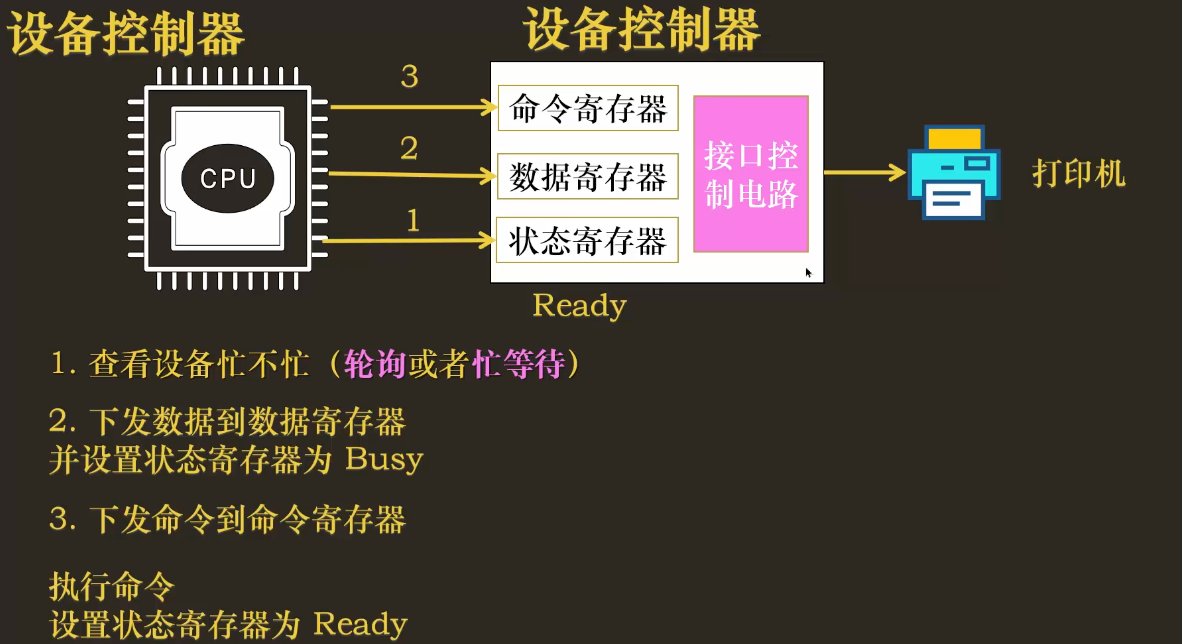
伪代码逻辑:
// 假设要打印一个字符
// 1. CPU 不断检查状态,直到设备空闲
while (STATUS_REGISTER == BUSY) {
// 什么也不做,原地空转 (spin/busy-waiting)
}
// 2. 设备空闲,CPU 开始下达任务
// 2.1 将要打印的字符写入数据寄存器
DATA_REGISTER = 'A';
// 2.2 将 PRINT 命令写入命令寄存器
COMMAND_REGISTER = PRINT;
// (在某些设计中,写入命令会自动将状态置为 BUSY)
打印 “A B C D” 的过程就是对上述逻辑的重复:每次发送一个字符前,CPU 都必须先通过循环忙等,确认打印机已经打印完上一个字符并处于 READY 状态,然后才能发送下一个。
缺点:在设备忙碌时,CPU 会陷入 while 循环100% 空转,这极大地浪费了宝贵的计算资源。因此,现代操作系统早已抛弃这种低效的方式,转向了更高效的中断驱动模型。
4. CPU 如何找到控制器:两种寻址“方言”
CPU 知道了要和控制器的寄存器对话,但它如何“找到”这些寄存器呢?这就像打电话需要电话号码一样,CPU 需要寄存器的“地址”。这里有两种主流的寻址方案:
4.1 端口映射 I/O (Port-Mapped I/O, PIO)
- 思路:为每个设备寄存器分配一个独立的“端口号” 。CPU 使用专门的、特权的
in /out 指令来访问这些端口。 - 特点:I/O 端口地址与内存地址是两个完全独立的地址空间。
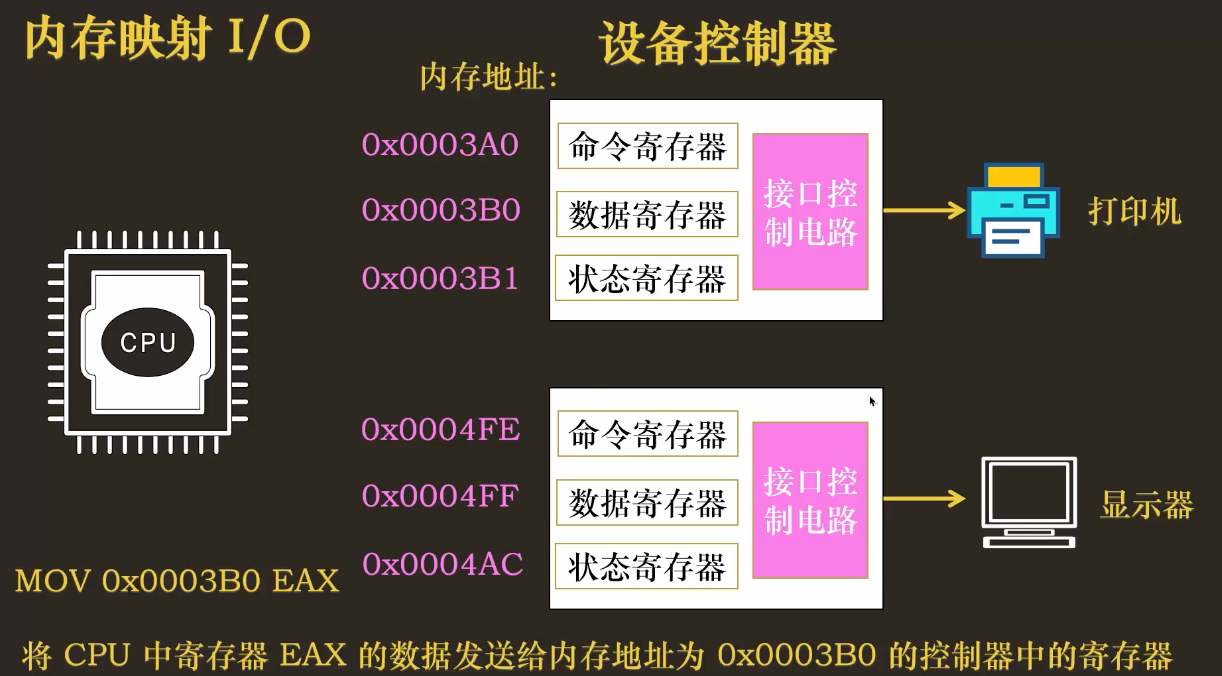
4.2 内存映射 I/O (Memory-Mapped I/O, MMIO)
- 思路:将设备寄存器 “映射”到物理内存的地址空间中。这样,CPU 就可以像访问普通内存一样,使用
mov等常规指令来读写这些寄存器。 - 特点:I/O 设备和内存在同一个地址空间中竞争地址。
PIO vs. MMIO 对照
| 维度 | 端口映射 I/O (PIO) | 内存映射 I/O (MMIO) |
|---|---|---|
| 寻址对象 | 端口号空间 (与内存地址分离) | 物理地址空间的一部分 |
| 指令 | 专用 in/out (特权) | 常规内存读写 (但需内核态权限与映射) |
| 编程模型 | 语义明确、指令功能少 | 可用普通 load/store,编程更灵活 |
| 生态 | 历史设备/PC 兼容性强 | 现代高性能设备普遍采用 |
| 安全 | 需内核态 | 需内核态 (通过页表权限控制) |
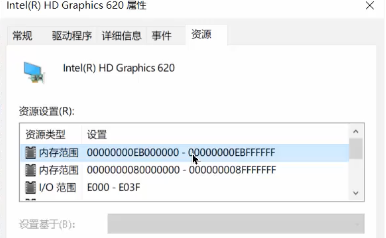
在现代计算机中,这两种方式通常并存。我们可以从 Windows 的设备管理器中清晰地看到这一点,一个设备会同时拥有 I/O 范围 (PIO) 和 内存范围 (MMIO) 。
5. 用户程序如何发起 I/O:系统调用的角色
一个至关重要的安全原则是:无论使用 PIO 还是 MMIO,访问设备寄存器的操作都必须在内核态执行。
那么,一个运行在用户态的应用程序(比如 Word)是如何发起打印请求的呢?
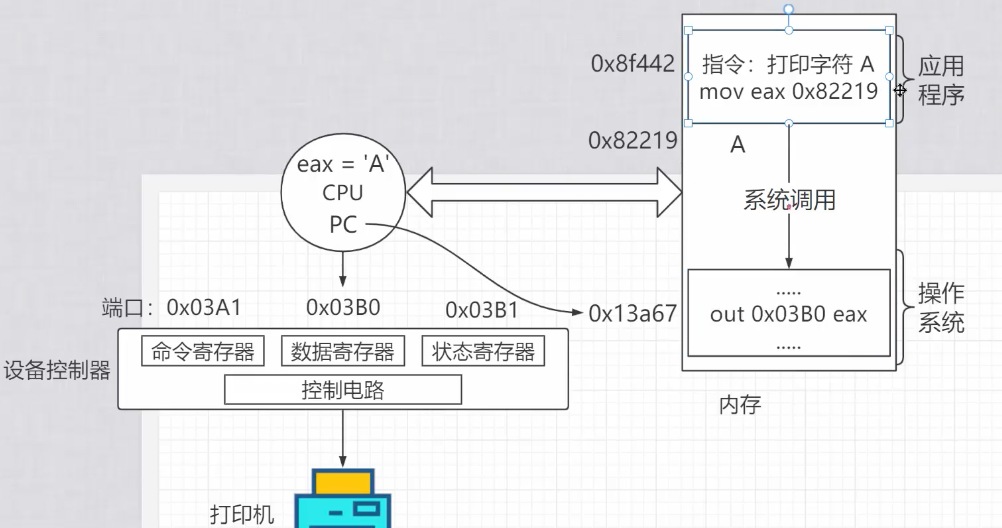
- 用户态应用准备好数据(如字符 ‘A’),然后调用一个库函数(如
write())。 - 这个库函数会触发一个系统调用,导致 CPU 执行陷入指令,从用户态切换到内核态。
- 进入内核后,操作系统会找到对应的驱动程序。
- 驱动程序负责执行底层的
in/out 或mov [MMIO]指令,与设备控制器进行真正的“对话”。 - 操作完成后,从内核态返回用户态,应用程序继续执行。
记忆法则:“用户态不能碰设备寄存器;一切走系统调用;由内核/驱动代劳”。
6. 课后思考
为什么高性能设备更偏向 MMIO + DMA + 中断 的组合?
一句话:MMIO 让寄存器访问更高效与可编程,DMA 让大块数据“免 CPU 搬运”,中断避免忙等待,三者配合在高吞吐/低延迟场景下能把CPU 从搬运与轮询中解放出来。
要点
- MMIO:把设备寄存器映射到物理地址,用普通读写指令访问;便于暴露**队列基址、长度、门铃(doorbell)**等寄存器,编程模型清晰、可流水线化(配合内存屏障保证次序)。
- DMA:数据由设备直接在设备↔内存间搬运;CPU 只做准备描述符、更新生产者索引、敲门铃,显著降低 CPU 占用与内存拷贝。
- 中断(MSI/MSI-X) :完成/就绪时由设备主动通知;支持中断亲和/多队列,减少忙等与轮询开销,可配合中断合并降低中断风暴。
- 效果:高吞吐(多队列+DMA 并行)、低延迟(免轮询)、低 CPU(免搬运)。
典型对比:PIO + 轮询 = CPU 频繁 in/out + while 等待;MMIO + DMA + 中断 = CPU 主要做控制面,数据面由硬件跑。
若把“逐字符打印”改成“批量打印缓冲区”,驱动需要增添哪些机制(例如环形队列、一次提交多字节等)?
在多核场景下访问 MMIO 寄存器,为何要使用内存屏障 (Memory Barrier) ,以避免因“写合并”或“乱序执行”带来的设备时序问题?(可结合 Java 的
volatile关键字思考)一句话:CPU/编译器可能乱序或写合并,会让“先写队列再敲门铃”的时序在设备侧被颠倒;内存屏障强制提交顺序,确保设备按预期看到数据与命令。
volatile 提供happens-before 的可见性/有序性:写后对读可见且不被重排。驱动里的内存屏障就像把“写描述符”与“写门铃”之间建立起一个顺序保证点,确保设备按同样顺序观察到状态变化。