在现代应用架构中,Redis 缓存是提升系统性能、抵御高并发流量的“第一道防线”。然而,这道防线并非坚不可摧。在实际应用中,我们常常会遇到缓存预热、雪崩、穿透、击穿以及数据不一致等挑战。
本文将系统性地剖析这些问题,阐明它们各自的成因、区别,并提供一系列经过实践检验的解决方案。
一、 缓存预热 (Cache Pre-heating)
1. 什么是缓存预热?
缓存预热指的是在系统启动或重大更新后,在用户请求到达之前,主动将一部分热点数据加载到 Redis 缓存中的过程。
场景举例:假设我们刚刚完成了一次版本发布,或者在数据库中新增了一批热门商品。此时,Redis 缓存中是没有这些新数据的。如果没有预热,那么第一波访问这些新商品的用户请求,都会直接打到后端的 MySQL 数据库上,可能造成数据库瞬时压力过大。
2. 为什么需要预热?
其核心目标是避免系统启动初期的冷启动(Cold Start)问题。通过预先加载数据,可以确保大部分初始请求都能命中缓存,从而获得最佳的响应性能,同时保护后端数据源。
3. 如何实现缓存预热?
- 手动脚本触发:在系统部署完成后,通过编写独立的脚本或接口,手动执行一次数据加载任务,将数据库中的热点数据查询出来并写入 Redis。这通常在流量较低的深夜进行。
- 项目启动时自动加载:在服务启动阶段,可以利用 Spring 的
@PostConstruct注解或ApplicationRunner接口,在项目初始化时自动执行缓存加载逻辑。这种方式适合加载一些相对固定的、必须的数据,如配置信息、白名单等。
二、 缓存雪崩 (Cache Avalanche)
1. 什么是缓存雪崩?
缓存雪崩是指在某个时间段内,缓存集中地、大规模地失效,导致海量的请求绕过缓存,直接访问数据库,如同雪崩一般,给数据库带来毁灭性的压力,甚至导致其宕机。
缓存雪崩主要由两种情况引发:
- 大量 Key 同时过期:比如,我们在系统启动时为一批热点数据设置了相同的过期时间(例如 1 小时)。1 小时后,这些 Key 将在同一时刻集体失效,所有对这些 Key 的访问都会瞬间涌向数据库。
- Redis 实例宕机:如果 Redis 集群发生整体故障,无法提供服务,那么所有请求自然都会穿透到数据库。
2. 如何避免或减少缓存雪崩?
这是一个系统性的工程,需要从多个层面进行预防和加固:
- 过期时间随机化:为避免 Key 集体失效,可以在基础过期时间上增加一个随机值。例如,原本要设置 1 小时过期,可以改为
3600 + new Random().nextInt(600),让过期时间在 60-70 分钟内随机分布,从而分散失效压力。 - 设置永不过期:对于一些更新不频繁但访问量极大的热点数据(如首页配置),可以考虑不设置过期时间,而是通过后台任务进行异步更新。
- 构建高可用缓存集群:采用 Redis 的主从 + 哨兵(Sentinel)模式,或者 Redis Cluster 集群模式,确保在一个节点宕机时,能够自动进行故障转移,保障缓存服务的可用性。
- 开启持久化,快速恢复:开启 RDB 或 AOF 持久化,以便在 Redis 重启后能快速恢复数据,缩短缓存服务的不可用时间。
- 服务降级与限流:这是保护后端的最后一道防线。当检测到大量请求涌向数据库时,可以通过 Hystrix 或 Sentinel 等熔断降级组件,暂时关闭部分非核心功能(降级),或者对请求进行限流,只放行一部分请求到数据库,保证核心服务的稳定。
三、 缓存穿透 vs. 缓存击穿
缓存穿透和击穿是两个极易混淆的概念,它们都表现为请求穿透了缓存直达数据库,但其核心成因和场景截然不同。
1. 缓存穿透 (Cache Penetration)
- 核心特征:查询一个根本不存在的数据。
- 过程描述:请求首先访问 Redis,发现 Key 不存在;接着访问数据库,发现数据也不存在。由于缓存中永远不会有这个数据,导致每一次对这个不存在数据的查询,都会穿透到数据库。
- 典型场景:恶意攻击者使用大量不存在的 ID 来请求系统,导致数据库压力剧增。
- 一句话总结:本来无一物,两库(Redis 和 MySQL)都没有。

2. 缓存击穿 (Cache Breakdown)
- 核心特征:查询一个存在的数据,但这个数据是热点数据,并且在某一刻缓存正好过期了。
- 过程描述:一个被高并发访问的热点 Key,在它失效的瞬间,成百上千的并发请求同时涌入,由于此时缓存未命中,这些请求会一起冲向数据库进行查询,造成数据库压力瞬时飙升。
- 一句话总结:热点 Key 突然失效,导致请求暴打 MySQL。
3. 关键区别
- 数据是否存在:穿透是查不存在的数据;击穿是查存在的、刚刚过期的热点数据。
- 攻击范围:穿透通常是针对大量不同的、不存在的 Key;击穿是针对某一个具体的热点 Key。
四、 穿透与击穿的解决方案
1. 缓存穿透的解决方案
方案一:缓存空对象(或缺省值)
- 做法:当从数据库查询一个数据为空时,不要直接返回,而是在 Redis 中也缓存一个“空值”或约定的缺省值(如
null或""),并为这个空值设置一个较短的过期时间。 - 优点:实现简单,能有效阻止对同一个不存在 Key 的重复攻击。
- 缺点:会缓存一些无用的 Key,占用少量内存;如果攻击者使用大量不同的 Key,此方案效果会打折扣。同时,需要注意空值的过期时间设置,以防该数据后续被创建后,缓存无法及时更新。
- 做法:当从数据库查询一个数据为空时,不要直接返回,而是在 Redis 中也缓存一个“空值”或约定的缺省值(如
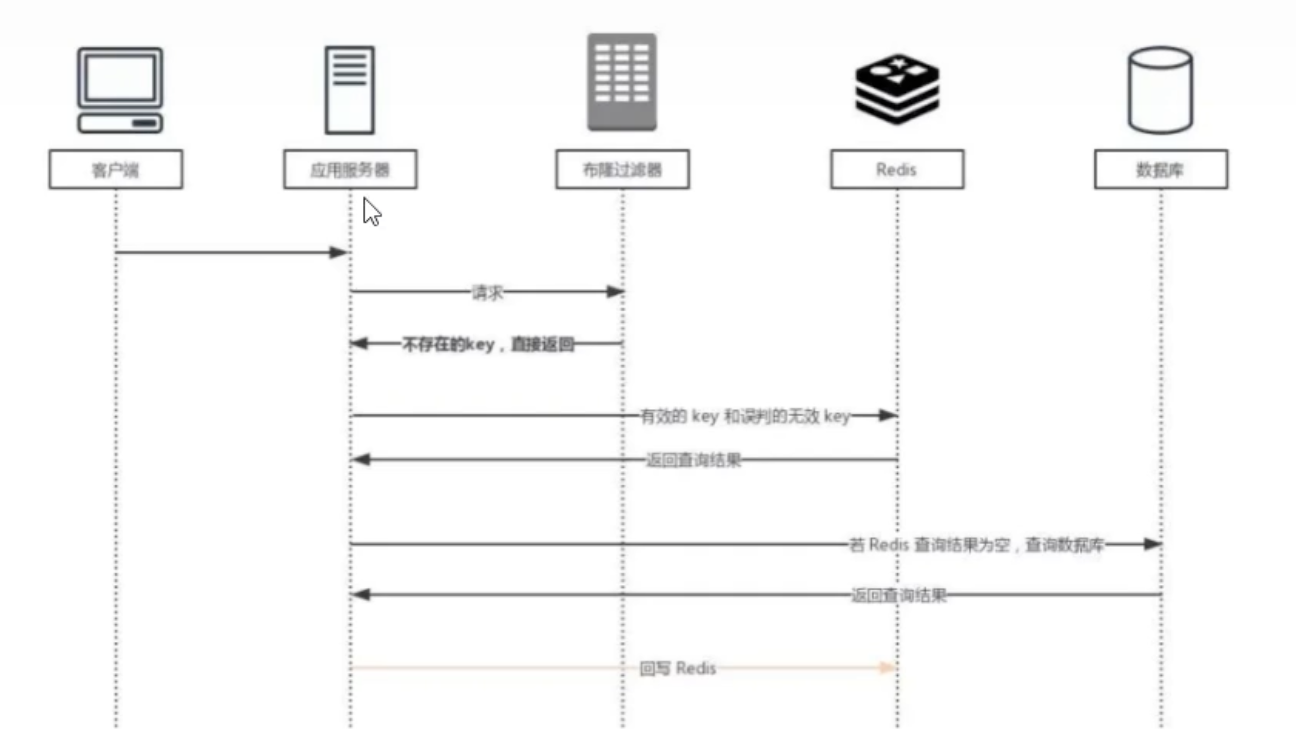
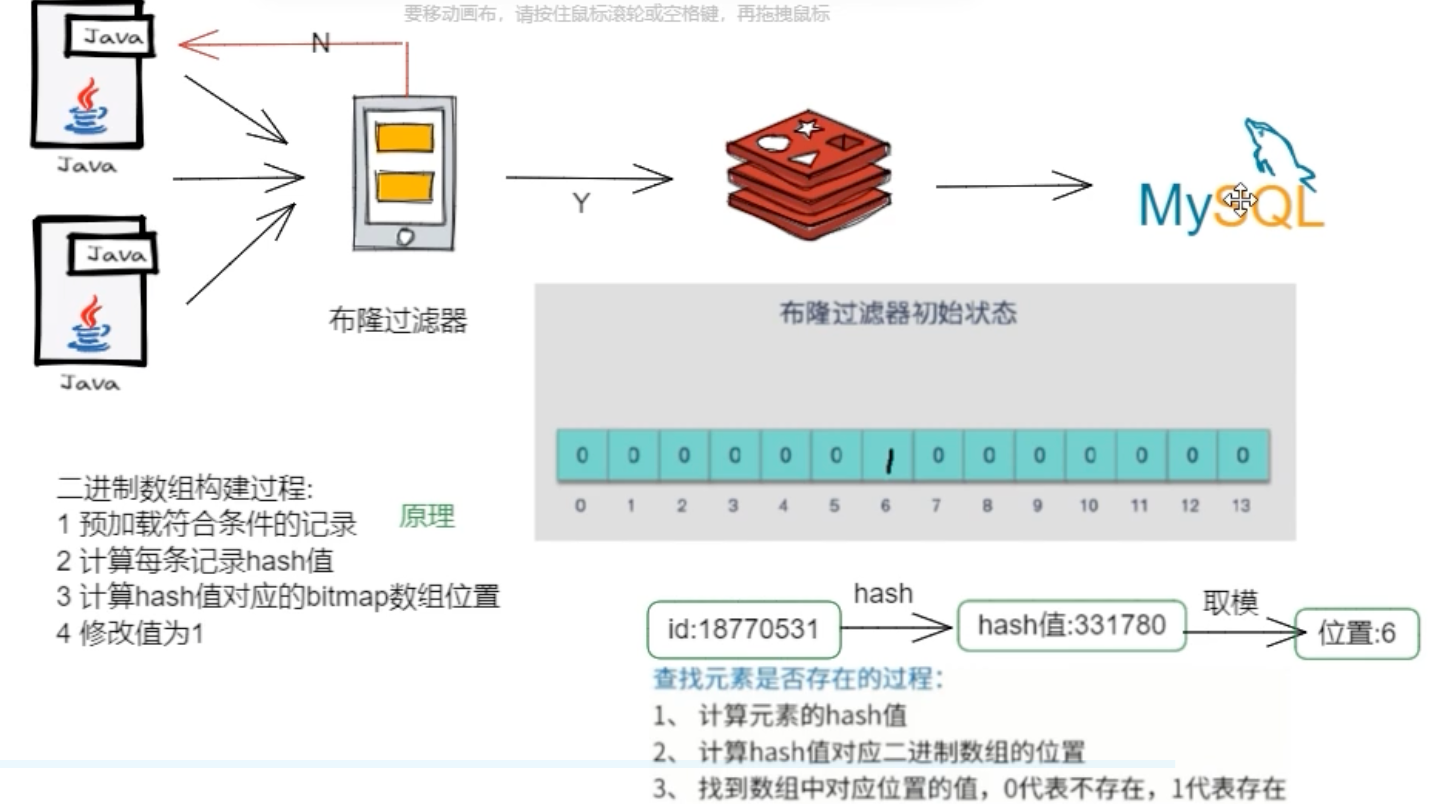
方案二:布隆过滤器 (Bloom Filter)
- 做法:将所有可能存在的数据哈希到一个足够大的位图中。一个查询请求过来时,先到布隆过滤器中查询这个 Key 是否存在。如果布隆过滤器判断不存在,那就直接拒绝请求,根本不会去查 Redis 和数据库。
- 优点:效率高,内存占用小,能从入口层拦截大量非法请求。
- 缺点:存在一定的误判率(它可能会认为一个不存在的 Key 存在),且不支持删除元素。
2. 缓存击穿的解决方案
方案一:热点数据永不过期
- 做法:对于访问极其频繁的热点 Key,不设置过期时间,由后台的定时任务或消息队列来异步地更新缓存。这从根本上避免了过期的问题。
方案二:互斥锁更新
- 做法:采用类似
Double-Checked Locking的思想。当一个线程发现缓存失效时,它先去获取一个分布式锁。只有获取到锁的线程,才有资格去查询数据库、回写缓存。其他未获取到锁的线程则等待一小段时间后重试,此时缓存可能已经被第一个线程写好了。 - 优点:严格保证了只有一个请求去查询数据库,避免了并发冲击。
- 缺点:实现相对复杂,会引入分布式锁的开销,并可能降低一些吞吐量。

- 做法:采用类似
五、 缓存不一致问题
缓存不一致是指缓存中的数据与数据库中的数据不一致。这通常发生在数据更新时。例如,更新了数据库,但更新或删除缓存的操作失败了。
修补方案
- 重试机制:将更新/删除缓存失败的操作放入消息队列(如 RabbitMQ),由消费者进行重试,保证最终操作成功。
- 订阅数据库变更日志:通过 Canal 等中间件订阅 MySQL 的 binlog。当数据库发生变更时,Canal 会捕获到变更信息并发送到消息队列,由专门的服务消费消息并精确地更新缓存。这是实现最终一致性的常用方案。
- 设置合理的过期时间:为所有缓存数据设置一个兜底的过期时间。即使出现不一致,缓存也会在过期后被淘汰,下一次查询会从数据库加载最新数据,从而实现自我修复。
总结
| 缓存问题 | 核心原因 | 常用解决方案 |
|---|---|---|
| 缓存预热 | 系统冷启动,缓存为空 | 项目启动时加载、定时任务刷新、手动脚本触发 |
| 缓存雪崩 | 大量 Key 同时失效 或 Redis 宕机 | 过期时间加随机值、构建高可用集群、服务降级与限流 |
| 缓存穿透 | 查询根本不存在的数据 | 缓存空对象、使用布隆过滤器 |
| 缓存击穿 | 单个热点 Key 在高并发下失效 | 互斥锁更新、热点数据不设置过期时间 |
| 缓存不一致 | 数据更新时,缓存操作失败 | 消息队列重试、订阅 Binlog、设置合理过期时间 |