操作系统启动流程简介
0. 两点说明
说明:
1.每一种操作系统的启动细节都不一样,
但是,不同的操作系统的大体启动流程都是差不多的。
2.真实的操作系统的启动流程非常的复杂,需要很多的前置知识的
只对一般操作系统的大体的启动流程做个简单的讲解
7 分钟阅读
3458 字
ReentrantReadWriteLock
在前面的文章中,我们深入探讨了 ReentrantLock,它是一个功能强大的独占锁。但在很多业务场景中,读操作的频率远远高于写操作。如果此时仍然使用 ReentrantLock,即使是多个读线程之间互不影响,它们也必须排队等待,这无疑大大降低了并发性能。
5 分钟阅读
2141 字
sychronized与锁升级
在高并发编程领域,线程安全是一个绕不开的话题。Java 通过 synchronized 关键字为我们提供了一种简单易用的内置锁机制,用于保证共享数据在多线程环境下的原子性、可见性和有序性。然而,凡事有利必有弊,锁在带来数据安全的同时,也可能成为性能的瓶颈。
19 分钟阅读
9283 字
Synchronized到底锁住了什么
前言:一条“强制”规范背后的深意
在 Java 高并发编程领域,线程安全是无法回避的核心命题。翻开《阿里巴巴 Java 开发手册》,在并发处理章节中有一条引人注目的强制性规范:
6 分钟阅读
2621 字
Redis 高可用基石:主从复制
随着业务量的增长,单台Redis实例很快会面临性能瓶颈和单点故障的风险。如何扩展Redis的读写能力?如何保证服务的高可用?答案就是主从复制 (Master-Slave Replication) 。
5 分钟阅读
2128 字
Redis 事务机制
在数据库领域,“事务”(Transaction)是一个可靠的词,它通常与ACID(原子性、一致性、隔离性、持久性)四大特性紧密绑定,是保证数据绝对可靠的基石。然而,当我们谈论Redis的事务时,会发现它是一个非常“另类”的存在。
4 分钟阅读
1993 字
Redis的IO多路复用解析
从根源出发,为何需要 I/O 多路复用?
引言:并发连接的挑战
在构建网络服务时,我们面临的第一个,也是最核心的挑战之一,就是如何同时处理大量的客户端连接。试想一下,一个热门的社交应用、一个繁忙的电商网站,或者像 Redis 这样的高性能缓存,它们在每一秒都需要应对成千上万的并发请求。
21 分钟阅读
10395 字
Redis的Hash数据结构
在Redis的五大经典数据类型中,Hash因其直观的field-value结构而备受青睐。然而,为了在性能和内存之间寻求极致的平衡,一个看似简单的Hash对象,其底层实现却暗藏玄机。Redis会根据存储数据的大小和数量,动态地为其选择不同的编码方式——在早期版本中是ziplist(压缩列表)和hashtable,而在Redis 7中,主角则换成了listpack(紧凑列表)。
17 分钟阅读
8504 字
Redis的String数据结构
在与 Redis 交互时,SET mykey "hello" 似乎是一个简单的字符串赋值操作。然而,为了将性能和内存效率推向极致,Redis 在这看似简单的操作背后,构建了一套精密而复杂的数据结构体系。本文将揭示其三种关键的物理编码——int、embstr 和 raw,并着重探讨 Redis 字符串的SDS。
6 分钟阅读
2999 字
Redis经典五大类型
从SET命令到redisObject的KV存储
当我们使用Redis时,一个简单的 SET mykey "hello" 命令就能瞬间完成。我们知道Redis是一个高性能的Key-Value数据库,但你是否曾深入思考过:这个简单的键值对,在Redis内部究竟是如何被组织和存储的?为什么它的Value可以是字符串、列表、哈希等多种复杂结构,却依然能保持O(1)的查询复杂度?
6 分钟阅读
2648 字
Redlock算法和底层源码分析
在分布式系统中,确保数据在并发访问下的一致性是一个永恒的挑战。分布式锁,作为实现互斥(Mutual Exclusion)的关键工具,是每个后端工程师都必须掌握的核心技能。Redis因其高性能和丰富的原子命令,成为了实现分布式锁的首选。然而,一个看似简单的SETNX,在复杂的分布式环境下却隐藏着诸多陷阱。
8 分钟阅读
3650 字
redis分布式锁
Redis远不止缓存
在深入分布式锁之前,让我们先快速浏览一下 Redis 在现代应用架构中扮演的多样化角色:
- 数据共享与会话管理 (Data Sharing & Session Management) :在分布式 Web 服务中,用户的 Session 信息需要被多个服务实例共享。Redis 作为内存数据库,提供了高速的读写能力,是实现分布式 Session 共享的理想选择。
- 计数器与排行榜 (Counters & Leaderboards) :利用 Redis 的原子性操作
INCR、DECR,可以轻松实现高并发场景下的计数功能,如文章阅读量、点赞数等。而其ZSET(有序集合) 数据结构,则能完美地应用于构建实时排行榜,如热搜榜、积分榜等。 - 消息队列 (Message Queue) :通过
LPUSH/RPOP(List) 或Streams数据类型,可以实现一个轻量级的消息队列,用于服务间的异步通信和任务解耦。 - 社交与推荐 (Social & Recommendations) :
SET(集合) 数据结构可以方便地处理用户关注、共同好友等关系。利用其交集、并集、差集运算,可以快速构建简单的推荐模型,如“可能认识的人”。 - 地理空间服务 (Geospatial) :Redis 的
GEO数据类型支持存储地理位置信息,并能进行距离计算、范围查找等操作,可用于实现“附近的人”或“附近的餐厅”等功能。 - 位统计 (Bitmaps) :通过位操作,可以高效地记录海量用户的状态信息,如用户签到、打卡等。这种方式极大地节省了内存空间。
- 全局ID生成 (Global ID Generation) :利用
INCR命令的原子性,可以生成全局唯一的序列号,作为分布式系统中的唯一标识符。
而今天要深入探讨的,是 Redis 在分布式协调方面的核心应用——分布式锁。
5 分钟阅读
2263 字
bitmap实现签到统计
在当今的互联网应用中,日活统计、用户签到、连续打卡等是极为常见的运营需求。如何为海量用户高效地记录和统计这些“是/否”状态?传统关系型数据库(如 MySQL)COUNT(*) 的方式在小体量下尚可应对,但面对亿级用户时,每天产生海量记录,将导致存储空间爆炸和查询性能急剧下降。
5 分钟阅读
2229 字
从抖音、淘宝面试题看Redis
亿级流量下的数据挑战:
在当今这个数据爆炸的时代,像抖音、淘宝、微博这样的平台,每天都要处理数以亿计的用户请求和数据。如何高效地收集、清洗、统计并展现这些海量数据,是衡量一个系统架构是否优秀的关键。这不仅是技术挑战,更是各大厂面试中频繁考察的核心能力。
11 分钟阅读
5109 字
Redis与MySQL的双写一致性
在现代应用架构中,缓存(如 Redis)与数据库(如 MySQL)的组合是提升性能的利器。我们最常用的模式是 Cache-Aside Pattern(旁路缓存) :
- 读请求:先读 Redis,命中则返回;未命中则读 MySQL,将结果写入 Redis 后再返回。
- 写请求:更新数据时,需要同时维护数据库和缓存中的状态。
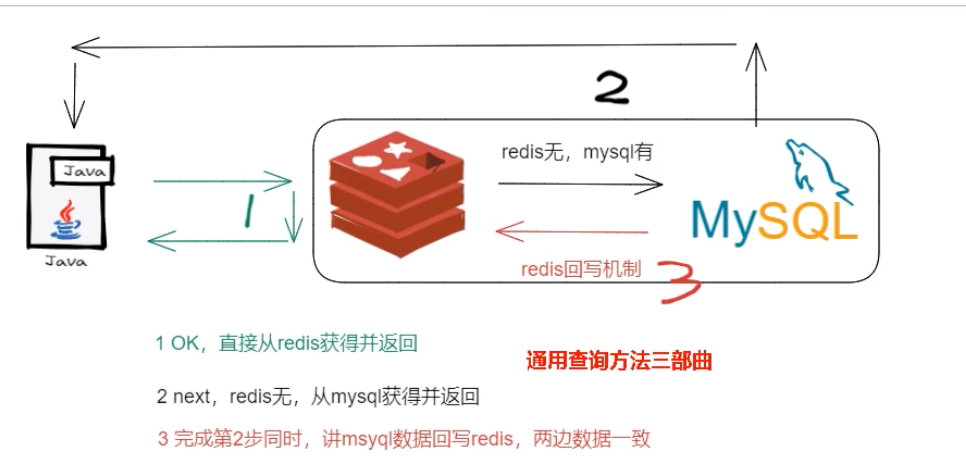
6 分钟阅读
2651 字
MoreKey 与 BigKey
在 Redis 的使用过程中,海量键(MoreKey)和过大键(BigKey)是两种常见但容易被忽视的性能杀手。它们会给 Redis 的稳定性、响应延迟和运维带来巨大挑战。本文将深入探讨这两类问题的成因、危害,并提供一套完整的发现、处理和规避方案。
8 分钟阅读
3595 字
redis单线程vs多线程
看完本文,将可以回答三个非常常见的redis面试题
- redis到底是单线程还是多线程?
- IO多路复用听说过吗?
- redis为什么快?
redis4.0之前部分支持多线程,异步删除,redis6.之后支持多线程io
10 分钟阅读
4984 字
ThreadPoolExecutor
为什么我们需要线程池?
我们通常这样创建一个线程来执行任务:
- 继承Thread
public class ThreadPoolExecutorDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
System.out.println("主线程结束");
}
static class MyThread extends Thread{
@Override
public void run() {
System.out.println("this is MyThread");
}
}
}- 实现Runnable
public class ThreadPoolExecutorDemo {
public static void main(String[] args) {
//1. 使用匿名内部类的写法
Thread t0 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("子线程t0");
}
});
t0.start();
//2. 使用lambda表达式的写法
Thread t1 = new Thread(()->{
System.out.println("这是子线程t1");
});
t1.start();
System.out.println("主线程结束");
}
}- 实现Callable
public class ThreadPoolExecutorDemo {
public static void main(String[] args) {
//把Callable对象传给FutureTask
FutureTask<String> futureTask = new FutureTask(new Callable() {
@Override
public Object call() throws Exception {
return "子线程futuretask";
}
});
Thread t3 = new Thread(futureTask);
t3.start();
//这里是个阻塞方法,会等待子线程返回result后,主线程才会继续执行
try {
String result = futureTask.get();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("主线程结束");
}
}
32 分钟阅读
15803 字
jvm
jvm
jvm的结构
程序计数器
当前线程所执行的字节码的行号指示器,记录下一条即将要执行的字节码指令的地址。 当执行引擎正在执行 bipush 10 时,程序计数器会自动保存下一条字节码指令 istore_1的地址。 因为真正的字节码指令存在元空间,通过这个地址就可以找到对应的字节码指令。
7 分钟阅读
3415 字
MySql
Sql基础
SQL数据库和NoSql的区别
SQL数据库 是关系型数据库,存储结构化数据于二维表 中,数据间通过预定义关系连接。NoSQL是 非关系型数据库,存储非结构化或半结构化数据,模型灵活多样(如文档、键值对),数据间关系弱 。
57 分钟阅读
28205 字